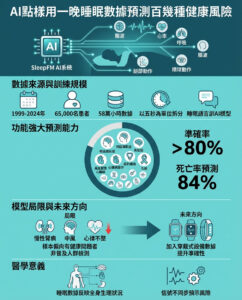
AWS 建設 ExaFLOPS 級超級電腦,無需 Nvidia GPU
當我們談論擁有數十萬甚至數十萬個處理器的人工智慧超級電腦時,通常指的是由 Nvidia 的 Hopper 或 Blackwell GPU 驅動的系統。然而,Nvidia 並不是唯一針對極具需求的 AI 超級電腦的公司,亞馬遜網絡服務(AWS)本週表示,它正在建設一台擁有數十萬個自家 Trainium2 處理器的機器,預計能夠達到約 65 ExaFLOPS 的 AI 性能。該公司還推出了 Trainium3 處理器,性能將是 Trainium2 的四倍。
AWS Trainium2 是亞馬遜的第二代 AI 加速器,專為基礎模型(FMs)和大型語言模型(LLMs)設計,由亞馬遜的 Annapurna Labs 開發。這個單元是一種多瓦片系統封裝,擁有兩個計算瓦片、96GB 的 HBM3 記憶體(使用四個堆疊)和兩個靜態芯片,以確保封裝一致性。去年 AWS 推出 Trainium2 時,並未分享具體的性能數據,但表示 Trn2 實例可擴展至 100,000 個處理器,為 AI 提供 65 ExaFLOPS 的低精度計算性能,這意味著單顆芯片可提供高達 650 TFLOPS 的性能。不過,這看起來是一個保守的估計。
在 2024 年的 re:Invent 大會上,AWS 針對 Trainium2 發布了三個相關公告:
首先,基於 AWS Trainium2 的 Amazon Elastic Compute Cloud(Amazon EC2)EC2 Trn2 實例現在已經普遍可用。這些實例配備了 16 個 Trainium2 處理器,通過 NeuronLink 互聯技術實現性能高達 20.8 FP8 PetaFLOPS,並擁有 1.5 TB 的 HBM3 記憶體,峰值帶寬達到 46 TB/s。這基本上表明,每個 Trainium2 提供高達 1.3 PetaFLOPS 的 FP8 性能,這是去年的數字的兩倍。也許 AWS 找到了優化處理器性能的方法,或者之前提到的是 FP16 數字,但 1.3 PetaFLOPS 的 FP8 性能與 Nvidia H100 的 1.98 PetaFLOPS 性能(不考慮稀疏性)相當。
其次,AWS 正在建設 EC2 Trn2 UltraServers,這些伺服器擁有 64 顆互聯的 Trainium2 芯片,提供 83.2 FP8 PetaFLOPS 的性能,還有 6 TB 的 HBM3 記憶體,峰值帶寬達到 185 TB/s。這些機器使用 12.8 Tb/s 的 Elastic Fabric Adapter(EFA)網絡進行互聯。
最後,AWS 和 Anthropic 正在建設一個巨型的 EC2 UltraCluster,代號為 Project Rainier。該系統將由數十萬個 Trainium2 處理器驅動,提供的 ExaFLOPS 性能是 Anthropic 目前用於訓練其領先 AI 模型(如 Sonnet 和 Opus)的五倍。預計該機器將連接第三代低延遲、千兆級 EFA 網絡。
AWS 沒有透露 EC2 UltraCluster 將使用多少 Trainium2 處理器,但假設 Trn2 實例的最大擴展性為 100,000 個處理器,這意味著該系統的性能約為 130 FP8 ExaFLOPS,這是相當可觀的,相當於約 32,768 顆 Nvidia H100 處理器。
評論
AWS 在 AI 超級電腦領域的進一步發展顯示了其對於不依賴 Nvidia 硬件的強烈意圖,這不僅是出於成本考量,還是為了在市場上尋求更大的自主權。Trainium2 的推出和未來的 Trainium3 使得 AWS 成為一個極具潛力的競爭者,特別是在大型模型訓練和推理方面。
隨著 AI 技術的不斷演進,對計算資源的需求日益增加,AWS 的新型伺服器和處理器無疑會吸引更多的開發者和企業進一步探索這一領域。這不僅是對 Nvidia 的挑戰,更是對整個 AI 生態系統的重新定義。未來幾年,隨著越來越多的公司開始尋求替代方案,這場競爭將會越來越激烈。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。