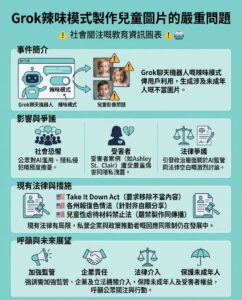
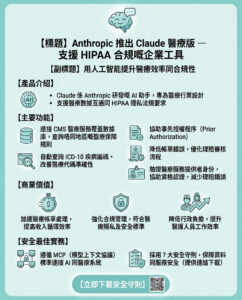
Google DeepMind研究開啟LLM嵌入在高級回歸中的潛力
大型語言模型(LLMs)透過引入新穎的回歸任務處理方法,徹底改變了數據分析的格局。傳統的回歸技術長期以來依賴手工特徵和領域專業知識來建模指標與所選特徵之間的關係。然而,這些方法在面對需要超越數字表示的語義理解的複雜、微妙數據集時常常力不從心。LLMs則通過利用自由形式的文本,提供了一種突破性的回歸方法,克服了傳統方法的局限性。在現代自然語言處理的時代,將先進的語言理解與強大的統計建模相結合,是重新定義回歸的重要關鍵。
現有的LLM基於回歸的研究方法在很大程度上忽視了服務型LLM嵌入作為回歸技術的潛力。雖然嵌入表示在檢索、語義相似性和下游語言任務中廣泛使用,但其在回歸中的直接應用仍需進一步探索。以往的方法主要集中在基於解碼的回歸技術,通過令牌抽樣生成預測。相對而言,基於嵌入的回歸提供了一種新穎的方法,通過使用成本效益高的後嵌入層(如多層感知器MLPs)進行數據驅動的訓練。然而,將高維嵌入應用於功能領域時,會出現重大挑戰。
來自斯坦福大學、谷歌及谷歌DeepMind的研究人員對基於LLM的嵌入回歸進行了全面的研究。他們的研究表明,LLM嵌入在高維回歸任務中可以超越傳統特徵工程技術。這項研究提供了一種新穎的回歸建模視角,通過使用固有保留Lipschitz連續性的語義表示來進行分析。此外,該研究旨在通過系統性分析LLM嵌入的潛力,彌合先進自然語言處理與統計建模之間的鴻溝。研究量化了關鍵模型特徵的影響,特別是模型規模和語言理解能力。
研究方法採用了精心控制的架構方法,以確保不同嵌入技術之間的公平和嚴謹比較。研究團隊使用了一致的MLP預測頭,並設置了兩個隱藏層及ReLU激活,保持使用均方誤差進行統一的損失計算。研究人員在不同的語言模型家族之間進行基準測試,特別是T5和Gemini 1.0模型,這些模型具有不同的架構、詞彙大小和嵌入維度,以驗證該方法的普遍性。最後,平均池化被採用作為聚合Transformer輸出的經典方法,以確保嵌入維度與前向傳遞後的輸出特徵維度直接對應。
實驗結果揭示了LLMs在各種回歸任務中的表現的迷人見解。對T5模型的實驗顯示,當訓練方法保持一致時,模型大小與性能之間存在明顯的正相關。相比之下,Gemini家族則顯示出更複雜的行為,大型模型並不一定能帶來更優越的結果。這種變異歸因於模型“配方”的差異,包括預訓練數據集、架構修改和後訓練配置的變化。研究發現,預訓練模型的默認前向傳遞通常表現最佳,儘管在特定任務(如AutoML、L2DA等)中改善有限。
總結來說,研究人員對LLM嵌入在回歸任務中的應用進行了全面探索,提供了對其潛力和局限性的重大見解。通過研究LLM嵌入基於回歸的多個關鍵方面,該研究揭示了這些嵌入對於具有複雜、高維特徵的輸入空間可能非常有效。此外,研究人員引入了Lipschitz因子分佈技術,以理解嵌入與回歸性能之間的關係。他們建議探索LLM嵌入在多種輸入類型中的應用,包括非表格數據(如圖形),並將該方法擴展至圖像和視頻等其他模態。
這項研究不僅展示了LLM在回歸分析中的潛力,也引發了我們對未來數據處理方法的思考。隨著數據的複雜性不斷增加,如何有效地將語言模型應用於更廣泛的數據類型將成為未來研究的關鍵挑戰。這種跨領域的融合不僅能提升數據分析的準確性,還可能推動人工智能技術在更多實際應用中的落地,對於我們理解和應用AI技術的未來意義深遠。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。