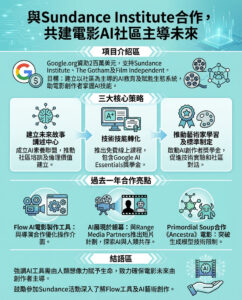
Nvidia公布Blackwell Ultra GB300專業AI加速器詳細規格
Nvidia最新推出旗艦專業AI加速器Blackwell Ultra GB300,將取代現有的GB200平台。新款GPU擁有更多核心、容量大幅提升的記憶體、更快的輸入輸出介面,以及比前代更高的功耗需求。GB300現已進入量產階段,部分早期客戶將很快收到首批出貨。
全球多家公司正在競相開發最先進的AI訓練和推理硬件,但不可否認Nvidia一直處於行業最前沿,提供最高效能與最強大AI運算硬件。GB200已是當前世代的頂峰,而即將出貨的GB300將為先行用戶帶來顯著的性能提升。
Blackwell Ultra GPU配備160個流處理器(streaming multiprocessors),相較GB200的144個有所增加,令整體CUDA核心數達到20,480個。這些核心均採用Blackwell架構,並基於台積電4NP製程節點,較GB200所用的4N節點更先進。
根據VideoCardz報導,這些核心可利用第五代Tensor Core,支援FP8、FP6及全新NVFP4數據格式,且每個Tensor Core的記憶體容量更大。這些技術改進有望在相關計算中帶來至少兩倍或以上的性能提升。
該GPU配備八組12層HBM3E堆疊記憶體,總容量高達288GB,是GB200的兩倍,讓平台能處理更大規模的AI模型,加速運算效率及功能。
為了配合提升的性能,GB300採用全新PCIe 6介面,傳輸頻寬最高可達256GB/s,是上一代PCIe 5的兩倍。當然,這也意味著功耗顯著增加,GB300峰值功耗最高可達1,400瓦。
GB300現已量產並即將出貨,但因出口限制,該產品不會銷往中國及相關地區。相反,較簡化的GB30型號可能會在未來數月內進入中國市場,但因中國對Nvidia硬件監控的擔憂,具體情況仍不明朗。
—
編輯觀點與評論
Nvidia的Blackwell Ultra GB300展現了AI硬件在性能和規模上的跨越式進步,尤其是核心數量和記憶體容量的翻倍升級,標誌著AI模型規模與複雜度持續飆升的趨勢。288GB的HBM3E記憶體對於訓練大型深度學習模型,尤其是語言模型和多模態模型,將帶來顯著優勢,減少頻繁的資料交換瓶頸。
PCIe 6介面的引入不僅提升了資料傳輸速率,也反映出硬件設計對於數據流通效率的極度重視,這是AI訓練中不可忽視的關鍵環節。不過,1,400瓦的峰值功耗也提醒業界,能源效率仍是未來設計必須兼顧的挑戰。高功耗意味著數據中心運營成本將上升,如何在性能和能耗間取得平衡將是一大考驗。
此外,中國市場因出口管制和監控疑慮而無法直接獲得GB300,顯示國際科技競爭與地緣政治的影響日益凸顯。Nvidia可能需透過較簡化版本GB30來繼續滲透該市場,這也反映出全球AI硬件供應鏈和市場的複雜性。
總結來說,Blackwell Ultra GB300不僅是技術上的突破,也揭示了AI硬件發展中的多重挑戰:硬件創新、能源管理、以及全球市場與政策環境的交織。未來的AI硬件競賽,將不只是技術層面,更是戰略與生態系統的較量。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。