Nvidia以200億美元授權Groq,揭開AI推理架構新戰線
Nvidia與Groq達成的20億美元戰略授權協議,是未來AI技術堆疊中四大競爭戰線之一的首次明顯動作。2026年,這場競爭將逐漸清晰,尤其對企業級AI應用開發者而言,這標誌著以往「一款GPU通吃」的AI推理時代正逐步走向終結。
我們日常訪談的技術決策者——那些構建AI應用及其背後數據管道的人——都將這次交易視為一個信號:AI推理架構正走向「分解式推理架構」,即半導體晶片將被拆分成兩種不同類型,以應對既需要龐大上下文又需瞬時推理的多元需求。
為何推理工作負載正將GPU架構分裂?
要理解Nvidia執行長黃仁勳為何願意拿出其據報高達600億美元現金儲備的三分之一去授權Groq,必須先看他們所面臨的存亡威脅——Nvidia目前全球GPU市場佔有率高達92%。
2025年底,AI推理工作負載首次在整體數據中心收入上超越了訓練工作負載,這被稱為「推理翻轉」(Inference Flip)。在這個新階段,除了精確度外,戰場轉向延遲(latency)和自主智能體維持「狀態」的能力。
這場戰爭有四大前線,而每一條戰線都指向同一結論:推理工作負載的分散化速度,遠超GPU的泛用能力。
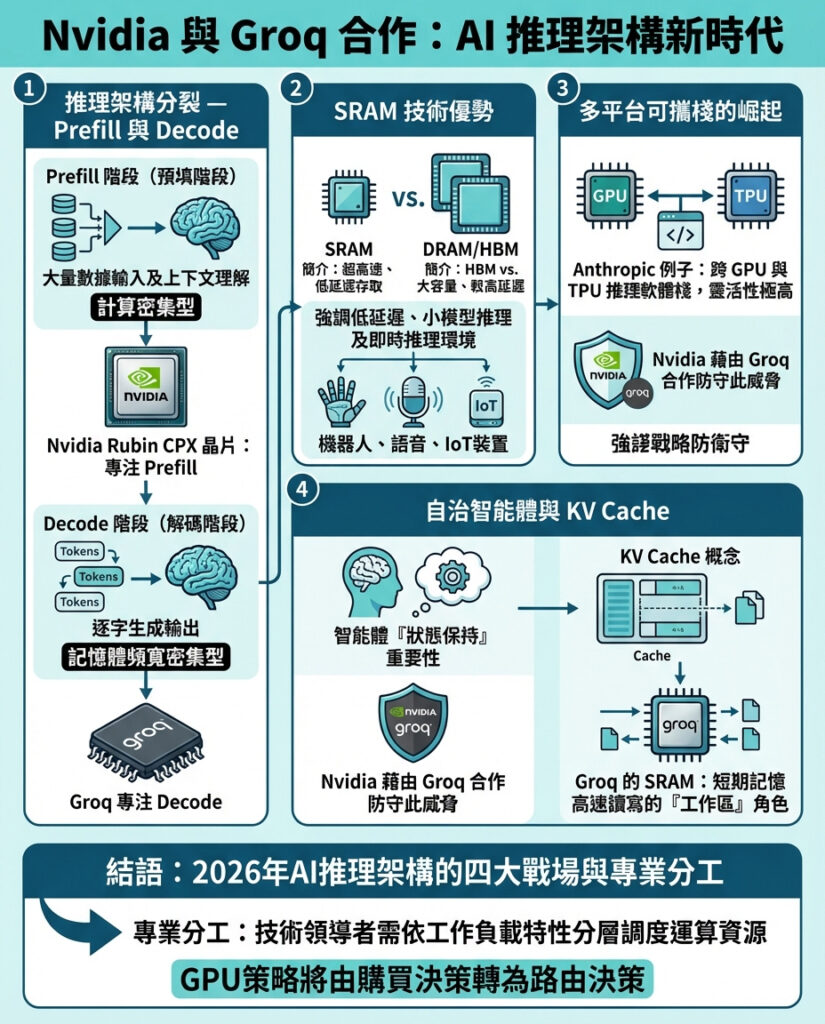
1. GPU被拆分為兩部分:Prefill與Decode階段
Groq投資人Gavin Baker(雖有利益關係,但對架構極為熟悉)清楚地指出,推理正分化成「prefill」與「decode」兩個階段。
* Prefill階段:可理解為用戶的「提示(prompt)」階段。模型需大量吸收資料,不論是十萬行代碼還是一小時的影片,計算出上下文理解。這是「計算密集型」,Nvidia的GPU在矩陣乘法上歷來表現卓越。
* Decode階段:則是逐字元(token)生成階段。模型讀入提示後,逐字產出下一個詞,並將其回饋系統以預測後續詞彙。這是「記憶體頻寬密集型」,如果資料無法以足夠速度從記憶體送到處理器,模型就會卡頓,不論GPU多強。這正是Nvidia的短板,也是Groq專門的語言處理單元(LPU)及其SRAM記憶體擅長的領域。
Nvidia已宣布將推出名為「Vera Rubin」的新晶片家族,專為這種分裂架構設計。其中Rubin CPX專注於prefill階段,可處理超過一百萬token的巨大上下文,並採用成本較低的128GB GDDR7記憶體,取代昂貴且供應有限的高帶寬記憶體(HBM)。
而Groq的高速度decode晶片將被整合進Nvidia的推理路線圖中,對抗Google TPU等競爭對手,捍衛其CUDA軟體生態系統的霸主地位。
Baker因此預測,Nvidia此舉將導致大多數專用AI晶片計劃取消,僅Google TPU、Tesla AI5及AWS Trainium能留存。
2. SRAM的獨特優勢
Groq技術的核心是SRAM。與PC使用的DRAM或Nvidia H100 GPU上的HBM不同,SRAM直接刻在處理器邏輯中。
微軟風投M12合夥人Michael Stewart指出,SRAM在短距離移動資料時能耗極低,約0.1皮焦耳,比DRAM高20至100倍的能耗低很多。
在2026年,智能體須即時推理的環境下,SRAM像是高速「草稿紙」,讓模型能快速操作複雜符號與推理,免去頻繁存取外部記憶體的浪費。
但SRAM體積大且製造成本高,容量有限。Weka首席AI官Val Bercovici認為,SRAM適合8億參數以下的小型模型,這市場不小,涵蓋邊緣推理、低延遲、機械人語音、物聯網等需在手機或本地執行、避免雲端的應用。
2025年模型蒸餾技術爆發,許多企業將龐大模型壓縮成高效小模型,SRAM正好契合這些高速小模型的需求。
3. Anthropic的「可攜式堆疊」威脅
這筆交易背後另一關鍵推手是Anthropic成功打造了跨多種加速器的可攜式軟體堆疊。
Anthropic的Claude模型能在Nvidia GPU及Google Ironwood TPU間切換,打破了過去只能在Nvidia堆疊中高效運行的局限。Weka的Bercovici指出,市場對Anthropic這種多平台軟體策略的重視還遠遠不足。
