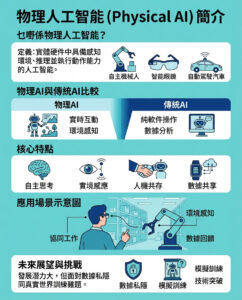
3個問題:人工智能如何助力監察及支援脆弱生態系統
麻省理工學院(MIT)博士生兼計算機科學與人工智能實驗室(CSAIL)研究員Justin Kay分享他結合人工智能與電腦視覺系統,監察支撐地球的生態系統的研究工作。
近期一項來自俄勒岡州立大學的研究估計,超過3500種動物因棲息地改變、自然資源過度開採及氣候變化等因素,面臨滅絕風險。為了更深入了解這些變化並保護脆弱的野生動物,像MIT博士生兼CSAIL研究員Justin Kay這類保育科學家,正研發電腦視覺演算法,精確監察動物群體。
Justin Kay隸屬於MIT電機工程及計算機科學系助理教授、CSAIL首席研究員Sara Beery的實驗室,目前專注於追蹤太平洋西北地區的鮭魚。鮭魚不但為鳥類及熊等掠食者提供重要營養,也有助管理昆蟲等獵物的數量。
不過,面對龐大的野生動物數據,研究人員需從眾多AI模型中挑選合適的工具進行分析。Kay與CSAIL及麻省大學阿默斯特分校的同事共同開發了一種名為「共識驅動主動模型選擇」(CODA)的新方法,大幅提升數據處理效率,協助保育人員挑選最佳AI模型。他們的研究在今年十月的國際電腦視覺會議(ICCV)被評為亮點論文。
該項研究同時獲得美國國家科學基金會、加拿大自然科學與工程研究理事會,以及Abdul Latif Jameel水與食品系統實驗室(J-WAFS)的支持。以下為Kay就該研究及其他保育工作接受訪問的內容。
問:你的論文提出,在眾多AI模型中如何挑選最適合特定數據集的問題。考慮到HuggingFace模型庫中已有多達190萬個預訓練模型,CODA如何幫助解決這個挑戰?
答:過去使用AI分析數據,通常需自行訓練模型,這不僅耗時,還需大量數據標註及技術能力。現時情況正改變,因為有數以百萬計的預訓練模型可供下載,能直接用於多種預測任務。這讓用戶可免去自行訓練的繁複,直接用現成模型分析資料。但新問題隨之而來:究竟從這麼多模型中應該選擇哪一個?
傳統上,為了選擇合適模型,用戶仍需花大量時間標註測試數據集,尤其在真實應用中,數據分佈不均且變化多端,模型表現也可能不穩定。我們設計CODA的目標,就是大幅減少這種標註工作量。CODA透過「主動標註」方式,讓用戶逐步標註最有資訊價值的數據點,而非一次過批量標註大量數據。這方法非常有效,通常只需標註約25個例子,就能準確挑出最佳模型。
CODA為人工智能系統的開發與部署,提供了如何高效利用人力的新思路。隨著AI日益普及,我們強調應把更多精力放在健全的評估流程,而非只專注於模型訓練。
問:你將CODA應用於野生動物圖像分類,表現出色。為何如此?未來這類系統在生態監察中會扮演什麼角色?
