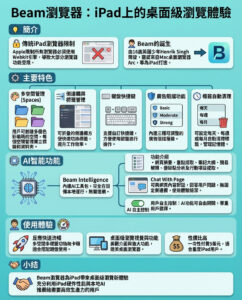
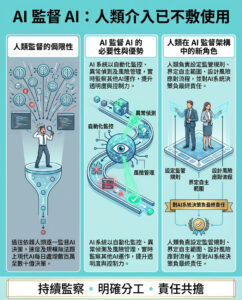
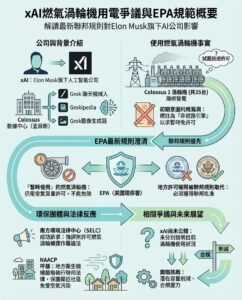
如何Nvidia在十年的人工智能時代創造1.4兆美元的數據中心市場
千億美元的轉型正在展開
我們正見證一個全新計算時代的興起。在未來十年,超過一兆美元的數據中心業務即將轉型,這一切都得益於我們所稱的「極端並行計算」(Extreme Parallel Computing,簡稱EPC),或一些人所稱的加速計算。雖然人工智能是主要的推動力,但其影響波及整個技術堆棧。
Nvidia公司位於這一轉型的最前沿,打造了一個整合硬件、軟件、系統工程及龐大生態系統的端到端平台。我們認為,Nvidia擁有10到20年的時間來推動這一轉型,但市場力量的影響遠超過單一參與者。這一新範式是從根本上重新構想計算:從晶片層面到數據中心設備,再到大規模分佈式計算、數據和應用堆棧,以及邊緣的先進機器人技術。
在這篇深入分析中,我們將探討極端並行計算如何重塑技術格局,主要半導體公司的表現,Nvidia面臨的競爭,其防護壕的深度,以及其軟件堆棧如何鞏固其領導地位。我們還將探討來自CES的一項最新發展——所謂的「AI電腦」的出現,並提供來自企業技術研究的數據。最後,我們將討論數據中心市場如何在2035年前達到1.7兆美元,以及威脅這一積極情景的潛在風險。
為極端並行計算優化技術堆棧
我們的研究顯示,技術堆棧的每一層——從計算到存儲,再到網絡和軟件層——都將為AI驅動的工作負載和極端並行性重新架構。我們相信,從通用的x86中央處理單元向分佈式圖形處理單元和專用加速器的過渡,正比許多人預期的更快。以下是我們對數據中心技術堆棧幾個層次的簡要評估及其對EPC的影響。
計算
三十多年來,x86架構主導了計算。如今,通用處理正在讓位於專用加速器。GPU是這一變化的核心。AI工作負載如大型語言模型、自然語言處理、高級分析和實時推斷需要巨大的並發能力。
極端並行性:傳統的多核擴展已經達到邊際效益遞減。相比之下,一個GPU可以包含數千個核心。即使在包裝層面上GPU的價格更高,但在計算單位成本上,由於其大規模的並行設計,實際上可能更便宜。
AI的大規模應用:高度並行的處理器需要先進的系統設計。大型GPU集群共享高帶寬內存(HBM),並需要快速互連(如InfiniBand或超快速以太網)。GPU、高速網絡和專用軟件之間的協同作用正在支持新類型的工作負載。
存儲
儘管在AI討論中存儲經常被忽視,但數據是驅動神經網絡的燃料。我們認為,AI需要先進的高性能存儲解決方案:
預測數據暫存:下一代數據系統能夠預測模型將請求的數據,確保數據提前存放在處理器附近,以減少延遲並儘可能解決物理限制。
分佈式文件和物件存儲:PB級的容量將成為常態,元數據驅動的智能將在節點之間協調數據放置。
性能層:NVMe SSD、全閃存陣列和高吞吐量數據結構在保持GPU和加速器數據飽和方面發揮著重要作用。
網絡
在過去十年,由於移動和雲的發展,我們看到網絡流量從北南方向(用戶到數據中心)轉向東西方向(伺服器到伺服器)。AI驅動的工作負載在數據中心內部和網絡之間造成了大量的東西方向和北南方向的流量。在高性能計算(HPC)領域,InfiniBand成為超低延遲互連的首選。現在,我們看到這一趨勢滲透到超大規模數據中心中,高性能以太網成為主導標準,這最終將成為我們認為的主要開放網絡選擇:
超大規模網絡:超高帶寬和超低延遲的結構將促進AI集群所需的並行操作。
多方向流量:曾經以北南流量為主,最近則轉向東西流量,先進的AI工作負載現在可以在每個方向上生成流量。
軟件堆棧和工具
操作系統和系統層軟件
