Nvidia全新Rubin平台或將永遠改變AI運算未來
在2026年CES展會上,Nvidia發佈了全新的AI超級運算平台——Rubin,目標是推動大型語言模型(LLM)在大眾中的普及與應用。
近年來,Nvidia憑藉生成式AI的熱潮,硬件需求急劇上升,尤其是其圖形處理器(GPU)成為訓練大型語言模型的標配。於2026年CES期間,Nvidia舉行了新聞發佈會,正式介紹Rubin平台這一AI領域的最新突破。
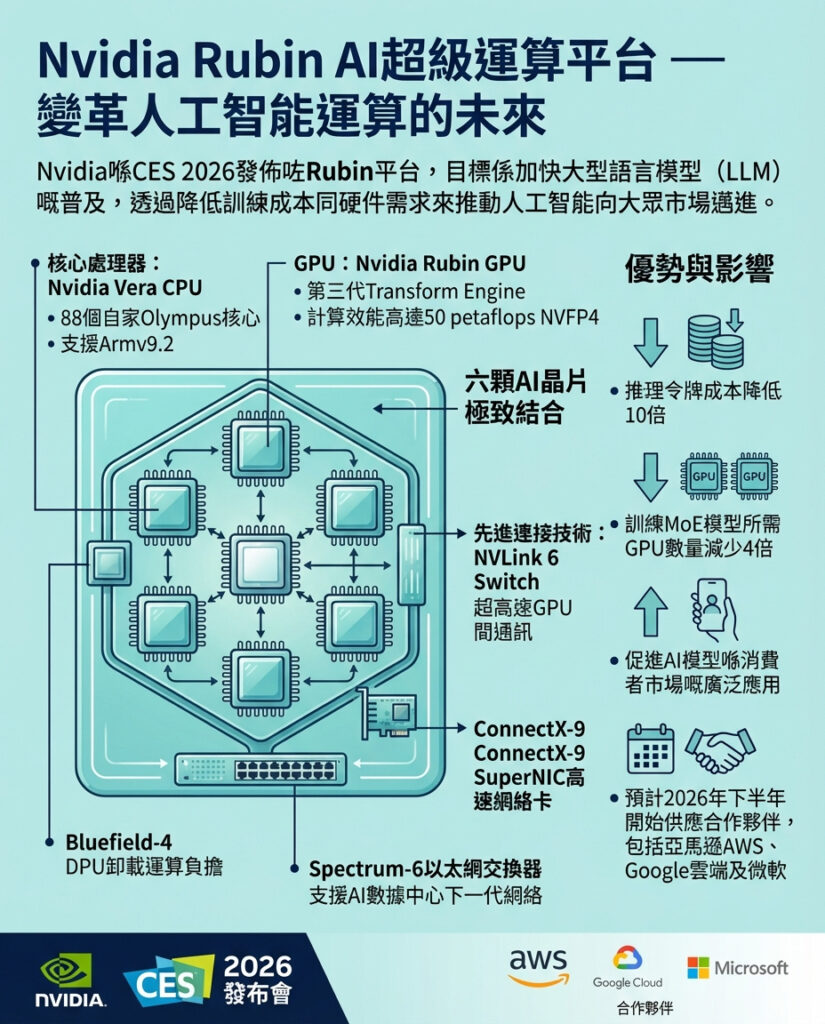
Rubin是一個專為「以最低成本打造、部署及保護全球最大最先進AI系統」而設計的超級運算平台。Nvidia指出,該平台在推理階段的token成本可降低至原來的十分之一,且在訓練混合專家模型(MoE)時所需GPU數量比舊款Blackwell平台少四倍。
簡單來說,Rubin可以被視為Blackwell的升級強化版,規模和性能均大幅提升。
Rubin的核心目標是加快先進AI模型在消費者市場的普及。過去LLM大規模應用的最大阻礙之一,就是昂貴的硬件和基礎設施成本。Rubin通過大幅降低token成本,令大規模AI部署變得更為實際和可行。
Nvidia採用了「極致協同設計」理念,打造由六顆集成晶片組成的AI超級運算機。中心是Nvidia Vera CPU,這是一款為大規模AI工廠打造的節能處理器,配備88個自家設計的Olympus核心,支援完整Armv9.2架構,並且擁有高速NVLink-C2C互連技術。
搭配的是Nvidia Rubin GPU,作為平台的主要運算引擎,內建第三代Transform Engine,最高可提供50 petaflops的NVFP4計算能力。連接各部分的Nvidia NVLink 6交換器,實現GPU間的超高速通訊。網絡部分由ConnectX-9 SuperNIC和Bluefield-4 DPU協同負擔工作,讓CPU與GPU能更專注於AI模型運算。最後,Spectrum-6乙太網交換器為AI數據中心提供下一代網絡方案。
Rubin將有多種配置可選,例如Nvidia Vera Rubin NVL72,內含36顆Vera CPU、72顆Rubin GPU、NVLink 6交換器、多個ConnectX-9 SuperNIC與BlueField-4 DPU。
不過,這類超級運算平台暫時不會直接面向普通消費者銷售。Nvidia表示,首批Rubin平台將於2026年下半年交付合作夥伴,其中包括亞馬遜AWS、谷歌雲和微軟等巨頭。如果成功,Rubin有望開啟一個規模更易控管的AI運算新時代。
—
評論與啟示:
Nvidia Rubin平台的推出,代表著AI運算硬件正邁入一個更高效、低成本的階段。過去大型語言模型的普及受限於龐大成本與高能耗,Rubin通過硬件和架構的深度整合,成功降低運算代價,有望使先進AI技術更快滲透至消費者和企業市場。
這種「極致協同設計」的理念,既是硬件技術的革新,也是AI產業生態系統進化的關鍵。它不僅意味著硬件效率的提升,更可能促進更多創新應用的誕生,從智能助理到自動駕駛,再到個性化醫療與教育。
然而,這也提醒我們,AI技術的快速發展同時帶來資源集中化的風險。當少數大型雲端供應商掌握這類超級運算平台,可能加劇市場的壟斷與不均,對於中小企業和開發者來說,如何公平獲取運算資源仍是挑戰。
總結來說,Rubin不僅是Nvidia在硬件上的一次突破,更是AI普及化路上的重要里程碑。未來,如何在推動技術進步的同時,兼顧生態多元與公平,將是整個產業需要共同面對的課題。
以上文章由GPT 所翻譯及撰寫。而圖片則由GEMINI根據內容自動生成。