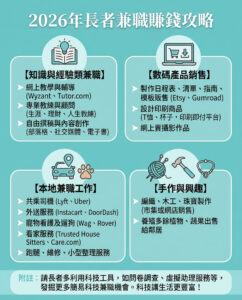
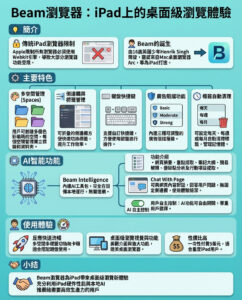
研究有望令大型語言模型提升複雜推理能力
麻省理工學院(MIT)的研究團隊開發出一種方法,令大型語言模型(LLMs)更靈活應對如策略規劃或流程優化等具挑戰性的任務。
大型語言模型雖然在很多應用上表現優秀,但面對需要複雜推理的新任務時,常常力不從心。例如,一個專門用來總結財務報告的模型,可能在預測市場趨勢或識別詐騙交易時表現不佳。為了提升模型在未知且困難問題上的適應性,MIT研究人員嘗試利用一種稱為「測試時訓練」(test-time training)的技術,並展示這種方法可令模型準確度提升多達六倍。
「測試時訓練」如何助力模型學習新技能?
「測試時訓練」指的是在模型部署過程中,暫時更新模型內部部分參數,利用新任務的少量示例數據進行調整。這種方法與目前常用的「上下文學習」(in-context learning)不同,後者只是通過給模型一些示例作為提示,而不改變模型參數。
研究顯示,單靠上下文學習只能帶來有限的準確度提升,但透過測試時訓練實際調整模型參數,對於邏輯推理和複雜任務的表現提升尤為顯著。研究團隊還設計了一套框架,利用任務示例生成更多類似數據(例如水平翻轉輸入數據),擴大訓練集,進一步提高模型的適應能力。同時,他們採用「低秩調整」(low-rank adaptation)技術,只更新少量參數,確保訓練過程高效且實用。
提升複雜任務表現的突破
雖然測試時訓練每次只能針對單一任務進行,且訓練過程會令回答時間從幾秒延長至數分鐘,但對於需要高度精確度的困難任務來說,這種暫時性的模型調整非常值得。研究團隊在兩個包含極端複雜問題(如智商謎題)的基準數據集上測試此方法,結果顯示準確率比單純使用上下文學習高出六倍。對於涉及結構化模式或全新類型數據的任務,性能提升最為明顯。
未來,團隊希望進一步開發能夠自動判斷和選擇是否需要測試時訓練的模型,實現持續學習能力,減少人為介入。
我的評論與觀點
這項研究突破了目前大型語言模型「靜態」學習的限制,讓模型能在實際應用中根據新任務進行即時調整,顯著提升複雜推理和邏輯分析的能力。這對於醫療診斷、供應鏈管理等需要精確邏輯推理的領域尤為重要。
然而,測試時訓練帶來的計算成本和時間延長,限制了其在即時互動場景的普及。未來的挑戰在於如何在保持高效的同時,實現模型的自主判斷和持續學習,這或將成為AI發展的新方向。
此外,這種方法也提醒我們,純粹依賴語言模型的上下文提示能力並不足夠,真正的智能應該包含動態學習和自我調整的能力。這不僅是技術的進步,更是向「類人智能」邁進的重要一步。
總結來說,MIT團隊的研究為大型語言模型的應用擴展提供了新的可能性,尤其是在處理需要深度推理和策略規劃的複雜任務上,讓我們對AI未來的發展充滿期待。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。