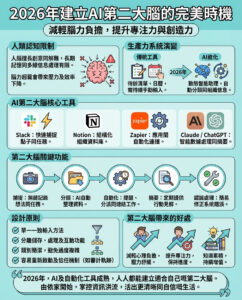
想設計未來汽車?這裡有8,000個設計幫助你起步。
麻省理工學院(MIT)的工程師們開發出全球最大的開源汽車設計數據集,涵蓋其空氣動力學,這將加速環保汽車和電動車的設計進程。
在這個包含超過8,000個汽車設計的新數據集中,MIT的工程師們模擬了特定汽車形狀的空氣動力學,並以多種形式展示,例如“表面場”。
每個數據集中的8,000個3D汽車設計都有多種表示方式,如參數化、點雲、3D網格、體積場、表面場、流線和部件註釋。因此,這個數據集可以被不同的AI模型使用,這些模型調整為處理特定形式的數據。
汽車設計是一個迭代和專有的過程。汽車製造商可能需要幾年時間來進行設計,通過模擬調整3D形狀,然後再對最有前途的設計進行實體測試。這些測試的細節和規格,包括特定汽車設計的空氣動力學,通常不會公開。因此,在燃油效率或電動車續航等性能方面的重大進展,往往是緩慢且孤立的。
MIT的工程師表示,利用生成性人工智能工具,尋找更好的汽車設計的過程可以指數級加快,這些工具能在幾秒鐘內分析大量數據,並找到連結來生成新設計。雖然這類AI工具已經存在,但它們所需的數據此前並未以任何可訪問的集中形式提供。
如今,工程師們首次向公眾提供了這樣的數據集。這個名為DrivAerNet++的數據集涵蓋超過8,000個汽車設計,這些設計基於當今世界上最常見的汽車類型生成。每個設計都以3D形式呈現,並包含汽車的空氣動力學信息——根據流體動力學模擬,描述空氣如何流過特定設計。
這個數據集是迄今為止開發的最大的開源汽車空氣動力學數據集。工程師們設想它可以作為一個廣泛的現實汽車設計庫,提供詳細的空氣動力學數據,以便快速訓練任何AI模型。這些模型隨後可以迅速生成新設計,這可能導致更高燃油效率的汽車和續航更長的電動車,所需時間僅是當前汽車行業的一小部分。
“這個數據集為下一代工程AI應用奠定了基礎,促進高效設計流程,降低研發成本,並推動邁向更可持續的汽車未來,” MIT機械工程研究生Mohamed Elrefaie表示。
Elrefaie和他的同事將在12月的NeurIPS會議上介紹一篇詳細說明新數據集和可應用的AI方法的論文。他的合著者包括MIT機械工程助理教授Faez Ahmed、慕尼黑工業大學計算機科學副教授Angela Dai和BETA CAE Systems的Florin Marar。
填補數據空白
Ahmed領導MIT的設計計算與數字工程實驗室(DeCoDE),該小組探索如何利用AI和機器學習工具來增強複雜工程系統和產品的設計,包括汽車技術。
“在設計汽車時,前期過程往往非常昂貴,因此製造商只能在每個版本之間進行小幅調整,” Ahmed表示。“但如果有更大的數據集,知道每個設計的性能,現在就可以訓練機器學習模型,以更快的速度進行迭代,從而更有可能獲得更好的設計。”
而且,尤其在推動汽車技術的過程中,速度變得尤為重要。
“現在是加速汽車創新的最佳時機,因為汽車是世界上最大的污染源之一,我們越快減少這種貢獻,就能越多幫助氣候,” Elrefaie說。
在研究新汽車設計的過程中,研究人員發現,雖然存在能夠快速處理多種汽車設計以生成最佳設計的AI模型,但實際上可用的汽車數據卻非常有限。之前一些研究者組建了小型的模擬汽車設計數據集,而汽車製造商則很少公開他們探索、測試和最終製造的實際設計的規格。
這個團隊希望填補數據空白,特別是與汽車的空氣動力學有關,因為這對設定電動車的續航和內燃機的燃油效率至關重要。他們意識到,組建一個包含數千個汽車設計的數據集,每個設計在功能和形式上都物理準確,而不需要實際測試和測量其性能是一個挑戰。
為了構建一個具有物理準確性的汽車設計數據集,研究人員從2014年Audi和BMW提供的幾個基準3D模型開始。這些模型代表三大類乘用車:快背式(後部有斜面設計的轎車)、缺口式(後部輪廓輕微下沉的轎車或跑車)和旅行車(如有更平坦後部的旅行車)。這些基準模型被認為填補了簡單設計和更複雜專有設計之間的空白,並被其他團隊用作探索新汽車設計的起點。
汽車資料庫
在新的研究中,團隊對每個基準汽車模型應用了一種變形操作。這一操作系統地對每個汽車設計的26個參數進行微調,例如長度、底盤特徵、擋風玻璃斜度和輪胎花紋,然後將其標記為一個獨特的汽車設計,並添加到日益增長的數據集中。與此同時,團隊運行了一個優化算法,以確保每個新設計確實是獨特的,而不是已生成設計的複製品。然後,他們將每個3D設計轉換為不同形式,以便將給定設計表示為網格、點雲或維度和規格的列表。
研究人員還運行了複雜的計算流體動力學模擬,以計算空氣如何流過每個生成的汽車設計。最終,這一努力產生了超過8,000個獨特且物理準確的3D汽車形狀,涵蓋當今道路上最常見的乘用車類型。
為了生成這個全面的數據集,研究人員在MIT SuperCloud上花費了超過300萬CPU小時,並生成了39TB的數據。(作為比較,據估計,整個國會圖書館的印刷收藏約為10TB的數據。)
工程師們表示,現在研究人員可以使用這個數據集來訓練特定的AI模型。例如,一個AI模型可以基於數據集的一部分進行訓練,以了解具有某些理想空氣動力學的汽車配置。在幾秒鐘內,該模型便可生成一個具有優化空氣動力學的新汽車設計,基於它從數以千計的物理準確設計中學到的知識。
研究人員還表示,這個數據集也可以用於反向目標。例如,在對數據集進行訓練後,設計師可以將特定汽車設計輸入模型,並快速估算該設計的空氣動力學,然後用來計算汽車的潛在燃油效率或電動續航——所有這些都無需進行昂貴的實體汽車建造和測試。
“這個數據集讓你能夠在幾秒鐘內訓練生成性AI模型,而不是幾小時,” Ahmed說。“這些模型可以幫助降低內燃機車輛的燃油消耗,並提高電動車的續航——最終為更可持續、環保的汽車鋪平道路。”
這項工作部分得到了德國學術交流署和MIT機械工程系的支持。
—
這項研究的意義不僅在於其技術創新,還在於它能夠顯著改變汽車設計的生態。隨著數據集的開放,越來越多的研究者和企業能夠利用這些資源,推動汽車技術的進步。這不僅能夠提高設計效率,還能促進可持續發展,對應對氣候變化的挑戰具有深遠的影響。未來,隨著AI技術的進一步發展,我們或許能夠見證更具創新性和環保的汽車設計出現,這將是全球汽車產業的一次革命。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。