加速計算對操作系統、中間件、庫、編譯器和應用框架提出了巨大的需求。這些必須調整以利用GPU資源。隨著開發者創建更先進的應用——一些應用橋接實時分析和歷史數據——系統層軟件必須以空前的水平管理並發。操作系統、中間件、工具、庫和編譯器正在迅速演變,以支持超並行工作負載,並能夠利用GPU(即GPU感知的操作系統)。
數據層
數據是AI的燃料,數據堆棧正迅速被智能化。我們看到數據層從歷史分析系統轉向支持實時數位表示的引擎,這些表示涵蓋人、地點和事物以及過程。為了支持這一願景,數據協調將通過知識圖、統一元數據庫、代理控制框架、統一治理和與運營及分析系統的連接來實現。
應用層
智能應用正在出現,統一和協調數據。這些應用越來越多地能夠實時訪問商業邏輯以及流程知識。單一代理系統正在發展為多代理架構,能夠從人類的推理痕跡中學習。應用越來越能理解人類語言,注入智能(換句話說,AI無處不在),並支持工作流的自動化和創造商業結果的新方式。應用越來越成為物理世界的延伸,幾乎所有行業都有機會創建實時代表商業的數位雙胞胎。
關鍵要點:極端並行計算代表了對技術堆棧的全面重新思考——計算、存儲、網絡,尤其是操作系統層。它將GPU和其他加速器置於架構設計的核心。
半導體股票表現:五年視角
以上圖形顯示了主要半導體公司五年的股票表現,自2022年底「AI區域」開始——大約與ChatGPT的首次熱潮相吻合。在那段時間之前,許多人對大規模GPU加速的AI能否成為強大的商業驅動因素表示懷疑。
Nvidia:在AI熱潮中脫穎而出,成為全球最有價值的上市公司。
Broadcom:我們的數據繼續支持Broadcom作為硅中的下一個強勁AI選擇,特別是在數據中心基礎設施方面。它為雲巨頭提供關鍵的IP,用於定制ASIC和下一代網絡,包括谷歌、Meta和字節跳動。
AMD:在x86市場上超越Intel,但該領域正在衰退,因此Advanced Micro Devices正加速進軍AI。我們看到AMD試圖複製其成功的x86策略——這次對抗Nvidia的GPU。Nvidia的競爭護城河及其軟件堆棧將讓AMD難以打破,除非Nvidia出現重大失誤。
Intel:Intel的代工策略仍然是主要的阻力。根據我們對Intel的代工計劃的分析,我們認為其產能不足以追趕台灣半導體製造公司,因資本限制的增加。我们相信Intel将被迫在今年剥离其代工业务,这将使我们对Intel强大的设计业务更乐观,帮助公司重新解锁创新,成为一个可行的AI参与者。
Qualcomm:仍然主要集中在移动、边缘和设备中心的AI上。尽管对Nvidia在数据中心的威胁不大,但Qualcomm未来在机器人和分布式边缘AI的扩展可能会引发这些参与者之间的偶尔竞争。
在我們看來,市場已經意識到半導體是未來AI能力的基礎,並給予能夠捕捉加速計算需求的公司以溢價估值。今年,「有」的公司(以Nvidia、Broadcom和AMD為首)表現優異,而「沒有」的公司(特別是Intel)則落後。
競爭格局:Nvidia及其競爭者
Nvidia的65%營業利潤吸引了投資者和競爭對手紛紛進入AI芯片市場。無論是老牌公司還是新進者,都積極應對。然而,市場潛力如此龐大,而Nvidia的領先地位又如此穩固,我們認為近期的競爭不會對Nvidia造成傷害。儘管如此,我們看到Nvidia的挑戰者有多種角度,每個都有自己的市場策略。
Broadcom和Google
我們將這兩個領導者聯繫起來,因為:1)Broadcom為谷歌的張量處理單元(TPU)提供定制芯片;2)我們相信TPU v4在AI領域競爭力極強。Broadcom在SerDes、光學和網絡方面的IP都是業界最佳,與Google共同構成了相對於Nvidia最可行的技術替代方案。
潛在的市場機會:一個長期的場景是,Google最終可能會更積極地商業化TPU,從純內部解決方案轉向更廣泛的市場產品。但在短期內,圍繞Google的TPU生態系統仍然是封閉的,限制了其採用範圍。
