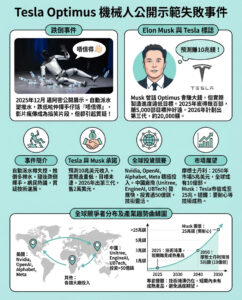
OpenAI在版權案件中獲得重大勝利……還是說並非如此?
在2023年,OpenAI首席執行官山姆·奧特曼(Sam Altman)和Alphabet首席執行官蘇達爾·皮查伊(Sundar Pichai)抵達白宮,與副總統卡馬拉·哈里斯(Kamala Harris)會面,討論人工智能的議題。最近,法律專家對於聯邦法官在11月7日駁回針對OpenAI的版權侵權訴訟的快速判斷表示,這一裁決可能會阻礙藝術家和作家們日益增長的努力,旨在防止人工智能公司竊取他們的內容。
紐約法官科琳·麥克馬洪(Colleen McMahon)於周四作出的裁決,無疑讓試圖提起此類案件的律師們感到失望。麥克馬洪不僅駁回了Raw Story Media針對OpenAI的訴訟,還削弱了內容創作者對人工智能公司提出的基本論點:即無差別地從互聯網上「抓取」數據來訓練人工智能模型,必然涉及未經許可的版權內容使用。
洛杉磯知識產權律師亞倫·莫斯(Aaron Moss)在其網站上寫道,麥克馬洪的裁決是基於一個無關案件的最高法院判決,這可能使人工智能的版權索賠處於不穩定的境地。法官不僅駁回了Raw Story的案件,還暗示沒有任何版權持有者能夠證明因人工智能抓取而受到的損害足以贏得侵權訴訟。
這是因為餵入OpenAI的ChatGPT等人工智能機器人的內容量巨大,以至於幾乎無法確定當機器人回應用戶查詢時,是否侵犯了任何特定內容。麥克馬洪表示:「考慮到信息的數量,ChatGPT輸出的內容與Raw Story的文章之間存在抄襲的可能性似乎微乎其微。」
這項裁決還可能削弱人工智能開發者日益增長的版權內容授權趨勢——部分原因是為了避免版權侵權索賠。道瓊斯公司(Dow Jones),即《華爾街日報》的母公司,已於5月與OpenAI達成了一項可能價值超過2.5億美元的授權協議。此後,OpenAI還與Axel Springer(《商業內幕》和《政治報》擁有者)、《金融時報》和美聯社達成了數百萬美元的授權交易。
加州創意媒體(Creative Media)主席彼得·查西(Peter Csathy)告訴我:「這個法庭正在剝奪Raw Story Media的這個蓬勃發展、利潤豐厚的授權內容市場。」
Raw Story在其訴訟中並未充分展示該市場的潛力。在其投訴中提到OpenAI與美聯社和Axel Springer達成的授權交易,但僅指出該人工智能公司「未向Raw Story提供任何補償」。
儘管如此,麥克馬洪的裁決的全面影響卻並不明朗。因為此案涉及兩個模糊的法律領域:以混亂著稱的版權法和可能還需數年才能形成一致的人工智能法。
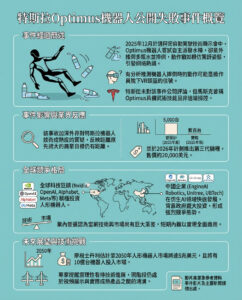
目前,至少有12起針對人工智能開發者的訴訟正在聯邦法院進行,原告包括《母親喬恩斯》(Mother Jones)、《華爾街日報》和《紐約時報》的出版商;音樂錄音行業;以及作家邁克爾·查邦(Michael Chabon)和莎拉·西爾弗曼(Sarah Silverman)。
這些案件的中級法院裁決相互矛盾,並提出了一些即使在高科技知識產權法中也未曾見過的問題。法官們甚至在定義版權侵權原則如何適用於不直接輸出版權作品的技術時都面臨困難,這些技術「模仿」了這些作品——就像道格拉斯·亞當斯(Douglas Adams)的《銀河便車指南》中飲料機所提供的「幾乎,但不完全,相似的茶」一樣。
所有這些案件仍處於早期階段。莫斯表示:「我不會太相信任何告訴你這些案件將如何結束的人。」
在進入這些訴訟試圖導航的法律泥潭之前,讓我們快速看看技術是如何開發的,以及為什麼版權問題成為焦點。
當前人工智能研究和開發的前沿模型並不具備自主思考的能力。它們是數十億篇文章、軟件代碼和人類創作的音樂或藝術的儲存庫。當被問及問題時,它們會在數據庫中搜尋,並嘗試從中綜合出最可能的答案。它們經常能給出正確的答案,但也經常出錯。
