✨🎱 Instagram留言 →
AI即回覆下期六合彩預測
🧠 AI 根據統計數據即時生成分析
💬 只要留言,AI就會即刻覆你心水組合
🎁 完!全!免!費!快啲嚟玩!


下期頭獎號碼
📲 去 Instagram 即刻留言
Nvidia與Groq簽訂200億美元戰略授權協議,揭示AI推理架構的四大變革戰場
Nvidia以200億美元與Groq達成的戰略授權協議,是未來AI技術堆疊四大戰場中首個明顯動作。2026年,這場競爭將對企業建設者變得越來越顯而易見。
對我們每天接觸的技術決策者——那些打造AI應用與數據管道的人來說,這份協議昭示著「一體適用」的GPU作為預設AI推理方案的時代正逐步結束。
我們正步入「分離式推理架構」時代,矽晶片本身被拆分為兩種不同類型,以適應需求同時兼顧龐大上下文和即時推理的世界。
為何推理工作負載將GPU拆成兩半
要理解Nvidia執行長黃仁勳動用其約600億美元現金儲備三分之一簽下Groq授權的原因,必須先看這家公司面臨的多重生存威脅,尤其是在其聲稱擁有約92%全球GPU市佔率的情況下。
2025年底,產業達到轉捩點:推理階段——即訓練完成的模型實際運行階段——首次超越訓練階段,成為資料中心收入的主要來源,根據Deloitte的報告。在這個被稱為「推理翻轉」的新時代,衡量標準改變了。準確度仍是基礎,但戰場轉向延遲時間與自主代理的「狀態維持」能力。
這場戰爭有四大戰線,每一條都指向同一結論:推理工作負載正比GPU通用能力分裂得更快。
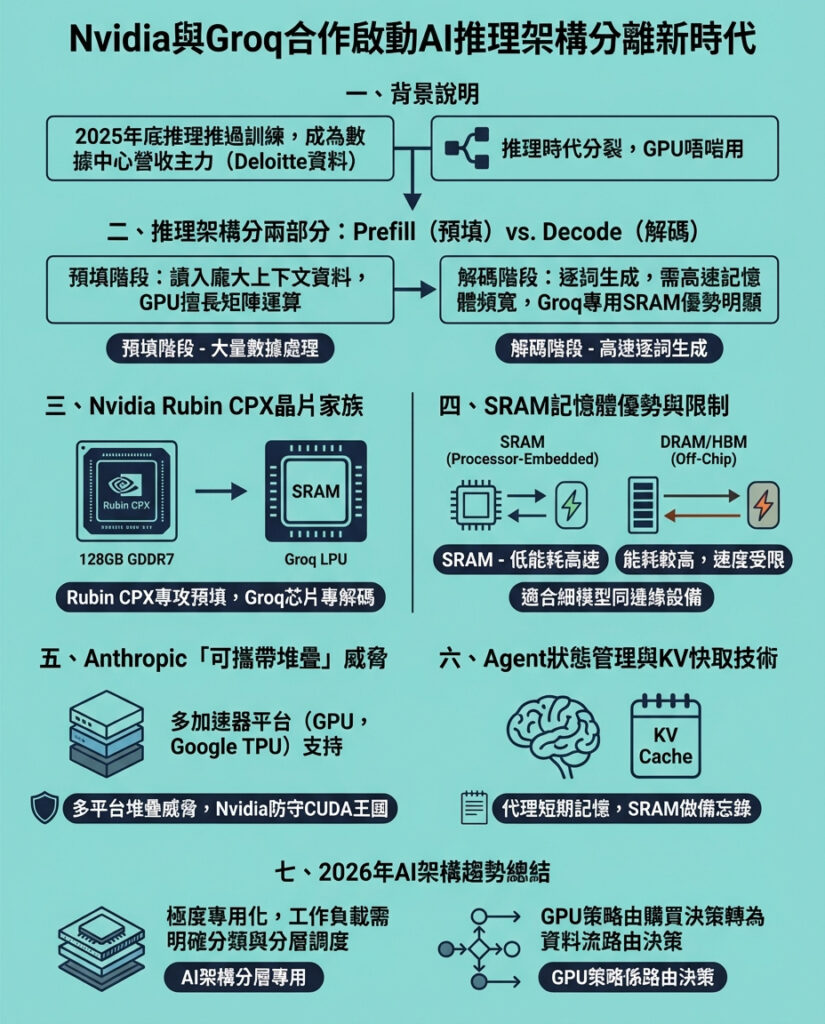
1. 拆分GPU:Prefill(預填)與Decode(解碼)
Groq投資人兼架構專家Gavin Baker總結這樁交易核心:「推理正分離成預填與解碼兩階段。」
預填是模型吸收大量資料的階段,如十萬行程式碼或一小時影片,進行上下文理解,屬於「計算密集型」,Nvidia GPU在矩陣乘法上表現出色。
解碼階段則是模型逐字(或逐token)生成內容,每產生一個詞便餵回系統預測下一個,這階段「記憶體頻寬」是瓶頸。資料若無法迅速在記憶體與處理器間流通,模型就會卡頓。這正是Nvidia較弱的環節,而Groq的語言處理單元(LPU)搭配靜態隨機存取記憶體(SRAM)恰好彌補這缺口。
Nvidia已宣布將推出專為此架構拆分設計的「Vera Rubin」晶片家族,其中Rubin CPX專責預填階段,優化處理百萬以上token的龐大上下文。為了降低成本,Rubin CPX採用128GB全新GDDR7記憶體,取代昂貴且供應有限的高頻寬記憶體(HBM)。
而Groq技術將成為解碼階段的高速運算引擎,幫助抵禦Google TPU等對手的挑戰,保持Nvidia CUDA軟體生態系統的領先地位。
