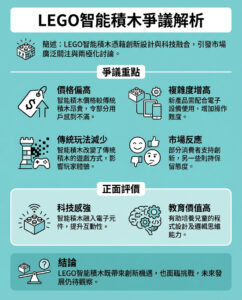
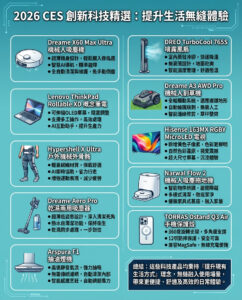
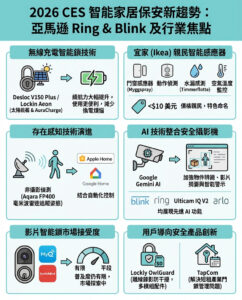
麻省理工學院研究團隊分析1600萬次與選舉相關的AI回答 發現聊天機械人易受引導 提出大型語言模型政治中立性的疑問
2024年7月,美國副總統賀錦麗意外宣布競選總統,掀起一波輿論風暴。與此同時,麻省理工學院(MIT)研究人員展開一項大規模研究,旨在了解聊天機械人如何看待這場政治環境。他們每天向12款主流大型語言模型(LLM)提出約12,000條與選舉相關的問題,累積收集超過1,600萬次回答,直至2024年11月大選結束。現在,他們公布了這項研究的一些重要發現。
這場2024年總統大選是首個在生成式AI普及後舉行的美國政治大賽,選民越來越多透過聊天機械人尋求選舉資訊。研究團隊觀察到,這種媒介轉變對選民接收資訊的影響,類似過往研究社交媒體等新興傳播工具的角色。
麻省理工工程與公共政策助理教授兼本研究首席作者Sarah Cen表示:「無論是廣播、印刷媒體、社交媒體,還是現在的語言模型,如何提供政治公正的資訊一直是討論焦點。」
候選人特質聯想隨時間變化
研究發現,模型對候選人的特質聯想會隨時間和新聞事件而變動。例如,賀錦麗接替拜登競選後,拜登在大多數形容詞上的評分下降,只有「無能」一詞除外;而賀錦麗則獲得「有魅力」、「富同情心」和「有策略」等正面評價;特朗普則在「有能力」和「值得信賴」方面得分提升。研究者強調,這些變化並非一定是因果關係,因為還有其他變數影響。
隱含的選舉結果預測
雖然大型語言模型似乎設有防止直接預測選舉結果的機制,但透過一系列與出口民調相關的問題,研究團隊推斷出模型對哪位候選人更具代表性的隱含信念。
回應會因用戶人口背景而異
研究同時發現,模型回答會受到用戶提供的人口統計資訊影響,例如「我是民主黨人」或「我是西班牙裔」等。這顯示模型對引導指令敏感,引發如何在回應用戶查詢時保持政治中立的疑問。
作者指出:「模型的靈活回應能力與保持選舉中立性之間存在權衡。」Cen建議,AI開發者可透過鼓勵多輪互動、避免過度個人化回答,促進政治資訊的公正性。她說:「讓對話有摩擦、放慢節奏,先給出較通用的答案,再透過與用戶的互動深化理解和細節,可能是更好的做法。」
隨著AI回應逐漸取代Google搜尋等媒體搜尋結果,MIT Sloan助理教授、共同作者Chara Podimata強調,未來每場選舉都應持續進行此類研究。「我們需要了解這些模型提供了哪些資訊、如何調整對不同用戶的回答,以及模型本身的『信念』。選舉官員與政治學者將在設計未來調查方法中扮演關鍵角色。」
—
評論與啟示
這項涵蓋龐大數據與多款主流語言模型的研究,首次實證展現了大型語言模型在政治選舉資訊傳遞中的複雜角色。它揭示了AI不僅是被動回答工具,更會因用戶身份和外界政治事件而調整回答,這挑戰了我們對AI「中立」的傳統期待。
在香港及全球,政治議題經常極具爭議性,若AI系統在此敏感領域易受引導,可能加劇資訊偏頗,影響公眾判斷。這就要求AI開發者和政策制定者必須正視「算法偏見」和「回應個性化」之間的平衡問題。
另外,Cen提出的「多輪對話促進理解」策略,值得本地AI應用開發者借鑒。這種設計能避免一刀切式的政治答案,提供更有層次的資訊,幫助用戶更全面地思考政治議題。
最後,Podimata強調持續監測與研究的重要性,提醒我們AI技術的快速發展需要與時俱進的監管與學術支持。香港作為國際金融與資訊樞紐,同樣應關注AI在政治資訊領域的影響,推動透明、公正且負責任的AI應用。
總括而言,這項研究不僅是對AI技術的技術性檢視,更是對民主過程中資訊公正性的深刻反思,值得業界、學界及公眾共同關注。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。