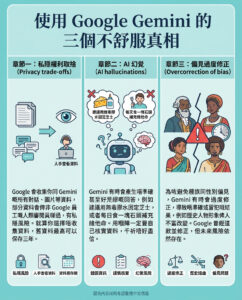
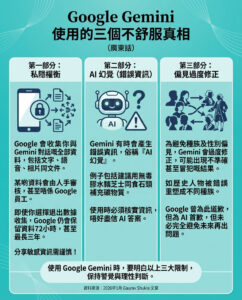
隱藏在大型語言模型與金融預測背後的統計數據
在這個生成式人工智能和大型語言模型(LLMs)佔據頭條新聞的時代,我們很容易忘記每個智能算法背後潛藏著一個意外的老派基礎:統計學。從大型語言模型如何預測你的下一個單詞,到銀行如何評估信用風險,像抽樣、平均數、方差和降維等統計原則靜靜地驅動著塑造我們未來的數字工具。
讓我們探討基本的統計方法,如描述性統計和推斷性統計,如何在構建大型語言模型中發揮重要作用,同時與金融機構在日常決策中使用這些相同概念之間進行比較。
抽樣:當你不能詢問每個人時,詢問幾個人
統計學家和機器學習工程師面臨著同樣的實際問題:你無法測量所有事物。因此,他們都轉向抽樣。
舉例來說,一家製藥公司在測試一種新藥時,無法將其施用於全世界的每一位患者。相反,他們會測試一個樣本,例如100位患者,並記錄每位患者恢復所需的時間。結果可能從2天到20天不等。這一範圍揭示了一個關鍵事實:範圍越大,對於該藥物平均有效性的強結論就越難得出。
這一挑戰在訓練語言模型時同樣存在。工程師使用大量數據集,但即使這些也僅僅是人類語言的樣本。模型必須從這個樣本中推斷出語言的更廣泛“族群”行為。
描述性統計與推斷性統計:你所知道的與你所猜測的
描述性統計幫助我們總結樣本中的觀察結果。在藥物試驗中,我們可能會說平均恢復時間為8天。但這並不等於說世界上平均患者的恢復時間也是8天。
這一從樣本到族群的跳躍,需要推斷性統計。推斷性統計涉及估計我們對研究結果能否推廣的信心。如果樣本顯示出較大的變異(2到20天),那麼我們對這8天的平均值的信心可能只有60%。觀察到的變異越少,我們的信心就越高。
在金融服務中,推斷性統計的用途也類似。假設一家銀行想預測借款人違約的可能性。它並不會分析每一位借款人,而是研究一個樣本。由此推斷出5%的違約概率。但這一信心取決於樣本的大小和一致性。樣本越小或噪音越大,估計的可靠性就越低。
異常值與平均數:當一個數字影響一切
讓我們重新回到藥物試驗。如果大多數患者在6到10天內恢復,但有一位患者需要30天,這一異常值會向上拉高平均值。新的平均數可能會暗示該藥物的有效性低於實際情況。
想像一下在一家金融科技公司,六名員工的平均薪水為45,000美元,但新任首席執行官的薪水為150,000美元。這樣一來,平均薪水上升至60,000美元,這就呈現出一個誤導的情況。因此,公司經常報告中位數。中位數對極端值的敏感度較低,提供了更準確的典型結果。
在大型語言模型中,異常值可能是一些不尋常的單詞或句子結構,如果不加以處理,可能會誤導模型。因此,訓練過程中常常涉及正則化和歸一化技術,這些方法根植於統計理論,以防止基於稀有範例的過擬合。
分佈、標準差與信心
變異與平均數一樣重要。一種恢復時間從2天到20天的藥物,可能與另一種恢復時間從7天到9天的藥物擁有相同的平均數,但第二種藥物會讓人感到更有信心。這種變異用標準差來衡量。
銀行對標準差也非常重視。兩個投資組合可能有相同的預期回報,但其中一個的風險(即回報的變異性)可能更大。理解這種波動性有助於投資組合經理做出更好的投資決策。
在大型語言模型中,變異有助於解釋預測中的不確定性。當模型生成多個潛在輸出時,這些結果的標準差可能指導模型對其答案的信心或僅僅是猜測。
偏斜分佈:並非所有數據都是對稱的
理解偏斜對於人工智能和金融都是至關重要的。一個完美對稱的數據集意味著平均數、中位數和眾數是相同的。但數據很少是完美的。右偏的分佈(例如,工資中有一個非常高的異常值)會將平均數拉高。左偏的曲線(例如,許多小損失和一個大收益)則會將其拉低。
在信用評分中,少數極具風險的借款人可能會扭曲平均風險指標。在大型語言模型中,如果數據高度重複,可能會使模型傾向於某些單詞或短語,除非得到適當的平衡。
降維:在不失去意義的情況下簡化複雜性
大型語言模型處理著龐大的數據集。屬性或特徵越多(想像一下電子表格中的列),訓練就變得越複雜。每一列都引入了新的關係,使得提取有意義的模式變得更加困難。
在金融領域,分析師在評估數百個客戶屬性時面臨同樣的問題。並非每一個數據點都是重要的。主成分分析(PCA)和特徵選擇等技術有助於將數據簡化到最重要的維度。
大型語言模型也一樣。工程師刪除冗餘或不相關的數據,以簡化學習並提高準確性。這在處理文本、圖像或音頻等非結構化數據時尤為重要,所有這些都必須轉換為結構化格式(如矩陣)後再提供給模型。
這對金融服務的重要性
儘管大型語言模型的內部運作可能感覺抽象,但其背後的數學在金融服務中有著直接的平行:
– 抽樣:用於市場調查和產品測試
– 平均數和中位數:用於薪酬基準和定價策略
– 標準差:用於風險管理和波動性評估
– 推斷性統計:用於從樣本數據預測趨勢
– 降維:用於KYC(了解你的客戶)和AML(反洗錢)系統,以優先考慮信號
在這兩個領域,目標是一樣的:根據不完整的信息做出明智的預測。
在每一個智能人工智能系統的背後,都有一個統計推理的支撐。隨著金融機構部署大型語言模型來提升客戶服務、自動化承保或檢測欺詐,決策者理解所涉及的統計機制至關重要。
因為在最終,無論是解釋語言還是平衡投資組合,這不僅僅是關於大數據,而是關於智能數據,以及使其有意義的統計學。
在這個充滿變化的金融科技時代,這些統計原理的深刻理解將成為企業成功的關鍵。隨著技術的進步,我們必須不斷適應和學習,才能在這個數據驅動的世界中保持競爭力。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。