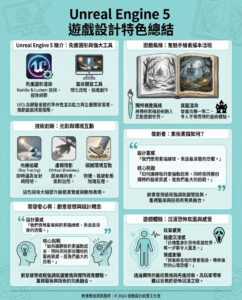
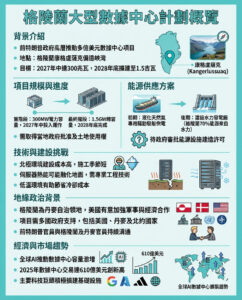
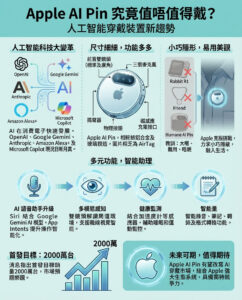
UALink推出最終規格,支持高達1,024個GPU,帶寬達200 GT/s
根據最新的報導,UALink的最終規格已經正式公布。UALink的主要目標是建立一個能夠與Nvidia的NVLink技術相抗衡的競爭性連接生態系統,這將使AMD、Broadcom、Google和Intel等公司能夠使用行業標準技術來開發AI加速器解決方案,從而降低成本。
在週二,超加速連結聯盟(Ultra Accelerator Link Consortium)正式發布了UALink 1.0的最終規格,這意味著該組織的成員可以開始實際芯片的設計和生產。這項新技術專注於AI和高性能計算(HPC)加速器,並且得到了包括AMD、Apple、Broadcom和Intel等眾多業界玩家的支持,預計將成為連接這類硬件的事實標準。
UALink 1.0規格詳情
UALink 1.0規格定義了一種高速、低延遲的連接技術,支持每個通道最高200 GT/s的雙向數據傳輸速率,並以212.5 GT/s的信號速率運行,以適應前向錯誤更正和編碼開銷。UALink可以配置為x1、x2或x4,四通道連接可以在發送和接收方向上達到800 GT/s。
每個UALink系統支持高達1,024個加速器(GPU或其他設備),這些加速器通過UALink交換機連接,每個加速器分配一個端口以及一個10位唯一識別碼,以實現精確路由。UALink電纜的長度優化為小於4米,實現小於1微秒的往返延遲,並支持64B/640B的有效載荷。該連接技術在一到四個機架之間提供確定性的性能。
協議棧和安全性
UALink協議棧包括四個針對硬件優化的層級:物理層、數據鏈路層、事務層和協議層。物理層使用標準以太網組件(例如,200GBASE-KR1/CR1),並進行了減少延遲的修改。數據鏈路層將來自事務層的64字節數據流打包成640字節單位,並應用CRC和可選的重試邏輯。這一層還處理設備間的消息傳遞,並支持UART風格的固件通信。
事務層實現了壓縮地址,簡化了數據傳輸,並在實際工作負載下達到高達95%的協議效率。它還支持加速器之間的直接內存操作,如讀取、寫入和原子事務,並保持本地和遠程內存空間的順序。
針對現代數據中心,UALink協議還支持集成的安全性和管理能力。例如,UALinkSec提供所有流量的硬件級加密和身份驗證,保護物理篡改並支持通過租戶控制的受信執行環境(如AMD SEV、Arm CCA和Intel TDX)進行的保密計算。該規格還允許虛擬Pod分區,通過交換機級配置將加速器組隔離在單一Pod內,以支持共享基礎設施上的並行多租戶工作負載。
未來展望
UALink Pods將通過專用的控制軟件和固件代理進行管理,使用標準接口如PCIe和以太網進行全管理性支持,並通過REST API、遙測、工作負載控制和故障隔離提供管理能力。
UALink聯盟的會長彼得·奧努弗里克表示:“隨著UALink 200G 1.0規格的發布,UALink聯盟的成員公司正在積極構建一個開放的加速器連接生態系統。我們期待看到各種解決方案即將進入市場,並促進未來的AI應用。”
目前,Nvidia在AI加速器市場中佔據主導地位,憑藉其強大的生態系統和擴展解決方案。目前,Nvidia正在交付使用NVLink連接的Blackwell NVL72機架,單個機架最多可以連接72個GPU,並且通過機架間的Pod可以在單個Pod中支持高達576個Blackwell B200 GPU。隨著明年即將推出的Vera Rubin平台,Nvidia計劃在單個機架中擴展到144個GPU,而Rubin Ultra計劃在2027年擴展到576個GPU。
從這一發展來看,UALink的推出無疑將對AI加速器市場的競爭格局產生深遠影響。隨著越來越多的公司加入這一生態系統,市場上將出現更多的選擇和創新,這對於推動AI技術的進一步發展至關重要。Nvidia雖然目前仍然佔據主導地位,但UALink的出現可能會促使該公司加快其技術創新,以維持其市場優勢。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。