Broadcom和Meta
值得注意的是,Broadcom與Meta有著長期的合作關係,為其AI芯片提供支持。谷歌和Meta都證明了消費者廣告中的AI投資回報是有利可圖的。儘管許多企業在AI的投資回報上掙扎,但這兩家公司卻展示了令人印象深刻的資本回報。
谷歌和Meta都在推動以太網作為網絡標準。Broadcom是以太網的強大支持者,也是超以太網聯盟中的主要聲音。此外,Broadcom是除了Nvidia之外唯一擁有跨XPUs及XPU集群網絡證明專業知識的公司,這使得該公司在AI硅市場中成為一個極具競爭力的對手。
AMD
AMD的數據中心策略依賴於提供具有競爭力的AI加速器——基於該公司在x86市場的成功記錄。儘管它在遊戲和高性能計算領域擁有強大的GPU市場,但AI軟件生態系統(以CUDA為中心)仍然是一個主要障礙。
兩個角度:一些人認為AMD將在AI領域獲得顯著的市場份額,至少足以維持收入增長。另一些人則預見只有適度的增長,因為AMD必須匹配Nvidia的硬件和軟件堆棧、系統專業知識及開發者忠誠度。
AMD在AI領域已經做出積極的舉措。它正在與Intel合作,試圖保持x86的可行性。它收購了ZT Systems,以更好地了解端到端AI系統需求,並將成為推特硅的可行替代品,特別是在推斷工作負載方面。最終,我們認為AMD將在這一龐大市場中占有相對較小的份額(單位數字)。它將通過獲取Intel的市場份額來管理x86市場的衰退,並在對成本敏感的AI芯片市場中與Nvidia展開競爭。
Intel
曾經是處理器的無可爭議的領導者,Intel的命運在加速計算的轉型中發生了變化。我們繼續認為,Intel受到保留自身代工業務的巨大資本需求的阻礙。
垂直整合與規模:對於像Apple、Nvidia、Oracle和Tesla這樣的公司,垂直整合可以帶來優勢,因為它們在單一系統中結合了硬件和軟件。但在Intel的情況下,我們認為代工業務正在消耗關鍵資源和管理注意力。Intel面臨進一步損害的風險,如果今年不剝離其代工業務。
可能的結果:我們普遍認為Intel應該剝離其代工業務,重新專注於設計和合作夥伴關係,類似於AMD剝離其晶圓廠業務的方式。另一種情境是,Intel繼續投資,最終重新獲得製程領導地位,直接競爭。然而,我們認為這種結果的概率極低(我們認為低於5%)。
AWS和Marvell:Trainium和Inferentia
亞馬遜的定制硅策略在CPU實例中隨Graviton而成功。其收購Annapurna Labs是企業技術史上最好的投資之一,無疑也是經常被忽視的。如今,AWS與Marvell合作,並將Graviton式的策略應用於GPU,推出Trainium(用於訓練)和Inferentia(用於推斷)。
Dylan Patel對亞馬遜GPU的看法在我們看來總結得很好。他在BG2播客的一期節目中說:
「亞馬遜,他們在re:Invent的整個重點,如果你真的和他們交談,當他們宣布Trainium 2時,我們對其整體分析是供應鏈方面……你眯起眼睛,這看起來像是亞馬遜基礎版TPU,對吧?它還不錯,但它真的便宜,A;而B,它為每美元提供了市場上最多的HBM容量和HBM內存帶寬。因此,對某些應用來說,它實際上是有意義的。因此,這是一個真正的轉變:嘿,我們也許無法像Nvidia那樣設計得那麼好,但我們可以在包裝上放更多的內存。」
我們認為,AWS的產品將是成本優化的,並在AWS生態系統內提供一種替代的GPU方法,用於訓練和推斷。儘管開發者最終可能更喜歡Nvidia平台的熟悉性和性能,AWS將為客戶提供盡可能多的可行選擇,並在其擁有的市場中獲得合理的份額。可能不會像Graviton那樣在商業x86硅上獲得相同的滲透率,但足以證明其投資的合理性。目前我們對Trainium沒有具體預測,但這是一個我們正在觀察的領域,以獲得更好的數據。
