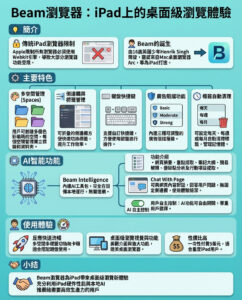
ChatGPT-5 實戰極限測試:5 個超難題目即刻挑戰
ChatGPT-5 被譽為「更聰明」、「更有理性」及「可即時投入生產使用」的 AI 模型,但這些說法在實際應用中到底有多真確?本文就親身測試,利用五個嚴苛題目,全面考驗這款由 OpenAI 打造的強大 AI,重點在於精準度、驗證能力,以及嚴格遵守限制條件的表現。不是精挑細選的示範,而是任何人都能重現的標準化挑戰,方便比較。
測試計劃如下:
– 用數學題—一個需完整因數分解邏輯及自我檢查的數論難題。
– 用科學題—一個需推導公式、計算實數和單位檢查的物理問題。
– 用 Vibe Coding—製作一個簡潔的單文件日程規劃器,兼顧用戶體驗、無障礙及資料持久化。
– 用程式編寫—實作一個串流數據的第95百分位估計器,不能靠簡單數組蒙混過關。
– 用歷史題—一個重視證據而非自信猜測的論證,並附帶嚴謹引用。
每個題目都規定了嚴格的輸出格式、審核步驟和失敗標準,方便看出 GPT-5 哪裡強、哪裡弱。
你也可以用這些題目自我測試,甚至拿 GPT-5 和較早期的 AI(如 Gemini、Claude)對比,評分重點包括:準確性、推理透明度、對極端案例的韌性,以及對指令的忠實度。若你想評估大型語言模型(LLM)在真實工作中的表現,這套測試絕對是最佳試金石。
—
1. 數學:數論+限制條件檢查
題目:找出所有正整數有序三元組 (a, b, c),滿足以下條件:
– lcm(a,b) = 840
– lcm(a,c) = 1260
– gcd(b,c) = 6
– a 是質數
輸出要求嚴格:
1. 列出所有符合條件的三元組。
2. 用不超過120字的簡潔說明,搭配質因數 2,3,5,7 的表格,解釋為何不會有其他質數。
3. 機械檢查:計算每組的 gcd 和 lcm,驗證三個等式(並展示數字)。
4. 若有多組,說明數量;無則寫「none」。
重點:精確因數推理、窮舉邏輯、自我驗證。
結果:ChatGPT-5 花了近1分鐘完成回答。
—
2. 科學:封閉式物理公式+數值計算+單位檢查
題目:一名質量 m=80kg 的跳傘者,截面積 A=0.70m²,阻力係數 Cd=1.0,空氣密度 ρ=1.225kg/m³。
(a) 寫出帶有二次阻力的垂直運動微分方程,並求解 v(t)。
(b) 計算終端速度 vt。
(c) 計算達到 vt 95% 所需時間。
輸出要求:公式 → 數值解帶單位 → 三行單位檢查 → 一句假設說明(如空氣密度不變)。數學推導不超過10行。
重點:符號推導、數值計算、單位嚴謹、假設清晰。
結果:ChatGPT-5 花了約45秒思考後回答。
—
3. Vibe Coding:一次性完成微型應用(設計+UX+程式碼)
題目:做一個「Top 3 + Secondary」每日計劃器,單一 HTML 檔案,具備:
– Top 3 任務區和次要任務列表。
– 勾選 Top 3 任務時顯示有趣短句(不用表情符號)。
– 使用純 JS + Tailwind CDN。
– 支援 localStorage 持久化,含清除當日按鈕。
– 鍵盤友好(tab/enter)、可訪問標籤、響應式設計。
– 不使用外部 API、無追蹤、無框架。
重點:產品感、程式碼質量、無障礙設計、在嚴格限制下完成度。
結果:ChatGPT-5 花了1分40秒思考並完成編碼。
—
4. 程式編寫:串流算法+正確性證明草案
