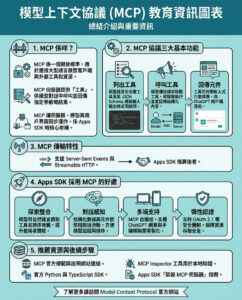
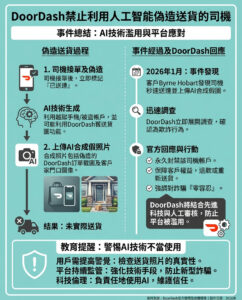
一項新的數學基準測試出爐,領先的AI模型僅能解決「不到2%」的問題……真糟糕
有時我會忘記,除了簡單的研究和快速的內容摘要外,AI模型在另一個世界裡還被用於更複雜的任務,例如金融分析和科學研究。因此,它們的數學能力顯得格外重要,這也是評估推理能力的普遍標準之一。
這就是數學基準測試存在的原因。例如,Epoch AI推出的FrontierMath基準測試,專門用於測試大型語言模型(LLMs),包含「數百個原創的、由專家精心設計的數學問題,旨在評估AI系統的高級推理能力」(根據《Ars Technica》報導)。
根據Epoch AI的說法,雖然當前的AI模型在其他數學基準測試上表現不錯(例如GSM-8k和MATH),但它們在FrontierMath的問題中僅能解決不到2%,這顯示出當前AI能力與數學界的集體實力之間存在著顯著的差距。
需要強調的是,這些問題難度很高。這些問題「通常需要專業數學家花費幾個小時或幾天來解決」,涵蓋了從數論和實分析中的計算密集型問題到代數幾何和範疇論中的抽象問題。
這個基準測試的不同之處在於,解決這些數學問題需要「長時間的精確推理鏈,每一步都必須基於前一步的結果」。傳統上,AI模型在長時間推理方面的表現並不理想,更不用說超高級的數學了。這是合乎邏輯的,因為AI模型的基本運作是基於大量數據來預測下一個最可能的單詞。儘管可以引導模型朝向不同的單詞,但這一過程本質上是概率性的。
不過,最近我們看到AI模型在其「思考」過程中逐漸朝著更有指導性的方向發展,試圖通過推理來進行思考,而不僅僅是跳到概率結論。
例如,現在有一個版本的ChatGPT-4o,它使用推理(而且你最好不要質疑它)。值得注意的是,你現在可能會因提出AI無法回答的問題而獲得獎勵,這被稱為「人類的最後考試」。
當然,這些推理的每個步驟可能本身是以概率的方式得出的——我們又能對一個非意識的算法期待什麼呢?——但它們似乎確實在進行我們這些有血有肉的人事後認為的「推理」。
不過,顯然我們距離讓這些AI模型達到我們最好、最聰明的推理能力還有一段距離。現在有了這個數學基準測試,我們可以清楚地看到它們的表現——2%可不是一個好成績,對吧?(這就讓機器人看看吧。)
關於FrontierMath問題,菲爾茲獎得主陶哲軒告訴Epoch AI:「我認為在短期內,解決這些問題的唯一方法,除了擁有真正的領域專家外,就是由一位相關領域的研究生和一些現代AI及其他代數軟件的組合來共同解決……」
雖然AI模型尚未能解決這些困難的問題,但FrontierMath基準測試將成為未來改進的良好試金石,確保這些模型不僅僅是在胡亂輸出數學無稽之談,只有專家才能驗證其真實性。
最終,我們必須記住,AI並非追求真理,儘管我們人類將其概率推理朝向真理的結果。哲學家我不得不問:如果AI沒有向真理的內在生命,它能否真正存在真理,即使它能輸出真理?對我們而言,真理是存在的,但對AI來說?我懷疑不可能,這就是為什麼像這樣的基準測試在未來進入這場新工業革命時將至關重要。
—
在這篇文章中,我們可以清晰地看到AI在高級數學推理方面的局限性。儘管AI技術在許多領域取得了進步,但其在數學推理方面的表現仍然顯示出與人類專家的巨大差距。這不僅是對AI模型能力的一次挑戰,也是一個提醒,讓我們認識到即使在數字化時代,人的智慧仍然是無可替代的。未來的發展可能會朝著更高的推理能力邁進,但這需要的不僅是數據的累積,還需要更深層次的理解與靈活性。AI能否最終實現這一點,仍然是個未知數。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。