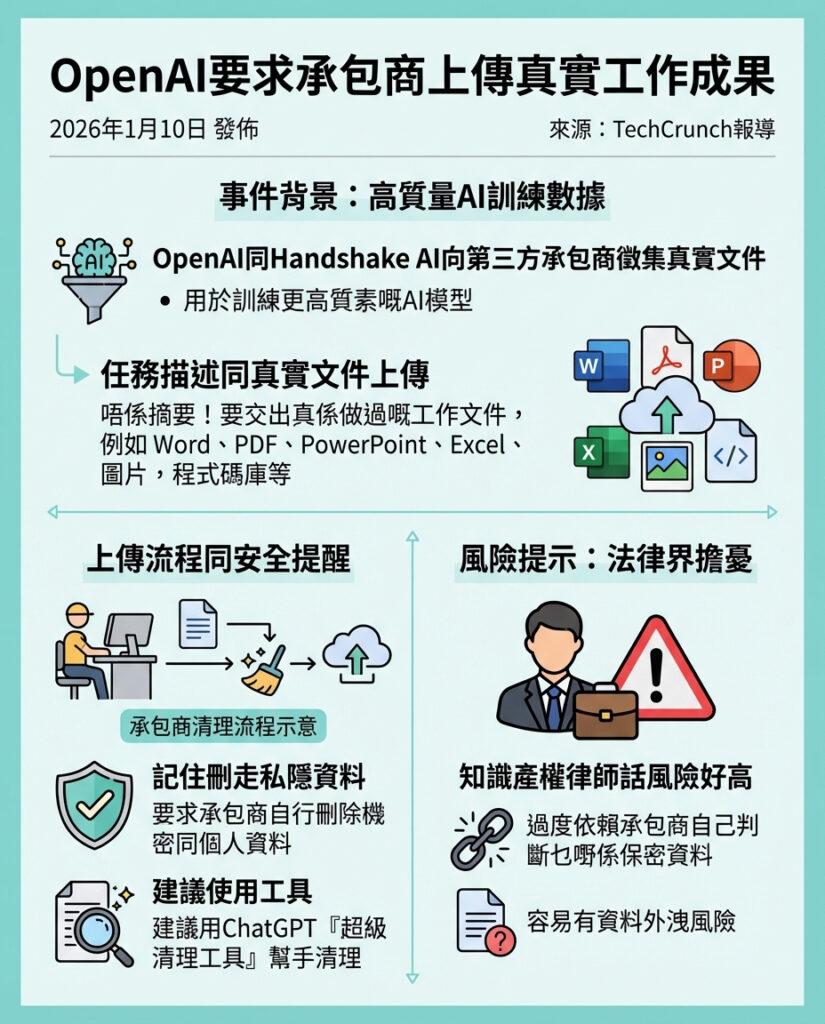
OpenAI傳要求合約員工上載過往工作真實作品
根據《Wired》報道,OpenAI連同其訓練數據合作夥伴Handshake AI,現正要求第三方合約員工上載他們過去及現時工作中所完成的真實工作成果。這似乎是AI公司普遍採用的一種策略,透過聘請合約人員產生高質素的訓練數據,期望將來可以令AI模型自動化更多白領工作。
據悉,OpenAI一份內部簡報中要求合約員工描述他們曾於其他工作中執行過的任務,並上載「實際完成過的真實工作」,包括具體文件,例如Word文檔、PDF、PowerPoint、Excel、圖片或程式碼庫等,而非簡單的文件摘要。公司同時指示員工在上載前,需刪除任何專有及個人識別資料,並提供一款名為ChatGPT「Superstar Scrubbing」的工具協助清理敏感信息。
不過,知識產權律師Evan Brown向《Wired》表示,任何AI實驗室採用此類做法,都在「冒著極大風險」,因為這種方式高度依賴合約員工自行判斷哪些資料屬於機密,存在信任漏洞。
OpenAI發言人拒絕對此事置評。
—
評論與啟示
OpenAI要求合約人員上載真實工作檔案的舉措,反映出AI訓練數據需求的急迫與複雜性。這種「實戰數據」有助提升模型對日常工作任務的理解和處理能力,理論上能推動AI在專業領域的應用更為精準及實用。然而,這種做法同時帶來不少法律和倫理風險。
首先,合約員工是否完全理解且能妥善處理機密資料,始終存在變數。即使有工具輔助清理,仍難保證不會有敏感信息外洩。其次,這種做法是否侵犯了原本工作的知識產權,尤其是涉及企業機密或個人隱私,業界和監管機構可能會高度關注。
更深層次來說,這反映出當前AI發展與數據倫理間的矛盾:為了推動技術進步,企業不惜冒險使用真實且可能敏感的數據,但這種「先行試探」式的策略可能種下未來法律糾紛和公眾信任危機。OpenAI作為業界領頭羊,應在數據使用透明度和保護措施上更為嚴謹,避免因短期利益損害長遠聲譽。
從香港及全球視野看,這提醒我們在推動AI技術應用時,必須同時加強法律框架和數據保護機制,確保科技發展不逾越倫理紅線,並保障用戶及相關方權益。未來AI公司若能在數據來源合規、透明及尊重知識產權方面設立更高標準,或能成為業界的良好示範,促進技術與社會責任的平衡發展。
以上文章由GPT 所翻譯及撰寫。而圖片則由GEMINI根據內容自動生成。