Baker甚至預測,此舉將讓除了Google TPU、Tesla AI5和AWS Trainium之外的其他專用AI晶片計劃紛紛取消。
2. SRAM的獨特優勢
Groq技術的核心是SRAM,與個人電腦內的DRAM或Nvidia H100 GPU上的HBM不同,SRAM直接刻劃於處理器邏輯中。
微軟風投M12管理合夥人Michael Stewart形容,SRAM在短距離資料移動與能耗方面是最佳選擇,移動一個bit的能量約0.1皮焦耳,DRAM則差20至100倍。
在2026年,代理人需即時推理,SRAM成為終極「工作區」,讓模型在不浪費外部記憶體切換時間的情況下操作符號運算與複雜推理。
不過,SRAM物理體積大且昂貴,容量不及DRAM。Weka AI負責人Val Bercovici認為,SRAM適合8億參數以下的小型模型,這一市場不小,涵蓋邊緣推理、低延遲、機器人、語音、物聯網等場景,特別是手機端免雲端運算的需求。
2025年見證了模型蒸餾爆發,企業大幅縮小巨型模型至高效小模型,SRAM雖不適合千億參數的前沿模型,卻完美匹配這些小型高速模型。
3. Anthropic的「可攜式堆疊」威脅
這樁交易另一被低估的驅動力是Anthropic成功打造跨多種加速器的可攜式軟體堆疊,讓其Claude模型能在Nvidia GPU與Google Ironwood TPU間自由切換。
長久以來,Nvidia的技術優勢在於高效模型難以在非Nvidia硬體上運行。但Anthropic的跨平台軟體突破了這點,成為市場不容忽視的力量。
Anthropic近期承諾使用Google超過100萬個TPU,提供超過一吉瓦的運算能力,確保不受Nvidia價格與供應限制綁架。Nvidia透過授權Groq技術,確保高性能敏感工作負載仍能留在CUDA生態系統,守住核心地位。
4. 代理人的「狀態戰爭」:Manus與KV Cache
Groq協議發布之際,Meta剛完成代理人先驅Manus的收購。Manus專注於代理人的「狀態保持」能力。
如果代理人無法記住10步前做過什麼,便無法勝任市場調研或軟體開發等實務任務。KV Cache(鍵值快取)即大型語言模型在預填階段構建的「短期記憶」。
Manus指出,生產級代理人中,輸入token與輸出token比可達100:1,意味每說一個字,代理人同時「思考」並「記住」100個詞。KV Cache的命中率是關鍵,若快取被「驅逐」,代理人便失去思路,需耗費大量能量重新計算提示。
Groq的SRAM可作為這類代理人的高速工作區,尤其適合小型模型。配合Nvidia的Dynamo框架及KVBM,Nvidia正打造一套推理作業系統,將推理伺服器的狀態分層存放於SRAM、DRAM、HBM及其它快閃記憶體中。
