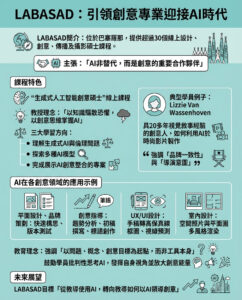
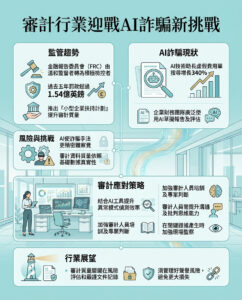
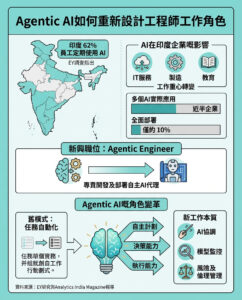
Pika 2.0:最強的AI視頻生成器
上星期,Pika Labs推出了其強大的AI視頻模型版本2,這不僅提升了運動和現實感,還帶來了一系列工具,使其成為我在報導生成AI過程中所嘗試過的最佳平台之一。
Pika 2包含了一些旨在簡化AI視頻創作過程的新功能,包括將“成分”添加到混合中,以創建更符合用戶想法的視頻,預建結構的模板,以及更多的Pikaffects功能。
Pikaffects是這家AI實驗室首次進行這類提升可控性的嘗試,並吸引了Fenty和Balenciaga等公司,以及名人和個人,分享產品、地標和物品被壓縮、爆炸和摧毀的視頻。
乍看之下,這可能讓人覺得Pika Labs在用花招和噱頭掩飾其底層模型的無能,但實際上情況完全相反。在我周末進行的測試中,即使沒有這些特性,Pika生成的視頻也能與市場上最好的模型相比,包括Kling、MiniMax、Runway甚至Sora。
測試Pika 2.0的過程
對於Pika 2.0的測試方法與我對其他模型的測試方式略有不同。通常,我會創建一系列提示——有些帶有圖像,有些則沒有——然後開始測試。然而,Pika的強大之處在於這些附加功能。
我決定首先測試其處理簡單的圖像到視頻提示的能力,然後再進行文本到視頻的測試。我給它一張在Midjourney生成的圖片,並使用相同的描述性提示來查看Pika如何生成視覺效果。
我最喜歡的AI視頻測試提示是:“一隻戴著太陽眼鏡的狗在火車上旅行。”這是因為大多數模型都能相對好地處理這個提示,但解釋方式卻各有不同。
這也要求模型創建一隻看起來逼真的狗,還要戴上太陽眼鏡——這是相當不尋常的。此外,它必須生成窗外快速運動的準確畫面,同時保持狗在車廂內靜止。
與Sora或Kling不同,Pika保持了狗的靜止,讓牠坐在座位上。它還在五秒的視頻中生成了第二個鏡頭,特寫狗的臉部,展示那副太陽眼鏡。
在使用Midjourney的圖片進行直接的圖像到視頻提示時,它的表現不如預期,但當我將圖片作為成分而非提示時,效果顯著改善。
將自己置於不同情境中
我之前寫過一篇文章,使用FreePic的一致角色特徵來微調模型,並用我自己的照片來進行測試。我能夠使用圖像到視頻模型將自己置於各種情境中,因此我決定用Pika Labs 2.0進行類似的測試。
我從一張我生成的圖片開始,畫面中我穿著西裝,站在1950年代風格的美國街道上,背景中有一個典型的UFO。我將這張圖片作為場景中的成分交給Pika 2.0。當時我不確定它會如何解讀,或者是否僅僅會保留我的肖像而忽略其他視覺元素。
這個模型的表現相當出色,創建了兩個鏡頭運動——首先聚焦於我,然後拉遠鏡頭捕捉到移動的UFO。它成功地保持了多個元素的運動,同時在短視頻中保留了整體的美學。
接著,我嘗試了一個更複雜的情況,給它一張我在白色背景前生成的AI圖像,以及一張潛在火星基地內部的生成圖像。
我將這兩張圖片作為成分,並附上提示“在火星上工作”。它生成了一段我微笑著四處走動的視頻。然後我給它一張可能被火星定居者穿著的衣物的圖片,但模型卻將其解讀為一個機器人,並給這套服裝加上了頭部。不過,整體效果依然很酷。
使用AI視頻創建標識
最後,我決定看看它如何處理我最初的AI視頻提示:“一隻穿著太空服的貓在月球上,背景是地球升起。”這個提示曾經是所有AI視頻模型都無法成功處理的,而大多數圖像模型也同樣掙扎。
首先,我使用這個提示在Ideogram中生成了一張圖片。這是我最喜歡的圖片之一,也是我計劃打印成海報的作品。然後我將其作為成分交給Pika 2.0進行AI視頻生成,沒有額外的提示。結果看起來像是一部新電影的工作室標識。
我用文本到視頻的相同提示進行了測試,結果不如預期,背景出現了第二個超地球,但相比以前的效果已經好很多。
最終想法
Pika 2.0不僅是前一代模型的一次重大升級,還將AI視頻實驗室推向市場上最佳平台之一的位置。
上周當Sora首次宣布時,我寫了一篇指南介紹最佳的Sora替代品,卻將Pika排除在外。雖然1.5版本的表現不錯,特別是在使用Pikaffects時,但與競爭對手相比仍有差距。現在我覺得需要撰寫一篇關於Pika最佳替代品的指南,因為在我看來,它的表現已經超越了Sora。
撇開競爭不談,我認為AI視頻在不到一年的時間裡取得了驚人的進步,從僅僅2秒的幾乎不動的模糊畫面,發展到如今的內容,幾乎看起來像是用真正的相機拍攝的視頻,並且對輸出幾乎擁有完全的控制權。
在這個快速發展的科技領域,Pika 2.0的推出不僅展示了技術的進步,同時也為創作者提供了更多的可能性和創意發揮的空間。隨著這類工具的日益成熟,我們或許能看到更多富有想像力的內容誕生,而這無疑將促進整個媒體行業的變革。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。