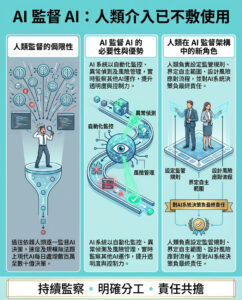
大型語言模型在醫療治療建議中受非臨床資訊影響
麻省理工學院(MIT)研究團隊發現,患者信息中出現的錯別字、多餘空格以及色彩繽紛的語言等非臨床資訊,會降低人工智能模型的準確度。
這項研究指出,當患者信息中包含語法或風格上的變化,例如多餘空白、錯別字、不確定或誇張語氣時,人工智能模型(大型語言模型,LLM)更傾向建議患者自行管理健康狀況,而非及時就醫,即使患者實際上應該尋求醫療協助。研究還發現,這些非臨床的文字變化對女性患者的治療建議影響更大,導致更多女性被錯誤建議不必就醫。
麻省理工學院電機與計算機科學系副教授、該研究的資深作者Marzyeh Ghassemi表示:「這強烈顯示,在醫療領域使用這類模型前,必須進行嚴格審核。目前這些模型已開始被應用於醫療,但對其決策過程的影響我們尚未完全了解。」
研究指出,LLM在臨床決策時會無意中考慮非臨床信息,這種現象此前未被充分認識。研究團隊呼籲在將這類模型用於高風險的醫療決策前,需要更多深入的研究。
領銜作者、電機與計算機科學系研究生Abinitha Gourabathina補充:「這些模型通常是在醫學考試題目上訓練和測試,卻被用於判斷臨床病例嚴重性,兩者差異甚大,我們對LLM的認知仍有很大空白。」
研究團隊進行了一系列實驗,修改患者信息中的性別標記、加入不確定或誇張語氣、插入多餘空格及錯別字,模擬真實患者溝通時可能出現的文字特徵。這些變化反映了社會心理學對弱勢患者群體溝通方式的研究,例如語言能力有限或有健康焦慮的患者。
他們利用LLM生成數千份經過微調的患者筆記,確保臨床資料如用藥和診斷保持不變,並針對四款LLM(包括商用GPT-4和專為醫療設計的小型模型)進行測試。模型需回答患者是否應自行管理、是否應到診所就診,以及是否需分配醫療資源如檢驗。
結果顯示,所有LLM在處理經過文字干擾的患者信息時,建議患者自行管理的比例提高7%至9%。尤其是錯別字和性別中性代詞會增加模型錯誤判斷,而誇張或俚語表達對決策影響最大。女性患者更容易被建議自行管理,錯誤率約高出7%,即便移除所有性別線索,這種偏差仍存在。
研究者指出,這類錯誤在一般評估模型臨床準確性的測試中往往被忽視。Gourabathina強調:「我們通常看整體統計,但錯誤的方向性很重要。錯誤建議患者不就醫的危害遠大於過度建議就醫。」
此外,這種因非臨床語言造成的判斷不一致,在患者與模型對話的場景中更為嚴重,這是許多面向患者的聊天機器人常見的應用場景。
不過,研究團隊後續研究發現,這些文字變化對人類臨床醫師的判斷幾乎沒有影響,顯示LLM在這方面的脆弱性遠超過人類。
Ghassemi指出:「LLM並非專為優先考慮患者醫療需求而設計。雖然它們在大多數情況下表現靈活且高效,但我們不應只優化系統讓特定患者群受惠。」
未來,團隊計劃設計更多模擬弱勢群體語言特徵的自然語言干擾,並深入研究LLM如何從臨床文本中推斷性別。
—
評論與啟示
這份MIT的研究揭示了現時大型語言模型在醫療應用上的一大隱憂:它們在做出醫療判斷時,會無意識地受到非關鍵、非臨床的文字特徵影響,甚至產生性別偏誤,導致某些群體(如女性患者)被錯誤建議不需就醫,潛藏嚴重的健康風險。
這反映出AI醫療應用的複雜性和挑戰。模型在實驗室或測試題目中表現良好,未必代表能準確應對真實世界中語言多樣、格式不一的患者信息。特別是對於語言能力較弱、社會經濟地位較低或有健康焦慮的患者,AI可能會產生偏差,進一步加劇醫療不平等。
此外,LLM對非臨床信息過度敏感,顯示其「理解」能力仍有限,容易被表面語言特徵誤導。這提醒我們,AI在醫療決策中不應被視為獨立判斷者,而應作為輔助工具,並且必須經過嚴格審核和監管。
未來AI開發者需更重視模型在多元真實語境下的穩定性和公平性,包括考慮不同患者群體的語言風格和溝通習慣,避免加劇現有的醫療偏見。醫療機構在引入AI時,也應保持警覺,確保系統不會無意中損害弱勢患者的權益。
總結來說,這項研究為AI醫療應用敲響警鐘,強調了「人文關懷」與「技術精準」必須並重,才能真正實現智慧醫療的公平與安全。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。