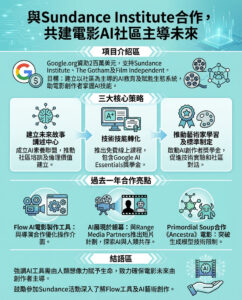
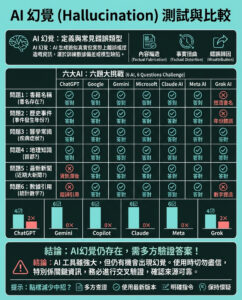
Google AI 研究介紹 Titans:一種新型機器學習架構,擁有注意力機制和元上下文記憶,能夠在測試時學習如何記憶
大型語言模型 (LLMs) 基於 Transformer 架構,通過其卓越的上下文學習能力和有效的擴展能力,徹底改變了序列建模。然而,這些模型的注意力模塊作為關聯記憶塊,存儲和檢索關鍵-值關聯,但其計算需求隨著輸入長度的增長而呈平方增長,這在處理語言建模、視頻理解和長期時間序列預測等現實應用時,會帶來重大的挑戰,因為上下文窗口可能變得極其龐大,從而限制了 Transformer 在這些關鍵領域的實際適用性。
研究人員探索了多種方法來解決 Transformer 的計算挑戰,主要分為三個類別。首先,線性遞歸模型因其高效的訓練和推理而受到關注,這些模型從像 RetNet 和 RWKV 這樣的第一代模型演變而來,使用數據獨立的轉換矩陣,並發展到第二代架構,加入了像 Griffin 和 RWKV6 的門控機制。其次,基於 Transformer 的架構試圖通過 I/O 感知實現、稀疏注意力矩陣和基於內核的方法來優化注意力機制。最後,增強記憶的模型專注於持久和上下文記憶設計。然而,這些解決方案往往面臨記憶溢出、固定大小限制等問題。
谷歌研究人員提出了一種新型神經長期記憶模塊,旨在增強注意力機制,允許訪問歷史上下文,同時保持高效的訓練和推理。這一創新在於創建一個互補系統,其中注意力作為短期記憶,能夠在有限上下文中進行精確的依賴建模,而神經記憶組件則作為持久信息的長期存儲。這種雙重記憶方法形成了一個名為 Titans 的新架構系列,該系列有三個變體,各自提供不同的記憶整合策略。該系統在處理極長上下文方面顯示出特別的潛力,成功處理超過 200 萬個標記的序列。
Titans 架構引入了一種複雜的三部分設計,以有效整合記憶能力。該系統由三個不同的超頭組成:一個核心模塊利用有限窗口大小的注意力進行短期記憶和主要數據處理,一個長期記憶分支實現神經記憶模塊以存儲歷史信息,以及一個持久記憶組件,包含可學習的數據獨立參數。該架構實現了多項技術優化,包括殘差連接、SiLU 激活函數和查詢及鍵的 ℓ2 範數歸一化。此外,它在查詢、鍵和值投影後使用一維深度可分離卷積層,並結合了正規化和門控機制。
實驗結果顯示,Titans 在多種配置下的性能優越。三個變體 MAC、MAG 和 MAL 的表現均超過了像 Samba 和 Gated DeltaNet-H2 這樣的混合模型,其中神經記憶模塊被認為是主要的區別因素。在這些變體中,MAC 和 MAG 在處理長期依賴性方面表現尤為強勁,超過了在現有混合模型中常用的 MAL 風格組合。在針對「針在干草堆中」(NIAH) 任務中,Titans 的表現優於從 2K 到 16K 標記的基線。這一優越的性能源於三個主要優勢:高效的記憶管理、深度非線性記憶能力和有效的記憶抹除功能。
總結來說,谷歌研究人員介紹了一個突破性的神經長期記憶系統,作為一個元上下文學習者,能夠在測試時進行自適應記憶。這一循環模型在識別和存儲數據流中的驚人模式方面更為有效,提供了比傳統方法更為複雜的記憶管理。該系統在處理大範圍上下文方面的優越性,通過在 Titans 架構系列中實現三個不同的變體得以證明。其能夠有效處理超過 200 萬個標記的序列,同時保持卓越的準確性,標誌著序列建模領域的一項重大進展,並為處理日益複雜的任務開啟了新可能性。
在這篇文章中,谷歌的研究成果展示了機器學習領域的一次重要突破,尤其在面對日益增長的數據處理需求時,這種新的 Titans 架構能夠提供更高效的解決方案。未來,隨著數據規模的擴大,如何持續優化這些模型以應對更廣泛的應用場景,將是研究者們需要面對的挑戰。這不僅是對技術的挑戰,更是對我們如何理解和利用人工智能的重新思考。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。