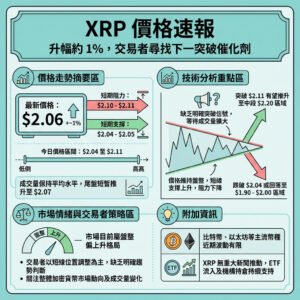
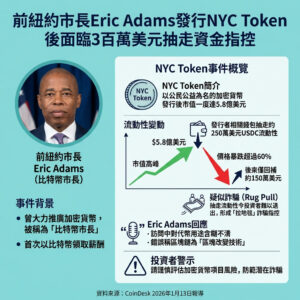
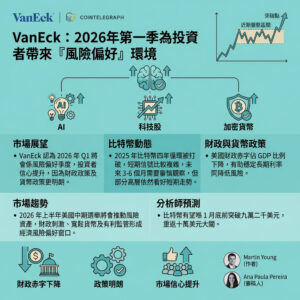
中國DeepSeek推出新開源AI,Prover V2專注於數學定理驗證
中國人工智能開發公司DeepSeek最近推出了一個新的開放權重大型語言模型(LLM)——Prover V2。該模型於4月30日上傳至Hugging Face的托管服務,並以MIT開源許可證發布,旨在解決數學證明的驗證問題。
Prover V2擁有6710億個參數,顯著大於其前身Prover V1和Prover V1.5,後者於2024年8月發布。第一版的論文解釋了該模型是如何使用Lean 4編程語言將數學競賽問題轉換為形式邏輯的,這種工具在證明定理時被廣泛使用。
開發者表示,Prover V2將數學知識壓縮成一種格式,使其能夠生成和驗證證明,這可能對研究和教育有所幫助。
這一切意味著什麼?
在AI領域,模型通常被非正式且不正確地稱為“權重”,它是一組文件,允許用戶在本地執行AI,而無需依賴外部伺服器。然而,值得指出的是,最先進的LLM需要的硬件超過了大多數人所能接觸到的。
這是因為這些模型通常擁有大量參數,導致文件龐大,需要大量的RAM或VRAM(GPU記憶體)和處理能力來運行。新的Prover V2模型約重650GB,預計將從RAM或VRAM運行。
為了將模型壓縮到這個大小,Prover V2的權重已被量化至8位浮點精度,這意味著每個參數的空間被近似為通常16位的一半,而位元則是二進位數字中的單一數字。這樣有效地減少了模型的體積。
Prover V1基於擁有70億參數的DeepSeekMath模型,並在合成數據上進行了微調。合成數據是指用於訓練AI模型的數據,這些數據本身也是由AI模型生成的,而人類生成的數據通常被視為越來越稀缺的高質量數據來源。
據報導,Prover V1.5在優化訓練和執行方面改善了前一版本,並在基準測試中達到了更高的準確性。到目前為止,Prover V2所帶來的改進尚不明確,因為在撰寫時尚未發布任何研究論文或其他信息。
Prover V2的權重參數數量表明,它可能基於該公司的前一個R1模型。R1首次發布時在AI領域引起轟動,其性能與當時最先進的OpenAI的o1模型相當。
開放權重的重要性
公開發布LLM的權重是一個有爭議的話題。一方面,它是一種民主化力量,使公眾可以在自己的條件下訪問AI,而無需依賴私營公司的基礎設施。
另一方面,這意味著公司無法介入並防止模型的濫用,無法對危險的用戶查詢施加某些限制。以這種方式發布的R1引發了安全擔憂,有人將其描述為中國的“斯普特尼克時刻”。
開源支持者欣喜地看到DeepSeek繼續了Meta在其LLaMA系列開源AI模型發布時的努力,證明開放AI是對OpenAI封閉AI的嚴重競爭者。這些模型的可獲得性也在不斷改善。
可接觸的語言模型
現在,即使是那些無法接觸到超級計算機的用戶,也能在本地運行LLM,這主要得益於兩種AI開發技術:模型蒸餾和量化。
蒸餾是指訓練一個緊湊的“學生”網絡,以複製更大“教師”模型的行為,從而在減少參數的同時保留大部分性能,使其能夠在較弱的硬件上運行。量化則是通過減少模型權重和激活的數字精度來縮小大小,並提高推理速度,僅有輕微的準確性損失。
例如,Prover V2將浮點數從16位減少到8位,但進一步的減少也是可能的,通過進一步減半位數來實現。這兩種技術對模型性能有影響,但通常不會影響模型的主要功能。
DeepSeek的R1被蒸餾成多個版本,這些版本使用重新訓練的LLaMA和Qwen模型,參數範圍從70億到最低1.5億。這些最小的模型甚至可以在某些移動設備上可靠運行。
在這個快速發展的AI領域,DeepSeek的最新舉措不僅展示了中國在開源AI方面的潛力,也引發了對AI技術安全性和可持續性的廣泛討論。隨著開源AI的逐步普及,未來的挑戰將是如何平衡技術進步與倫理責任之間的關係。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。