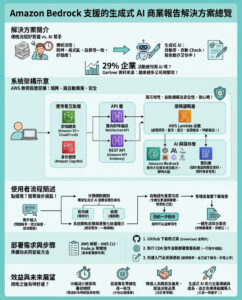
Nvidia 伺服器助中國 Moonshoot AI 模型速度提升 10 倍
Nvidia 宣佈最新推出的 GB200 NVL72 架構級 AI 伺服器,能夠將開源的混合專家(Mixture-of-Experts,MoE)模型加速多達 10 倍。這項提升是以 Moonshoot AI 的 Kimi K2 Thinking 模型,與舊有的 HGX H200 平台進行比較得出的。
MoE 架構會將 AI 任務拆分給不同專業模組,並只啟動對每個輸入標記最相關的部分,令運算比傳統密集模型更有效率。Nvidia 表示,GB200 NVL72 系統透過高速 NVLink 連接串聯 72 顆 Blackwell GPU,令 MoE 模型能跨越更多 GPU 運行,減少記憶體和通訊瓶頸。
此設計不但能加快推理速度,降低計算需求,還支援更長的輸入序列。多家主要雲端供應商如 AWS、Google Cloud、Microsoft Azure 及 CoreWeave,已經開始部署 GB200 NVL72,支援企業級 AI 工作負載。
GB200 NVL72 的供應情況仍未明朗,性能雖佳但價格及推出時間不一
雖然 Nvidia 表示 MoE 模型如 Kimi K2 速度提升達 10 倍,但 GB200 NVL72 的價格未公開,且不同供應商的推出時間也有所差異,令 2025 年的產能規劃變得複雜。分析師已將 2025 年 GB200 NVL72 機櫃出貨預測砍半,約為 25,000 至 35,000 台,對應約 252 萬顆 GPU。
AI 基礎設施供應商 Together AI 表示,GB200 NVL72 的交貨周期約為 4 至 6 週,目前已無所謂「NVIDIA 彩票」——業界對 GPU 配額限制的俗稱。而歐洲 AI 雲平台 Nebius 則要求用戶必須至少提前一個月簽約。市場上亦有傳聞指 GB300 和 B300 GPU 將在 200 系列推出約半年後上市,性能提升約 50%,可能令買家選擇等待。
隨著開源 MoE 模型成熟,軟件廠商可構建托管服務
對於軟件整合商和雲端建設者而言,GB200 NVL72 提供 130 TB/s 的 NVLink 帶寬及最高 13.4 TB 的高頻寬記憶體(HBM 3e),使得像 Qwen3‑235B‑A22B 這類開源 MoE 模型能用於生產環境。Qwen3‑235B‑A22B 擁有 2350 億參數,每個標記約激活 220 億參數;DeepSeek V3.1 亦是開源的 MoE 模型。
這些模型大多使用 Apache 2.0 或 MIT 等寬鬆授權,允許商業部署。由於工作負載是稀疏的,成本主要取決於激活的專家數量,而非整體參數量。團隊還可以開發基於稀疏度的性能指標工具,如 S-MBU 和 S-MFU,更準確地衡量生產時的記憶體和計算使用率。
現時開源模型已支援高達 128K 標記的上下文窗口,這打開了翻譯、程式碼輔助及長文件推理等應用場景,而無需依賴昂貴的專有系統。
—
評論與啟示
Nvidia 最新的 GB200 NVL72 伺服器在加速 MoE 模型方面展現出令人驚嘆的性能提升,特別是對於中國 Moonshoot AI 這類新興 AI 公司來說,能大幅縮短模型推理時間,提升實用性和效能。然而,供應鏈和定價的不確定性,以及市場對更強大 GPU 版本的期待,讓企業在購買決策上面臨挑戰。
MoE 模型的稀疏計算特性為 AI 發展帶來突破,特別是在成本和資源利用率上。隨著開源模型的成熟及寬鬆授權的推廣,更多軟件商和雲服務商將有機會打造專門的 MoE 托管服務,推動生態系統的多元發展。
對香港及亞洲市場而言,這代表本地 AI 研發和應用有望借助更高效能的硬件平台快速追趕國際先進水平。政府和企業可思考如何投資於這類新技術基礎設施,並培養相關專才,從而在全球 AI 競賽中佔有一席之地。
未來,隨著更強大 GPU 的推出,以及 MoE 模型在更多領域的探索,AI 產業的競爭格局將更加激烈。用戶與企業應密切關注硬件與軟件的協同發展,抓住稀疏計算帶來的機遇,避免被技術潮流拋在後面。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。