關鍵要點
價值與性能:某些工作負載不需要Nvidia的高端能力,這些工作負載可能會轉向更低成本的AWS硅。同時,Nvidia堆棧將仍然是複雜、大規模部署和開發者便利性的首選。
AWS後端基礎設施——我們在re:Invent的研究顯示,AWS多年來一直在構建自己的AI基礎設施,以減少對Nvidia整個堆棧的依賴。與許多需要Nvidia端到端系統的公司不同,雖然AWS可以為客戶提供這樣的解決方案,但它也能提供自己的網絡和支持軟件基礎設施,進一步降低客戶的成本,同時提高自身的利潤。
微軟和高通
微軟在定制硅方面歷史上落後於AWS和谷歌,儘管它確實有正在進行的項目,如Maia。微軟可以通過其軟件優勢和願意為高端GPU支付Nvidia的利潤來彌補任何硅差距。高通是微軟客戶設備的關鍵供應商。高通,如前所述,在移動和邊緣領域競爭,但隨著機器人和分佈式AI應用的擴展,我們看到與Nvidia之間可能發生更直接的衝突。
新興替代方案
Cerebras Systems、SambaNova Systems、Tenstorrent和Graphcore等公司推出了專門的AI架構。中國也在開發本土的GPU或類似GPU的加速器。然而,統一的挑戰仍然是軟件兼容性、開發者動力和取代事實標準的艱難攀登。
關鍵要點:雖然競爭激烈,但這些參與者單獨並不威脅Nvidia的長期主導地位——除非Nvidia出現重大失誤。市場規模如此龐大,以至於多個贏家可以蓬勃發展。
Nvidia的護城河:硬件、軟件和生態系統
我們認為,Nvidia的競爭優勢是一種多方面的護城河,涵蓋硬件和軟件。經過近二十年的系統性創新,Nvidia產生了一個廣泛而深入的集成生態系統。
硬件集成和「全牛」策略
Nvidia的GPU採用先進的工藝節點,包括HBM內存集成和專門的張量核心,這些都能顯著提高AI性能。值得注意的是,Nvidia每12到18個月就能推出一款新的GPU版本。與此同時,Nvidia採用「全牛」方法——確保每一個可回收的晶圓都能在其產品組合中佔有一席之地(數據中心、PC GPU或汽車)。這樣能保持高產量和健康的利潤。
網絡優勢
收購Mellanox Technologies使Nvidia控制了InfiniBand,讓其能夠為AI集群銷售全面的端到端系統,並迅速進入市場。ConnectX和BlueField DPU的整合延伸了Nvidia在超快速網絡方面的領導地位,這對於多GPU擴展至關重要。隨著行業向超以太網標準發展,許多人認為這對Nvidia的護城河構成威脅。但我們並不這麼認為。雖然網絡是Nvidia市場時間優勢的關鍵組成部分,我們認為這是其產品組合的輔助成員。在我們看來,該公司能夠並將成功根據市場需求優化其以太網堆棧,並保持其核心優勢,這來自於其堆棧的緊密整合。
軟件整合和平台方法
Nvidia的軟件生態系統已經超越了CUDA,涵蓋了幾乎每個AI應用開發階段的框架。最終結果是,開發者有更多理由留在Nvidia的生態系統中,而不是尋求替代方案。
生態系統和夥伴關係
Nvidia的首席執行官Jensen Huang經常強調公司對建立夥伴網絡的重視。幾乎每個主要的技術供應商和雲服務提供商都提供基於Nvidia的實例或解決方案。這種廣泛的足跡產生了顯著的網絡效應,進一步強化了護城河。
關鍵要點:Nvidia的優勢不僅僅依賴於芯片。其硬件和軟件的整合——建立在龐大的生態系統基礎上——形成了一道難以複製的堡壘般的護城河。
深入瞭解Nvidia的軟件堆棧
CUDA無疑主導了軟件討論,但Nvidia的堆棧是廣泛的。以下是六個重要層次的概述:CUDA、NVMI/NVSM(這裡稱為「NIMS」)、NeMo、Omniverse、Cosmos和Nvidia的開發者庫/工具包。
CUDA
