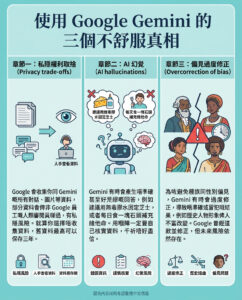
Hugging Face推出OlympicCoder:一系列能解決奧林匹克級編程問題的開放推理AI模型
在競爭性編程的領域中,人類參賽者和人工智能系統都面臨著一系列獨特的挑戰。許多現有的代碼生成模型在解決複雜的奧林匹克級問題時,往往無法穩定地滿足高標準。經常出現的問題是難以處理長鏈推理,這常常導致解決方案只能通過簡化的測試用例,而在更嚴格的比賽條件下失敗。當前可用的數據集通常僅捕捉到CodeForces等平台或國際競賽(例如國際信息學奧林匹克賽(IOI))上所見問題的一部分。因此,需要能夠生成語法正確代碼的模型,並遵循一條邏輯推理路徑,這與實際比賽中所需的謹慎思考過程相符。
認識OlympicCoder
Hugging Face最近推出了OlympicCoder,這是一系列專門設計用來應對奧林匹克級編程挑戰需求的模型。該系列包含兩個經過微調的模型——OlympicCoder-7B和OlympicCoder-32B,這些模型使用一個精心策劃的數據集CodeForces-CoTs進行了精細調整,該數據集包含近10萬個高質量的鏈推理樣本。值得注意的是,這些模型在解決IOI問題上超越了像Claude 3.7 Sonnet等封閉源前沿模型,證明了開源模型能夠與甚至超越更大型的專有系統的性能。通過將詳細的解釋和多個正確解決方案整合到訓練數據中,OlympicCoder模型能夠充分應對涉及複雜推理和問題解決的編碼任務的細微差異。
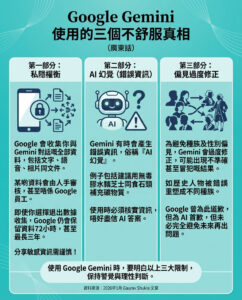
技術細節與優勢
OlympicCoder-7B和OlympicCoder-32B都建立在Qwen2.5-Coder Instruct模型的基礎上,並使用經過去污的CodeForces數據集進行了精細調整。例如,OlympicCoder-7B擁有大約76億個參數,訓練時未使用樣本打包——這是一種可能意外截斷長推理鏈的技術。相反,訓練過程使用了4e-5的較高學習率,並結合了餘弦學習率調度器,確保長上下文的解決方案得到保留和充分利用。同時,OlympicCoder-32B是一個擁有約328億個參數的更大模型,利用分佈式訓練方法,專注於維持長上下文窗口。這些技術調整使得模型能更好地適應長而複雜的推理序列,這對於準確應對競爭性編程中呈現的多層次挑戰至關重要。
結果與見解
這些模型的性能在LiveCodeBench和IOI 2024問題等基準上進行了評估。在這些評估中,模型經歷了模擬實際比賽條件的嚴格提交策略,為每個子任務生成多個提交。這種方法確保選擇最連貫的鏈推理進行評估。評估結果確認,OlympicCoder-7B和OlympicCoder-32B不僅提供了強勁的性能,尤其是在32B模型的情況下,還超越了一些領先的封閉源系統。詳細分析表明,避免樣本打包和應用較高的學習率是提升性能的關鍵因素,而使用精心策劃的數據集則有助於捕捉競爭性編程問題的複雜性。
結論
總結來說,OlympicCoder代表了在競爭性編程領域開發開放推理模型的一個深思熟慮的進步。這兩個經過微調的模型在與更大、封閉源系統的競爭中表現出色,展示了如何通過仔細的數據集策劃和有條理的微調,實現代碼生成的顯著進步。OlympicCoder為研究人員和從業者提供了寶貴的見解,為未來AI驅動的問題解決創新鋪平了道路,同時保持對模型開發的平衡和嚴謹的態度。
在Hugging Face上查看7B模型和32B模型及其技術細節。所有研究的功勞都歸於這個項目的研究人員。還請隨時在Twitter上關注我們,並別忘了加入我們的80k+ ML SubReddit。
—
這篇文章充分展示了開源AI模型在解決複雜問題上的潛力,尤其是在競爭性編程的領域。OlympicCoder的推出不僅是對現有技術的一次進步,更是對未來AI發展方向的深刻反思。隨著AI技術的日益成熟,如何平衡開源與封閉源系統的優勢,將成為未來研究的重要課題。這提醒我們,在追求技術創新時,應該更加注重其社會影響和實際應用,確保技術能夠真正為用戶帶來價值。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。