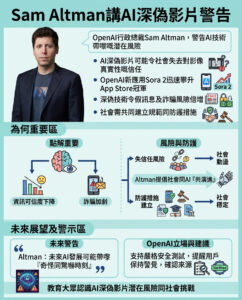
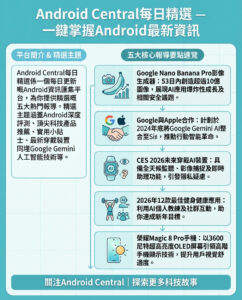
麻省理工學院(MIT)研發出更智能嘅大型語言模型計算分配方法,提升解難效能
麻省理工學院(MIT)嘅研究團隊最近開發咗一種新嘅技術,令大型語言模型(LLM)能夠根據問題嘅難度,動態調整推理時所用嘅計算資源。傳統上,模型通常會為每個問題設定固定嘅計算預算,無論問題係簡單定複雜,結果可能令模型喺簡單問題上浪費資源,或者喺複雜問題上計算不足。
MIT嘅新方法稱為「實例自適應擴展」(instance-adaptive scaling),佢能夠根據問題嘅難度同每個部分解決方案嘅成功機率,靈活調整模型嘅計算預算。研究顯示,呢個方法喺多個難度不一嘅問題上,能夠用到嘅計算量只係現有方法嘅一半,但準確度卻可媲美甚至優於傳統方法。更重要係,呢個方法令資源消耗較低嘅細模型喺複雜問題上,都可以媲美甚至超越大型模型嘅表現。
點解呢個技術重要?
推理計算嘅效率同準確度係推動生成式AI應用普及嘅關鍵。現時大型語言模型嘅推理成本高昂,限制咗佢哋喺時間敏感或高風險場景嘅應用。MIT團隊嘅技術可以減少能源消耗,令LLM更可靠同高效,為未來AI喺更多實際應用帶嚟可能。
技術原理簡介
新方法基於一種稱為「過程獎勵模型」(Process Reward Model, PRM)嘅技術,佢會評估每個推理步驟或解決方案嘅潛力,幫助語言模型決定應該集中資源喺邊啲解決方案上。傳統方法通常喺推理開始時就設定固定嘅計算資源,而MIT嘅方法係根據每一步嘅狀況動態調整,類似人類解難時會不斷評估自己嘅思路,決定繼續深入或者修正方向。
不過,PRM本身有時會過度自信,估計成功機率偏高。為咗解決呢個問題,研究人員引入咗一種校準方法,令PRM能夠產生一個成功機率嘅範圍,而唔係單一值,從而更準確反映模型嘅不確定性。呢個改良令動態計算調整更可靠,減少資源浪費嘅同時保持高準確度。
實驗效果
喺一系列數學推理任務中,MIT團隊嘅方法比起傳統推理時間擴展方法,用更少計算資源解決問題,卻保持同樣嘅準確率。佢哋強調,呢種調整係「即時」發生,隨著推理過程進行動態調節,而唔係預先一次過決定。
未來,團隊計劃將呢項技術應用喺代碼生成、AI代理人等領域,並探索PRM校準方法喺強化學習同模型微調嘅潛在用途。
專家評論
IBM軟件核心AI嘅總監Akash Srivastava指出,呢項研究係令AI代理人能夠識得自己唔識,並持續自我提升嘅重要一步。依家嘅AI代理人多數係靜態嘅概率模型,未能靈活適應新情況。呢種動態調整同不確定性管理能力,對於安全運行、適應新環境同維持穩定表現至關重要。
—
編輯評論:
MIT嘅呢項突破性研究,為大型語言模型嘅計算資源分配帶嚟新思維,特別係喺提升推理效率同準確度方面,展現咗實質嘅進步。傳統LLM無差別嘅「一刀切」計算分配,往往忽視問題嘅多樣性,導致資源浪費或者效率不足。實例自適應擴展技術,正正模仿咗人類解難嘅思維模式——先試探,再判斷,然後集中火力攻克最關鍵嘅部分。
呢種方法不但有助於降低AI系統嘅能源消耗,響應全球對環保嘅要求,更有助於將AI推向更多需要即時反應、計算資源有限嘅應用場景,例如醫療診斷、金融決策甚至自動駕駛。對於香港呢啲高密度都市,提升AI效率同時降低成本,亦係推動智慧城市發展嘅關鍵。
不過,PRM校準嘅準確性仍係未來技術優化嘅重要方向。如何令AI更準確判斷自己嘅「知識邊界」,對於避免「過度自信」導致嘅錯誤相當關鍵。呢點亦提醒我哋,AI系統嘅自我監控能力,將係下一代智能系統嘅核心競爭力。
總括而言,MIT呢項研究唔單止係技術層面嘅創新,更係人工智能「懂得自己唔識」嘅重要里程碑。未來隨著類似技術嘅成熟,AI將會變得更加靈活、高效同可靠,為香港同全球帶嚟更廣泛嘅實際應用可能。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。