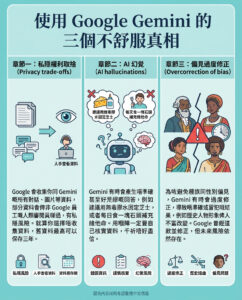
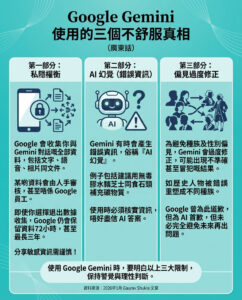
Nvidia推出全新音樂生成模型Fugatto 創造“前所未聞”的聲音
Nvidia公司今日宣布推出一款生成式人工智能模型Fugatto(全名為Foundational Generative Audio Transformer Opus 1),旨在從人類語言提示中創造“新”音樂和音頻。這一新模型的獨特之處在於它能夠修改人聲並創造出其他模型無法產生的“新穎聲音”。
這家知名的晶片製造商以生產強大的圖形處理單元聞名,但目前尚未公開發布該模型,原因在於對安全性的擔憂。Nvidia表示,Fugatto與其他音樂和音頻生成模型的不同之處在於它能夠吸收並修改現有的聲音。例如,它可以聆聽鋼琴演奏的音樂片段,並將該聲音轉變為人聲演唱的音符,或是改編為小提琴等其他樂器的聲音。它還能夠對人聲錄音進行調整,改變唱歌時的口音和情緒。
雖然說Fugatto的聲音完全新穎可能有些誤導,因為像所有AI模型一樣,其輸出來自於一個算法,利用現有數據源來創造滿足用戶要求的內容。即便如此,Nvidia表示,Fugatto能夠通過疊加兩種不同的音頻效果來創造出“它從未見過的聲音景觀”,從而產生原創的作品。
在YouTube上發布的一段視頻中,該公司展示了Fugatto如何生成一列火車的聲音,隨著時間的推移逐漸變幻為管弦樂演奏,並能將快樂的聲音變成憤怒的聲音等等。
Nvidia聲稱這些能力在音頻生成模型中尚未見過。此外,除了基本的提示工程,Fugatto還為用戶提供了更細緻的控制,以編輯他們創造的聲音景觀。
Nvidia的應用深度學習研究副總裁Bryan Catanzaro對路透社表示,生成式AI有潛力對音樂製作產生影響,就像電子合成器一樣。“如果我們回顧過去50年的合成音頻,現在的音樂因為計算機而有所不同,”他說。“生成式AI將為音樂、電子遊戲以及想要創作的普通人帶來新能力。”
Nvidia並不是第一家嘗試生成式AI音樂創作的公司。上個月,Meta推出了一個名為Movie Gen的新模型,能夠為其生成的短片創造視頻和聲音景觀。
Nvidia對用於訓練Fugatto的數據並未透露太多,只表示其由“數百萬音頻樣本”組成,這些樣本來自開源數據。該公司還確認目前沒有計劃將Fugatto提供給AI開發者,這與Meta的做法相似,Meta也拒絕這樣做。根據Catanzaro的說法,他的團隊仍在討論如何安全地將該模型公開發佈。
“任何生成技術都總是帶有一定的風險,因為人們可能會利用它生成我們不希望他們生成的內容,”他說。“我們需要對此保持謹慎,這就是為什麼我們沒有立即發布的計劃。”
除了安全方面的擔憂外,Nvidia無疑也在考慮潛在的版權問題。今年6月,包括索尼音樂娛樂、華納音樂集團和環球音樂集團在內的唱片公司對生成式AI音樂初創公司Suno Inc.和Uncharted Labs Inc.提起訴訟,指控他們在“幾乎無法想像的規模”上“廣泛侵犯”受版權保護的聲音錄音。
AI與好萊塢的關係同樣緊張。儘管一些AI公司,如OpenAI,正在與好萊塢製片廠就數據使用進行談判,但女演員斯嘉麗·約翰遜已公開指控OpenAI克隆她的聲音,並威脅對該公司採取法律行動。
這一發展凸顯了生成式AI在音樂創作和音頻生成領域的潛力,同時也反映了在科技進步與版權保護之間的矛盾。未來,如何平衡創新與法律風險將成為業界必須面對的重要課題。Nvidia的Fugatto雖然尚未公開,但其技術的潛力無疑為音樂創作的未來開啟了新的可能性。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。