計算統一設備架構(Compute Unified Device Architecture,CUDA)是Nvidia的基礎並行計算平台。它抽象了GPU硬件的複雜性,使開發者能夠使用C/C++、Fortran、Python等語言編寫應用。CUDA協調GPU核心並優化工作負載調度,以加速AI、高性能計算、圖形等。
NIMS(Nvidia管理接口系統)
NIMS專注於基礎設施級別的管理:監控、診斷、工作負載調度和大型GPU集群的整體硬件健康。儘管不嚴格是「開發者工具」,但對任何需要在數千個GPU上運行先進AI工作負載的企業來說,都是至關重要的。
NeMo
NeMo是一個端到端框架,用於開發和微調大型語言模型和自然語言應用。它提供預先構建的模塊、預訓練模型,並提供將這些模型匯出到其他Nvidia產品的工具,幫助企業加速利用自然語言處理和大型語言模型的洞察。
Omniverse
Omniverse是用於3D設計協作、模擬和實時可視化的平台。雖然最初展示用於設計工程和媒體,但Omniverse現在擴展到機器人技術、數字雙胞胎和先進的基於物理的模擬。它利用CUDA進行圖形渲染,將實時圖形與AI驅動的模擬能力相結合。
Cosmos
Cosmos是Nvidia的分佈式計算框架,簡化了大型AI模型的構建和訓練。通過與該公司的網絡解決方案和高性能計算框架集成,Cosmos幫助橫向擴展計算資源。它允許研究人員和開發者統一硬件資源,以便更無縫地進行大規模訓練。
開發者庫和工具包
除了核心框架之外,Nvidia還開發了數百個專門的庫,用於神經網絡操作、線性代數、設備驅動、高性能計算應用、圖像處理等。這些庫專門針對GPU加速進行了精心調整,進一步鎖定了投資時間以掌握這些庫的開發者社區。
關鍵要點:軟件堆棧可能是Nvidia持續領導地位的最重要因素。CUDA僅僅是故事的一部分。Nvidia更廣泛的AI軟件套件的深度和成熟度形成了一道強大的進入障礙,對於新的挑戰者來說是非常困難的。
數據中心的簡要插曲:AI電腦的出現
儘管這篇深入分析的焦點是數據中心轉型,但我們不應該忽略AI電腦的簡要討論。在今年的CES上,多家供應商宣布了標榜為「AI電腦」的筆記本和桌面電腦,通常配備NPUs(神經處理單元)或專用GPU以進行設備推斷。
ETR對客戶設備的數據
上述顯示的調查數據來自ETR,對約1,835名信息技術決策者進行調查。縱軸為淨分數或支出動量,橫軸為重疊或在那1,835個賬戶中的滲透率。表格插入顯示了點的繪製方式(淨分數和N)。這顯示Dell的筆記本在市場份額曲線的頂部,擁有543N,Apple、HP和Lenovo等公司的支出動量強勁。該圖顯示了主要PC供應商的健康支出動量。
Dell Technologies:推出了AI筆記本,並表示將與多個硅合作夥伴(包括AMD、Intel和Qualcomm)合作。我們認為它也可能整合Nvidia的解決方案。
Apple:在其M系列芯片中已經運用了NPUs多年,受益於電池壽命和本地推斷。Apple在垂直整合方面仍然是一股力量。
其他公司(HP、Lenovo等):每家公司都在測試或發布以AI為重點的終端,有時配備專用的NPUs或獨立的GPU。
NPUs在PC中的角色
目前,在許多AI電腦中,NPU經常閒置,因為軟件堆棧尚未完全優化。隨著時間的推移,我們預計客戶設備上將出現更多專門的AI應用——可能實現實時語言翻譯、圖像/視頻處理、高級安全性和小規模的本地LLM推斷。
Nvidia的地位
我們認為,Nvidia憑藉其在GPU領域的經驗,可以提供比典型的移動或筆記本中的NPUs更具性能的AI PC技術。然而,功耗、熱量和成本限制仍然是重大挑戰。我們確實看到Nvidia使用回收的「全牛」晶圓,並將其集成到具有降低功耗的筆記本GPU中。
雖然這一部分偏離了數據中心的焦點,但AI PC可能會推動開發者的採用。在設備上的AI對於生產力、專門工作負載和特定垂直用例意義重大。這反過來可能會加強更廣泛的生態系統向並行計算架構的轉型。
