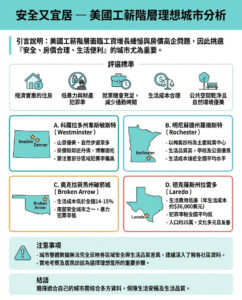
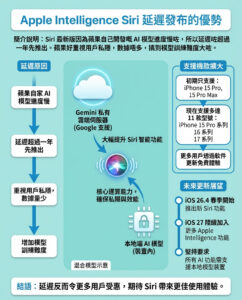
Meta AI推出EWE(明確工作記憶):一種增強長文本生成事實性的創新方法
大型語言模型(LLMs)已經徹底改變了文本生成的能力,但它們面臨著一個關鍵挑戰,即“幻覺”現象,特別是在長文本內容中生成事實不正確的信息。為了解決這一問題,研究人員開發了檢索增強生成(RAG)方法,通過將可靠來源的相關文檔納入輸入提示中來提高事實準確性。儘管RAG顯示出良好的潛力,各種迭代提示方法如FLARE和Self-RAG也陸續出現,以進一步提高準確性。然而,這些方法仍然受到傳統RAG架構的限制,其中檢索上下文是唯一集成到輸入字符串中的在線反饋形式。
傳統的文本生成方法經過幾個關鍵方法的演變,以提高事實準確性和上下文相關性。迭代檢索方法在生成回應時將其分段,每個段落利用新檢索到的信息。ITER-RETGEN就是這種方法的典範,通過使用先前的輸出來制定後續知識檢索的查詢。自適應檢索系統如FLARE和DRAGIN則通過實施基於信心的逐句生成來完善此過程。此外,長上下文的LLMs也探索了基於記憶的方法,例如Memory3,利用KV緩存作為記憶來編碼知識塊。其他系統如記憶變壓器和LongMem也對記憶檢索機制進行了實驗。
來自Meta FAIR的一組研究人員提出了EWE(明確工作記憶),這是一種創新的AI方法,通過實施動態工作記憶系統來增強長文本生成中的事實準確性。該系統獨特地整合了來自外部資源的實時反饋,並利用在線事實檢查機制不斷刷新其記憶。其主要創新在於能夠在生成過程中檢測和更正虛假聲明,而不僅僅依賴於事先檢索的信息。此外,EWE的有效性通過對四個事實尋求的長文本生成數據集的全面測試得到了證明,顯示出事實指標的顯著改善,同時保持回應質量。
EWE的架構代表了一個多功能的框架,可以根據不同配置進行調整,同時保持效率。其核心是EWE利用一個多單元記憶模塊,能在生成過程中動態更新。這一設計使得EWE可以在不同模式下操作,從使用單個記憶單元的簡單RAG到實施逐句驗證的FLARE類功能。與Memory3等相似的方法不同,EWE不需要預先編碼所有段落,並且在生成過程中具有動態記憶更新的獨特特性。這種靈活性使得EWE能夠通過不同的記憶單元進行平行處理各種形式的外部反饋。
實驗結果顯示,在多個數據集上,事實準確性有了顯著改善。使用Llama-3.1 70B基本模型,檢索增強始終提升事實性指標。雖然競爭對手的方法結果參差不齊,Nest僅在傳記數據集上表現良好,而DRAGIN的表現與基本檢索增強相似,但EWE在所有數據集上都達到了最高的VeriScore F1。儘管CoVe擁有高精度,但生成的回應較短,導致召回率較低。EWE在有用性方面的表現與基本模型相當,約有50%的勝率。
總結來說,Meta FAIR的一組研究人員推出的EWE(明確工作記憶)在解決長文本生成中的事實準確性挑戰方面代表了一次重要的進展。該系統創新的工作記憶機制,通過基於檢索和事實檢查反饋的定期暫停和記憶刷新運作,展示了生成更可靠的AI內容的潛力。這項研究確定了成功的關鍵因素,包括及時的記憶更新、集中注意力機制和高質量的檢索數據存儲,為未來事實文本生成系統的發展鋪平了道路。
這項研究的成果顯示,AI技術在生成文本的真實性方面越來越成熟,尤其是在長文本生成領域。EWE的出現不僅是技術上的突破,更是對事實性生成內容需求的響應。在信息過載的時代,能夠生成準確且可靠的文本將對社會各界產生深遠的影響,從新聞報導到學術研究,甚至日常的社交媒體交流。因此,未來的研究應該著重於如何進一步優化這些技術,以應對更為複雜的文本生成挑戰,同時考慮到道德和偏見等問題。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。