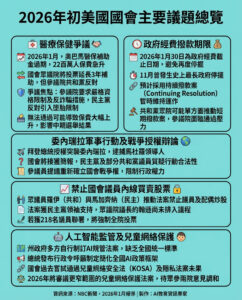
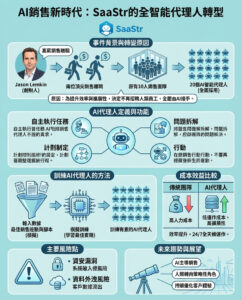
DeepSeek開源其R1推理模型系列
DeepSeek今日推出了一系列新的大型語言模型,名為R1系列,專為推理任務而優化。
這家中國人工智能開發公司已在Hugging Face上公開了這些算法的源代碼。
這個大型語言模型的陣容以兩個算法為主,分別是R1和R1-Zero。根據DeepSeek的說法,前者在多個推理基準測試中超過了OpenAI的o1模型。另一方面,R1-Zero的能力較弱,但在機器學習研究中可能代表了一個重要的進步。
這兩個大型語言模型均採用了混合專家(MoE)架構,擁有6710億個參數。MoE模型由多個神經網絡組成,每一個都針對不同的任務進行優化。當模型接收到提示時,名為路由器的機制會將查詢發送到最適合處理該查詢的神經網絡。
MoE架構的主要優點是降低推理成本。當用戶在MoE模型中輸入提示時,查詢並不會激活整個AI,而僅激活生成回應的特定神經網絡。因此,R1和R1-Zero在回答提示時,激活的參數不到其6710億個的十分之一。
DeepSeek使用了一種與研究人員通常用於推理模型的不同方法來訓練R1-Zero。
優化推理的大型語言模型通常使用兩種方法進行訓練,分別是強化學習和監督性微調。前者通過試錯法教導AI模型執行任務,而監督性微調則通過提供執行任務的示例來提高AI的輸出質量。
在訓練R1-Zero時,DeepSeek跳過了監督性自我調整階段。儘管如此,公司仍然成功賦予該模型推理能力,例如將複雜任務分解為更簡單的子步驟的能力。
“這是首次公開研究驗證了大型語言模型的推理能力可以純粹通過強化學習來激勵,而無需監督性微調,”DeepSeek的研究人員詳細說明道。“這一突破為未來在這一領域的進步鋪平了道路。”
儘管R1-Zero擁有先進的功能集,但其輸出質量仍然有限。該模型的回應有時會出現“無休止的重複、可讀性差和語言混合”等問題,DeepSeek的研究人員詳細說明。公司因此創建了R1來解決這些限制。
R1是R1-Zero的增強版本,使用了一種修改過的訓練流程進行開發。這個流程利用了監督性微調這一技術,而這正是DeepSeek在R1-Zero的開發中省略的。公司表示,這一改變顯著提高了輸出質量。
DeepSeek將R1與四個流行的LLM進行比較,使用了近二十種基準測試。根據公司的說法,其模型在多個基準測試中超過了OpenAI的推理優化o1 LLM。在o1得分更高的大多數基準測試中,R1的差距不到5%。
在R1超越o1的基準之一是LiveCodeBench。這是一組編程任務,定期更新新練習問題,這使得AI模型不太可能在公共網絡上找到現成的問題答案。
除了R1和R1-Zero,DeepSeek今天還開源了一組能力較弱但更具硬件效率的模型。這些模型是從R1“蒸餾”而來,這意味著在訓練過程中將部分LLM的知識轉移給它們。
這些蒸餾模型的大小範圍從15億到700億個參數。它們基於Llama和Qwen開源LLM系列。DeepSeek表示,其中一個蒸餾模型R1-Distill-Qwen-32B在多個基準測試中超過了縮小版的OpenAI-o1-mini版本。
—
在這次DeepSeek的開源行動中,我們可以看到中國在人工智能領域的迅速發展,尤其是在推理能力方面的突破。這不僅顯示了他們在技術創新上的潛力,也可能促使全球的AI研究社群進一步探索和利用開源資源。值得注意的是,這些新模型在推理能力上雖然有所提升,但仍然面臨著可讀性等質量挑戰,顯示出AI技術的成熟仍需時日。這一進展不僅影響著商業應用,也可能在教育、醫療等多個領域中引發變革。未來,隨著這類技術的普及和進步,如何平衡其能力與倫理問題將成為重要的討論話題。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。