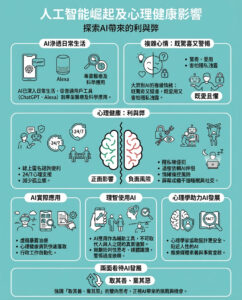
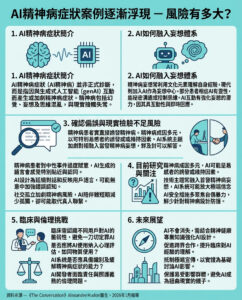
OpenAI指大型語言模型(LLM)因獎勵機制而誘發「幻覺」現象
人工智能公司OpenAI最近發表一份研究報告,指出大型語言模型(Large Language Models,LLM)訓練的聊天機械人因為獎勵機制,傾向於猜測答案,而非坦白未知,這就是所謂的「幻覺」現象。
報告中提到,這些「幻覺」源自一種二元分類錯誤,即模型在將新資訊歸類為兩個選項之一時出錯。LLM被優化成為優秀的「考試答題者」,在不確定時猜答案反而能提升整體表現,類似學生在選擇題考試中猜答案,因為留白得分為零,猜即使錯也有機會得分。
LLM的運作機制是按得分計算:正確答案得分,空白或說「不知道」則不獲得分數。這種設計導致模型傾向於提供答案,即使不確定也會嘗試猜測。
這份報告發表之際,OpenAI剛推出了新一代GPT-5,聲稱該模型比前代GPT-4o的錯誤率降低46%,更接近「無幻覺」狀態。但根據美國NewsGuard的最新研究,ChatGPT系列模型仍有40%的回答包含錯誤資訊。
AI面對「無法回答」問題時的困境
通過預先訓練和後期調整,聊天機械人學習在大量文本中預測下一個詞語。OpenAI指出,語言模型在拼寫和文法等有明確規範的任務上表現良好,但面對某些題材或資料類型,準確分類仍有困難甚至不可能。
例如,模型能夠準確分辨標籤為「貓」或「狗」的圖片,但若按寵物生日作分類,則無法準確識別。這種任務無論算法多先進,錯誤率始終存在。
報告強調,模型永遠無法達到百分百準確,因為現實世界中某些問題本質上就是「無法回答」的。
為減少幻覺,OpenAI建議用戶可指示模型在不確定時回答「我不知道」,並調整其得分機制,鼓勵模型誠實表達未知,而非盲目猜測。
—
編輯評論與深入分析
OpenAI此次研究揭示了現有大型語言模型核心運作的「隱性問題」:為了達到更高的表面準確率,模型被設計成在不確定時也要「硬答」,這種機制從根本上誘發了「幻覺」問題。對用戶來說,這種現象顯得像是聊天機械人「說謊」或「編故事」,但其實是系統獎勵機制反映出的結果。
這提醒我們,AI並非真實「懂得」答案,而是在有限範圍內計算概率和得分。若想提升AI的可靠性,除了技術層面改進外,更需要重新設計激勵機制,讓模型學會在不確定時坦白「不知道」,這不僅有助於減少錯誤資訊的傳播,也能建立用戶對AI的信任。
此外,報告提到某些問題本質上無法由AI解答,這是非常重要的認知界限。未來AI應與人類專家合作,對這類問題給予明確提示,避免誤導。
最後,OpenAI推出的GPT-5雖有提升,但根據獨立研究仍有相當比例的錯誤,顯示技術進步固然重要,監管和用戶教育同樣不可忽視。AI的發展不能只追求「表面準確度」,更需重視「透明度」和「誠實度」,這是打造負責任和可信賴AI的關鍵。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。