Meta被指操控AI基準測試
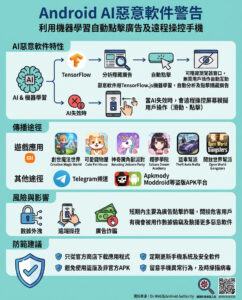
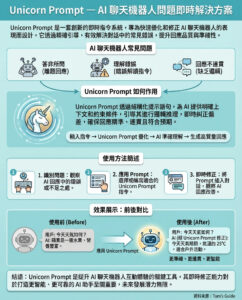
Meta最近推出了兩款全新的Llama 4模型:一款名為Scout的小型模型,以及一款中型模型Maverick,該公司聲稱Maverick在“廣泛報導的基準測試中”能夠超越GPT-4o和Gemini 2.0 Flash。
Maverick迅速在AI基準網站LMArena上取得了第二名的成績,該網站允許用戶比較不同系統的輸出並投票選出最佳者。在Meta的新聞稿中,公司強調了Maverick的ELO分數為1417,這使其高於OpenAI的4o,僅次於Gemini 2.5 Pro。(ELO分數越高,意味著該模型在與競爭對手的對抗中獲勝的次數越多。)
這一成就似乎使Meta的開放權重Llama 4成為與OpenAI、Anthropic和Google的封閉模型競爭的有力挑戰者。然而,隨著AI研究人員深入挖掘Meta的文檔,發現了一些不尋常的情況。
在細則中,Meta承認在LMArena上測試的Maverick版本並非公眾可用的版本。根據Meta自己的材料,該公司向LMArena提供了一個“實驗性聊天版本”的Maverick,該版本專門“針對對話性進行了優化”,這一點最早由TechCrunch報導。
“Meta對我們政策的解釋與我們對模型提供者的期望不符,”LMArena在模型發布兩天後在X上發布了聲明。“Meta應該更清楚地表明‘Llama-4-Maverick-03-26-Experimental’是一個為了優化人類偏好而定制的模型。由於這一點,我們正在更新我們的排行榜政策,以強化我們對公平、可重複評估的承諾,確保未來不再出現這種混淆。”
Meta的發言人在出版時未能對LMArena的聲明作出回應。
雖然Meta對Maverick所做的事情並不明確違反LMArena的規則,但該網站已經對操控系統表示擔憂,並採取措施以“防止過擬合和基準泄漏”。當公司可以提交專門調整的模型版本進行測試,而對公眾發布不同版本時,像LMArena這樣的基準排名就會變得不再具有指導現實性能的意義。
“這是最受尊重的一般基準,因為所有其他基準都不夠好,”獨立AI研究員Simon Willison告訴《The Verge》。他表示:“當Llama 4發布時,它在競技場中排名第二,僅次於Gemini 2.5 Pro——這讓我非常驚訝,我懊惱自己沒有仔細閱讀細則。”
在Meta發布Maverick和Scout後,AI社群開始傳言Meta也訓練其Llama 4模型以在基準測試中取得更好的表現,同時隱藏其實際的局限性。Meta的生成AI副總裁Ahmad Al-Dahle在X上回應了這些指控:“我們也聽說有人聲稱我們在測試集上進行訓練——這根本不是真的,我們不會這樣做。我們最好的理解是,人們所看到的變量質量是由於需要穩定實現。”
“這是一個非常混亂的發布。”
一些人還注意到Llama 4的發布時機有些奇怪。星期六通常不是重大AI新聞發布的時候。在Threads上,有人詢問為何Llama 4會在週末發布,Meta首席執行官馬克·祖克伯格回應道:“那是它準備好的時候。”
“這是一個非常混亂的發布,”Willison說,他密切關注並記錄AI模型。“我們在那裡得到的模型分數對我來說完全毫無價值。我甚至無法使用他們在高分上獲得的模型。”
Meta發布Llama 4的過程並不順利。根據《The Information》最近的報導,該公司多次推遲發布,因為該模型未能達到內部期望。在中國的一家開源AI初創公司DeepSeek發布了一個引起熱議的開放權重模型後,這些期望變得尤其高。
最終,在LMArena使用優化模型使開發者面臨困難的境地。在選擇像Llama 4這樣的模型用於應用時,開發者自然會查看基準測試以作為指導。然而,正如Maverick的情況所示,這些基準可能反映出公眾無法獲得的能力。
隨著AI開發的加速,這一事件顯示出基準測試正成為戰場。它也顯示出Meta渴望被視為AI領導者的心態,即使這意味著需要操控系統。
這一事件提醒我們,在AI技術快速發展的今天,企業在追求市場地位的過程中,應更加注重誠信和透明度。基準測試的公正性對於整個行業的健康發展至關重要,只有這樣,才能真正促進技術進步和公平競爭。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。