有時,它們的混淆程度足以產生明顯的錯誤,正如蘋果的研究人員在要求模型解決用普通英語寫成的數學問題時發現的那樣。有時,它們顯示出自己不知道自己不知道的事,並用虛構的內容填補知識的空白——或者如人工智能開發者所稱的「幻覺」。
正如麥克馬洪所觀察的,這些機器人所依賴的材料量和綜合過程使得任何答案完全複製任何特定內容的可能性不大。
這已成為某些原告在版權案件中的障礙。大多數聲稱其書面內容受到侵權的原告主要聲稱,某些人工智能模型已知的數據庫中包括了他們的書籍或其他著作(至少有一個人工智能開發者使用的內容庫中包括了我自己的三本書,但我並不是任何訴訟的當事方)。
《紐約時報》在其訴訟中引用了OpenAI的ChatGPT-4輸出的文本,該文本逐字復製了其文章的部分內容,且未經授權或標註來源。(作為OpenAI的投資者和其技術用戶,微軟被列為被告,對此回應稱《紐約時報》有效地「引導」了聊天機器人復製其文本,因為巧妙地設計了查詢以引出侵權答案。)
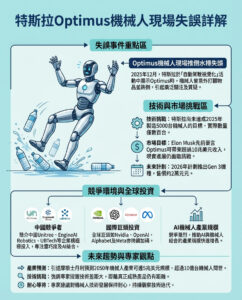
這使我們回到了Raw Story Media的訴訟。該公司運營著Raw Story和AlterNet新聞網站,並未將其索賠構建為版權侵權投訴。相反,他們主張OpenAI故意從其導入的文章中刪除了作者、標題和版權標籤——統稱為版權管理信息(CMI)。
Raw Story辯稱,這一過程促進了未來的侵權行為,因為用戶無法意識到他們正在接收,並可能分發未經許可的版權材料。
故意刪除CMI以促進版權違規行為,直接違反了1998年《數字千年版權法》(Digital Millennium Copyright Act),該法規範數字內容製作人的知識產權。Raw Story尋求OpenAI對該法律違規的賠償和要求該人工智能公司從其數據庫中刪除所有已刪除CMI的Raw Story內容的禁令。
這就是Raw Story遭遇的障礙,由於最高法院的判決而設置的障礙。在2021年涉及信用局TransUnion的5-4裁決中,最高法院宣佈,原告僅僅因被告違反聯邦法規而提起訴訟是不夠的。為了有資格提起聯邦案件,原告必須證明自己因違規行為遭受了「具體損害」。
Raw Story無法證明這一點,因為無法提供其內容在用戶查詢中的回答中被複製的證據,因此未能證明其遭受了「具體損害」。因此,麥克馬洪以Raw Story不具備提起訴訟的資格為由駁回了該訴訟。
事實上,麥克馬洪似乎對Raw Story試圖耍小聰明的想法感到不悅。她寫道:「讓我們明確一下真正的利害關係。」她指出,Raw Story尋求救濟的所謂損害,「不是OpenAI數據庫中CMI的排除,而是「原告的文章在未補償的情況下被用於開發ChatGPT。」
麥克馬洪給了Raw Story重新提交訴訟的機會,以證明其因OpenAI的行為而受到損害。她並不樂觀,稱自己對該公司能否提出「可識別的損害」持懷疑態度。
但查西認為,麥克馬洪忽視了她的裁決可能削弱授權市場的可能性——如果人工智能開發者能夠肆意刪除訓練數據中的CMI,那麼他們將不再感覺有必要未來授權版權材料。「這裡有一些真正可觀的金錢,」他說。
如果Raw Story在未來提交修正投訴時引用授權收入的損失作為「可識別的損害」,那將成為這一領域的又一新變數,而目前這一領域幾乎全是變數。
這一裁決無疑引發了對人工智能技術和版權之間微妙平衡的反思。如果未來的法律環境無法有效保護創作者的權益,這可能會對創意產業造成長遠的影響。隨著技術的進步,如何制定合理的法律框架以保障創作者和技術開發者的雙方權益,將是未來需要重點關注的課題。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。