答:一個重要的洞見是,當考慮多個候選AI模型時,模型間的「共識」比單一模型的預測更具資訊價值,可視作「群眾智慧」。將所有模型的預測結果匯總,能為未標註數據點的標籤建立合理的先驗判斷。
CODA基於估計每個模型的「混淆矩陣」——即若某數據點真實標籤是X,該模型預測為X、Y或Z的概率。這建立了模型、標籤類別與未標註數據間的信息關聯。
舉例說,假設你是野生動物生態學家,剛收集了數十萬張野外相機拍攝的照片,想知道裡面有哪些物種。這是一項耗時的任務,電腦視覺分類器可助自動化。你正猶豫用哪個物種分類模型。若你已標註了50張老虎圖片,且某模型在這些樣本上表現良好,你便可有信心該模型在未標註老虎圖片中也會表現出色。你亦知道該模型若預測某圖像為老虎,錯誤機率較低,其他模型若標註不同類別,可能是錯誤。利用這些相互依賴,CODA能推估每個模型的混淆矩陣及整體準確率分佈,從而更精準地選擇哪些數據點值得標註,提升模型選擇效率。
未來我們認為,可結合領域專家知識,為模型選擇建立更有效的先驗判斷,例如某模型已知在特定類別表現優異或較差。也可擴展至更複雜的機器學習任務與更先進的概率性能模型。我們希望此研究能啟發其他學者,持續推動技術前沿。
問:你所在的Beerylab由Sara Beery領導,團隊將機器學習的模式識別能力與電腦視覺技術結合,用於監察野生動物。除了CODA,團隊還有哪些追蹤和分析自然世界的方法?
答:這個實驗室非常有活力,持續展開多個新項目。我們正用無人機監察珊瑚礁,追蹤大象個體的重識別,並融合衛星與現場相機的多模態地球觀測數據,僅舉幾例。
總體來說,我們關注生物多樣性監測的新技術,致力找出數據分析的瓶頸,並開發通用的電腦視覺與機器學習方法來解決這些問題。這種「元問題」的思考方式,讓我們能針對核心挑戰提出創新解決方案。
我參與的研究之一,是運用電腦視覺演算法計算水下聲納影片中遷徙鮭魚的數量。即使我們盡力建立多元訓練數據,數據分佈仍會變化,特別是當部署新相機時,往往會遇到新情況,導致演算法性能下降。這是機器學習中的「領域適應」問題。我們發現現有領域適應算法在魚類數據上的訓練與評估有明顯限制,因此開發了新的領域適應框架,今年早些時候發表在《機器學習研究匯刊》(Transactions on Machine Learning Research),推動了魚群計數、自駕車及太空船分析等領域的進展。
我特別興奮的是,如何更好地在預測機器學習算法的實際應用背景下,開發與分析其性能。通常電腦視覺演算法輸出的結果(如動物的邊框標註)不是最終目標,而是為解答更大問題(例如「這裡有哪些物種?牠們如何隨時間變化?」)的手段。我們正研究如何將機器學習預測與多階段預測流程及生態統計模型結合,重新思考如何將人類專業知識有效融入系統。CODA就是一個例子,我們把機器學習模型視為固定,建立統計框架高效評估其表現。
自然世界正以前所未有的速度和規模變化,能快速從科學假設或管理問題轉化為數據驅動的答案,對於保護生態系統和依賴它們的社區至關重要。人工智能的進步能發揮重要作用,但我們必須批判性地思考如何設計、訓練及評估算法,應對這些真實且緊迫的挑戰。
—
編輯評論:
Justin Kay及其團隊的研究,展示了人工智能如何從根本上改變我們監察及保護自然生態系統的方式。CODA不僅提高了模型選擇的效率,更重要的是,它讓非專業用戶也能活用海量預訓練模型,降低了AI應用的門檻,這對生態保育領域尤其關鍵,因為資源有限且數據龐大。
此外,團隊對於「群眾智慧」的利用與混淆矩陣的創新應用,為機器學習模型評估提供了全新視角,強調了模型間協同的重要性,這種多模型融合策略值得在更多領域推廣。
值得注意的是,他們不僅停留在技術層面,更深入思考機器學習在生態系統監控中實際應用的挑戰,特別是數據分佈變化與領域適應問題,這種面向現實世界問題的研究態度,令成果更具生命力和實用價值。
未來,隨著AI模型和生態數據的持續增長,如何有效整合專家知識與多源數據,將成為關鍵。這項研究為跨領域融合提供了範例,也提醒我們科技進步需伴隨對環境與社會需求的深刻理解,才能真正造福地球與人類。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。