市場分析:數據中心支出和EPC的崛起
我們對整個數據中心市場——伺服器、存儲、網絡、電力、冷卻及相關基礎設施——從2019年到2035年進行了建模。我們的研究顯示,傳統通用計算向極端並行計算的過渡將迅速進行。
數據中心TAM增長
整個數據中心市場預計在2032年前將超過1兆美元,並在2035年前擴大到1.7兆美元。
從2024年開始,我們的基準模型顯示整體年均增長率為15%——這顯著高於企業IT歷史上單位數的增長率。
極端並行計算增長
我們將「極端並行計算」定義為用於AI訓練、推斷、高性能計算集群和高級分析的專用硬件和軟件。
EPC部分在同一時期內以23%的年均增長率增長,最終將遠遠超過以x86為主的系統曾經佔有的主導地位。
在2020年,EPC約佔數據中心支出的8%。到2030年,我們預計它將超過50%。到2030年代中期,先進加速器可能將佔據數據中心硅投資的絕大多數(80%至90%)。
Nvidia對EPC支出的捕獲
目前,我們估計Nvidia約佔整個數據中心細分市場的25%。我們認為,只要Nvidia不犯重大錯誤,它將在整個預測期內保持該領先份額,儘管面臨超大規模數據中心、AMD等的激烈競爭。
增長驅動因素
生成式AI和大型語言模型:像ChatGPT這樣的大型語言模型展示了加速計算在自然語言、編碼、搜索等領域的強大能力。
企業代理模型:全球企業將在商業過程中嵌入AI,這需要更重的數據中心工作負載。
機器人技術和數字雙胞胎:隨著時間的推移,工業自動化和先進機器人技術將要求大型模擬和實時推斷。
自動化投資回報:減少成本和勞動依賴的驅動力通常在與加速AI結合時會產生即時回報。
關鍵要點:預期向加速計算的轉變構成了我們對數據中心增長的積極看法的基礎。我們相信,極端並行計算為數據中心基礎設施投資帶來了多年的(甚至數十年的)超周期。
結論及我們對Nvidia積極前景的風險
前提總結
我們主張,一個新的超過一兆美元的市場正在形成,這一切都受到AI的推動。數據中心——如我們所知的那樣——將轉變為一種分布式的並行處理結構,其中GPU和專用加速器將成為常態。Nvidia的緊密集成平台(硬件+軟件+生態系統)引領這一轉型,但它並不孤單。超大規模數據中心、競爭的半導體公司和專門的初創公司都在這一快速擴張的市場中扮演著重要角色。
情景的主要風險
儘管我們的評估積極,但我們承認幾個風險:
對台積電的依賴和供應鏈脆弱性
Nvidia對台積電的依賴非常重。來自地緣政治事件(特別是涉及中國和台灣)的潛在干擾是一個關鍵脆弱性。
AI過度炒作或經濟衰退
AI可能無法如某些人預期的那樣迅速帶來近期回報。宏觀經濟放緩可能抑制對昂貴基礎設施的支出。
開源替代品
眾多社區和供應商正在開發開源框架,以繞過Nvidia的軟件堆棧。如果這些框架成熟到一定程度,可能會侵蝕Nvidia在開發者心智中的主導地位。
反壟斷、監管和黃仁勳的接班計劃
全球各地的政府將AI放在了十字路口,從倫理到競爭政策。監管壓力可能會限制Nvidia打包硬件和軟件的能力,或通過收購擴張。
黃仁勳是提供戰略方向、清晰溝通和在行業內具有巨大影響力的單一最重要力量。如果他不再能領導Nvidia,這將改變動態。接班計劃的討論尚未披露,但這仍然是一個未被言明的風險。
替代方法
量子計算、光學計算或超低成本AI芯片可能最終會顛覆GPU的主導地位,尤其是如果它們在性能和成本功耗上提供更優的表現。最後的話:我們認為Nvidia的未來看起來光明,但它不能自滿。該公司的最佳防禦仍然是對硬件和軟件的持續創新——這一策略使其走到今天,並可能推動其在這一極端並行計算新時代的持續領導地位。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。