Anthropic最近承諾使用超過100萬個Google TPU,超過1GW的計算能力,確保不被Nvidia價格或供應限制綁架。Nvidia藉由整合Groq的高速推理IP,防止高性能任務流失至Google TPU陣營,維持CUDA生態系統的競爭力。
4. 智能體「狀態保持」戰爭:Manus與KV Cache
Groq交易時間點剛好與Meta兩天前收購智能體先驅Manus同步。Manus關注智能體的「狀態保持」能力,這是智能體能否有效完成現實任務的關鍵。
KV Cache(鍵值快取)是大型語言模型在prefill階段建立的「短期記憶」。Manus指出,生產級智能體的輸入輸出token比可達100:1,即說每說一個詞,智能體同時思考並記憶100個詞。
KV Cache的命中率是生產智能體的核心指標,一旦快取被驅逐,模型就得耗費大量能量重新計算提示。
Groq的SRAM可作為這些智能體的高速「草稿紙」,尤其適合小型模型。結合Nvidia的Dynamo框架及KVBM,Nvidia正打造一個可在SRAM、DRAM及Weka等閃存間分層存取狀態的推理「作業系統」。
Supermicro技術總監Thomas Jorgensen表示,先進GPU集群的瓶頸已非計算能力,而是餵入GPU的資料流,網絡成為集群內部重要組件,GPU間帶寬增長速度快於其他部分,推理架構必須分解才能突破瓶頸。
2026年的結論
我們正進入極度專業化時代。過去數十年,主流大廠靠一款通用架構稱霸市場,但忽略了邊緣需求,Intel忽視低功耗即是經典案例。Michael Stewart認為,Nvidia此舉顯示市場渴望更多選擇,領導者也必須擁抱多元解決方案。
對技術領導者來說,訊息很明確:別再把系統架構當作「一機櫃、一加速器、一答案」來設計。2026年,勝利屬於那些能明確標記工作負載類型,並將任務導向合適層級的團隊:
* Prefill重 vs. Decode重
* 長上下文 vs. 短上下文
* 互動式 vs. 批次處理
* 小模型 vs. 大模型
* 邊緣約束 vs. 數據中心假設
這些標籤將決定架構走向。GPU策略不再是單純的採購決策,而是路由決策。勝利者不會問買了哪款晶片,而是問每個token在哪裡跑,為何如此分配。
—
評論與深度分析
這篇報道深刻揭示了2026年AI推理硬體領域的重大轉變,尤其是在GPU架構被細分為prefill和decode兩大階段的核心趨勢。這不僅是技術層面的演進,更是產業格局的重塑。
Nvidia大手筆授權Groq,表面看是尋求技術補強,實則是對市場多元化的積極回應。Groq的SRAM技術突破了傳統GPU在推理延遲和狀態保持上的瓶頸,尤其在邊緣計算與小模型應用中展現巨大潛力。這意味著未來AI硬體不再是單點突破,而是多層次、多元化的「生態系統競爭」。
Anthropic跨平台堆疊戰略,則凸顯軟體生態在硬體競爭中的關鍵地位。當軟體能讓模型靈活在不同硬體間遷移,硬體廠商的壟斷優勢將被削弱,逼迫像Nvidia這樣的巨頭必須採取開放且多元合作的策略。
此外,智能體的「狀態保持」問題引發的KV Cache技術挑戰,反映出AI系統越來越接近人類思考模式的複雜性。這對硬體記憶體架構提出了前所未有的要求,也將推動記憶體技術如SRAM與層級存儲體系的快速創新。
對香港及華語市場的啟示是,未來AI硬體選擇將不再是單一品牌或架構的問題,而是如何根據具體應用場景靈活組合、層層優化。企業技術決策者須跳出傳統思維框架,設計多元、分層且具彈性的AI基礎設施,才能在激烈的全球AI競爭中佔得先機。
總結來說,這場圍繞AI推理的「架構大分裂」不僅是技術革新,更是產業生態變革的前奏,值得技術領袖與投資人密切關注,提前佈局。
以上文章由GPT 所翻譯及撰寫。而圖片則由GEMINI根據內容自動生成。
🖼️ AI 圖庫|抄咒語學玩法
想睇吓人哋點玩 AI 畫圖?圖庫集合大量 Flux / Gemini 作品, 可以一 click 複製咒語,直入生成器再改做自己版本。
 Gallery
Gallery
 Gallery
Gallery
 Gallery
Gallery