題目:用 Python 實作一個串流第95百分位估計器,採用 P²(P-squared)算法。
要求:
– 純 Python,無外部庫,能處理負數、重複值,設計可支援 10^7 項資料,記憶體安全。
– 實作類別 P2Quantile(q=0.95),含 update(x) 和 result() 方法。
– 包含小測試:串流 10萬隨機值,列印估計值與精確值(最後計算);3個邊界案例(全部相同值、重尾分布、遞增輸入)。
– docstring 中簡述時間/空間複雜度及失效情況,簡潔(不超120字)。
重點:算法深度、串流數字處理、測試、清晰 API。
結果:ChatGPT-5 花了1分37秒思考後開始寫碼,初版有錯誤,修正後才完成。
—
5. 歷史:證據嚴謹+細膩論述+避免虛構
題目:認真歷史學家身份回答,並只用可驗證資料。
問題:公元476年西羅馬帝國「滅亡」是突然崩潰,還是長期轉型?同時兼顧東羅馬帝國情況。
輸出要求:
1. 370–610年間 10 個重要時間點(每點一句意義)。
2. 一段論點(2–3句)+3個最強反駁(各一句)。
3. 3–5 個具體真實的學術引用(作者、書名、年份、出版社或期刊),不確定不寫。
4. 最後一句「信心水平與限制」說明(不超80字)。
重點:杜絕虛構、綜合論述、平衡觀點。
結果:ChatGPT-5 花約1分34秒思考後輸出。
—
總結:
這次 ChatGPT-5 極限測試非為秀技術,而是實戰檢驗。五個題目涵蓋數學推理、科學推導與單位檢查、微型應用產品編碼、串流算法實作,以及嚴謹歷史論證,全面展現 GPT-5 在邏輯推理、程式設計質量、產品感知和證據紀律上的優勢,同時也暴露出執行時間和程式碼錯誤的現實問題。
你可以直接複製題目,配合簡單評分標準(準確性、自檢、速度、可重現性、引用品質),不斷重跑,或拿來和其他大型語言模型(Claude、Gemini、Llama、Qwen)比較。
結論:如果你對 prompt 工程、AI 生產力或大型語言模型評估有興趣,這套壓力測試是一個快速且可重複的實戰工具,幫助你真正了解 GPT-5 在關鍵任務上的表現。試試看,記錄結果並分享心得,未來升級或部署決策會更明智、更安全。
—
編輯評論與深入思考:
這篇文章以五個極具挑戰性的任務,從不同角度全面檢驗了 ChatGPT-5 的能力。它不單是展示 AI 智能的花瓶,而是貼近真實工作場景的嚴苛考核。尤其令人欣慰的是,GPT-5在邏輯推理和嚴謹性上已有明顯進步,能處理複雜數學和科學推導,並兼顧用戶體驗和無障礙設計的程式碼生產。
然而,從程式碼錯誤和執行時間來看,AI 仍非完美無缺。這提醒我們,AI輔助工具最終仍需人類審核、優化和監管。特別是對於需要精準數據、科學嚴謹或法律責任的場景,AI的答案不能盲目接受。
此外,歷史題目中對資料來源的嚴格要求,展現了防止 AI「虛構」的必須性。未來 AI 走向更成熟,必須在創造力與真實性間找到平衡。
從策略層面看,這種多面向壓力測試框架值得推廣,能幫助企業和研究者在選擇和部署 AI 時有更科學的依據。對於香港及華語用戶,這類標準化測評亦可促進本地 AI 生態的成熟,避免被過度吹捧的技術誤導。
總括而言,ChatGPT-5 的進展令人期待,但仍需謹慎使用。未來的發展可望在效率與準確性間取得更佳平衡,並帶來更廣泛的應用可能。這種實戰測試正是推動 AI 技術向前的關鍵一步。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。