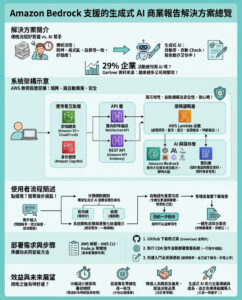
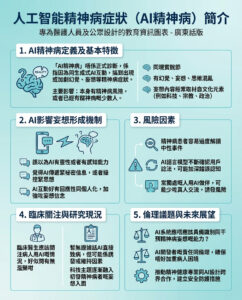
Cloudflare大規模網絡故障影響多個熱門網站及服務
周二,全球網絡出現大規模中斷,原因是網絡安全公司Cloudflare發生故障,導致用戶無法訪問包括X(前Twitter)、ChatGPT、Spotify、YouTube及Uber等多個知名網站和服務。Cloudflare隨後發佈官方博客詳細解釋事件經過。
Cloudflare聯合創辦人兼行政總裁Matthew Prince在周二晚間發文道歉,表示這次故障是自2019年以來公司遇到最嚴重的一次。他說:「過去六年多來,我們未曾遇過令核心流量大規模中斷的故障。代表Cloudflare全體團隊,我為今日給互聯網帶來的影響深表歉意。」
故障成因:防禦機制出錯導致系統癱瘓
Cloudflare解釋,故障源自其用於防範DDoS攻擊的「Bot Management」系統出現問題。這項系統利用人工智能模型對訪問網站的流量進行評分,判斷是否來自機械人攻擊。評分依據的是一份名為「feature file」的資料檔案,該檔案每五分鐘更新一次,以反映最新的機械人行為。
問題出在Cloudflare對生成該檔案的查詢語句做了修改,導致資料重覆過多,令檔案異常膨脹,最終觸發Bot Management系統錯誤。結果是,使用該系統保護的網站用戶在訪問時均遇到錯誤代碼。Cloudflare網絡在更新檔案約15分鐘後開始出現大規模故障。
起初Cloudflare懷疑這次故障是惡意攻擊,因為其獨立運作的狀態頁面也同時宕機,但後來證實兩者只是巧合。Prince強調:「這次問題並非由任何形式的網絡攻擊或惡意行為引起。」Cloudflare隨後停止了異常的檔案更新,並恢復使用先前版本。
整體服務在約三小時內逐步恢復,五小時後完全恢復正常。Cloudflare表示,將採取措施防止類似錯誤再次導致系統癱瘓,包括改進錯誤報告機制,防止系統被淹沒。
—
編輯評論:技術巨頭的系統脆弱性與網絡生態的信任危機
這次Cloudflare的故障,揭示了當今網絡基礎設施的高依賴性與脆弱性。作為全球多個頂尖網站的安全防護核心,Cloudflare的Bot Management系統出錯,立即引發了大範圍的網絡中斷。此事件提醒我們,即使是技術領先的安全公司,也難免因一個小小的軟件更新錯誤,導致嚴重後果。
此外,這次故障亦反映出網絡生態系統中「單點失效」的風險。大量關鍵服務集中依賴少數幾家基礎設施供應商,一旦這些節點出問題,影響便會快速擴散至全球用戶。未來,如何在確保安全的同時,實現更分散、彈性的網絡架構,將是業界必須面對的課題。
同時,企業在推行系統更新時,必須加強測試和監控,尤其是涉及AI和自動化決策的部分,因為這些系統的複雜性和不確定性遠超傳統軟件。Cloudflare承諾會防止類似問題重演,這是必須的,也希望其他企業能從中吸取教訓,提升整體網絡韌性。
最後,這場故障也提醒用戶,網絡服務的穩定性非理所當然,面對網絡中斷時應有心理準備,並適當分散依賴,避免生活和工作受單一平台影響過大。科技進步固然帶來便利,但同時也伴隨著風險,這是我們共同需要正視的現實。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。