Supermicro高級技術總監Thomas Jorgensen指出,計算不再是高端集群的瓶頸,反而是如何餵給GPU數據。GPU間帶寬增長迅速,成為最大挑戰。
因此,Nvidia推動分離式推理架構,讓企業應用能以專門存儲層級提供類記憶體性能的數據,同時由內嵌Groq技術的晶片高速處理token生成。
2026年的結論
我們正進入極度專業化時代。過去數十年,市場由單一通用架構主導,盲點往往是忽略了邊緣需求。微軟M12合夥人Stewart認為,Nvidia正避免重蹈Intel忽視低功耗產品的覆轍。即使是行業龍頭,也必須積極取得人才與技術,顯示市場渴求更多選擇。
對技術領袖而言,訊息是:停止將技術堆疊設計成「一機架、一加速器、一答案」。2026年,優勢屬於能明確標記工作負載,並導向正確層級的團隊:
* 預填重 vs 解碼重
* 長上下文 vs 短上下文
* 互動式 vs 批次式
* 小模型 vs 大模型
* 邊緣限制 vs 資料中心假設
你的架構將依此標籤調整。2026年,「GPU策略」不再是購買決定,而是路由決定。贏家不問買了哪顆晶片,而問每個token在哪裡運算、為何如此。
—
評論與啟發
這篇報導深刻揭示了AI推理技術架構正面臨的根本轉型,Nvidia與Groq的合作不僅是商業交易,更象徵著AI硬體生態系統的分水嶺。傳統以GPU為核心的單一架構正逐步瓦解,取而代之的是更細膩的分層與專用化設計,這反映出AI模型日益龐大與多樣化的需求。
尤其是將推理拆解為預填與解碼兩階段,凸顯了不同計算與記憶體瓶頸的本質差異。Groq利用SRAM解決低延遲高頻寬需求,與Nvidia的GDDR7結合,形成互補策略,堪稱技術新高度。這種分散式架構也與Anthropic打造跨平台軟體堆疊的潮流相符,反映出軟硬體協同演進的趨勢。
此外,Meta收購Manus強調「狀態保持」的重要性,突顯AI代理人從單次推理走向持續交互的必然。這提醒我們,AI不再是單純的批次計算,而是需要實時記憶與推理的複雜系統,對硬體架構提出更高挑戰。
對香港乃至全球科技產業而言,這波變革意味著AI硬體選擇將更加多元且分工明確。企業應重新審視自身AI應用的工作負載特性,避免盲目跟風購買單一GPU,而是建立靈活的資源調度與分層存儲策略。這也為本地AI創新者提供了機會,開發針對不同推理階段的優化方案,搶佔未來市場先機。
總之,2026年將是AI硬體架構大洗牌的關鍵年,技術決策者必須跳出「GPU至上」的舊框架,擁抱分散式、專用化和跨平台協同,才能在這場競爭中立於不敗之地。
以上文章由GPT 所翻譯及撰寫。而圖片則由GEMINI根據內容自動生成。