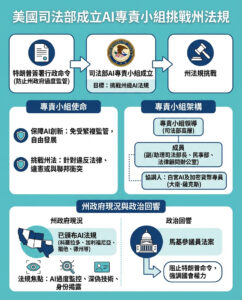
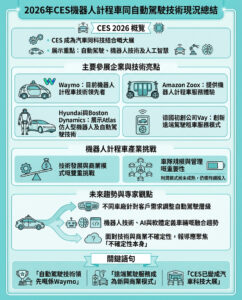
生態學家發現計算機視覺模型在檢索野生動物圖像上的盲點
生物多樣性研究人員測試了視覺系統在檢索相關自然圖像方面的表現。儘管更先進的模型在簡單查詢上表現良好,但在更具研究特定性的提示上卻面臨困難。
試想一下,若要拍攝北美約11,000種樹木的照片,你也只會得到自然圖像數據集中數百萬張照片中的一小部分。這些龐大的快照集合——從蝴蝶到座頭鯨——對生態學家來說是一個極好的研究工具,因為它們提供了生物獨特行為、罕見情況、遷徙模式和對污染及其他氣候變化形式反應的證據。
儘管自然圖像數據集非常全面,但其實用性尚未達到最佳水平。搜索這些數據庫並檢索與假設最相關的圖像耗時費力。你可能更需要一個自動化的研究助手,或者使用名為多模態視覺語言模型(VLMs)的人工智能系統。這些模型同時接受文本和圖像的訓練,使它們能更容易地指出細節,比如照片背景中特定的樹木。
但VLMs在幫助自然研究者檢索圖像方面到底有多有效呢?來自麻省理工學院計算機科學與人工智能實驗室(CSAIL)、倫敦大學學院、iNaturalist等地的研究團隊設計了一個性能測試來找出答案。每個VLM的任務是:在團隊的“INQUIRE”數據集中,定位和重新組織最相關的結果,該數據集由500萬張野生動物圖片和250個來自生態學家及其他生物多樣性專家的查詢提示組成。
尋找那隻特別的青蛙
在這些評估中,研究人員發現,更大、更先進的VLMs,經過大量數據訓練,有時能夠為研究者提供想要的結果。這些模型在簡單查詢上的表現相當不錯,例如識別珊瑚礁上的碎片,但在需要專業知識的查詢上則表現不佳,例如識別特定的生物條件或行為。舉例來說,VLMs相對容易找到海灘上的水母,但在面對更技術性的提示如“綠青蛙的缺色症”(一種限制其皮膚變黃的情況)時卻顯得棘手。
他們的發現表明,這些模型需要更多的特定領域訓練數據來處理困難的查詢。麻省理工學院的博士生Edward Vendrow,他是這項工作的共同領導者之一,認為通過熟悉更多信息豐富的數據,VLMs未來可能成為出色的研究助手。他表示:“我們希望構建檢索系統,能夠找到科學家在監測生物多樣性和分析氣候變化時所需的準確結果。”Vendrow補充道:“多模態模型尚未完全理解更複雜的科學語言,但我們相信INQUIRE將成為跟蹤它們在理解科學術語和最終幫助研究者自動找到所需圖像方面的重要基準。”
該團隊的實驗表明,由於其廣泛的訓練數據,更大的模型在簡單和複雜搜索中都更有效。他們首先使用INQUIRE數據集來測試VLMs是否能將500萬張圖像縮小到最相關的前100個結果(即“排名”)。在像“有人工結構和碎片的珊瑚礁”這樣的簡單搜索查詢中,相對較大的模型如“SigLIP”找到匹配的圖像,而較小的CLIP模型則表現不佳。根據Vendrow的說法,較大的VLMs在排名較難的查詢時“才剛開始變得有用”。
Vendrow和他的同事們還評估了多模態模型重新排名那100個結果的能力,重新組織哪些圖像對搜索最相關。在這些測試中,即使是經過更精選數據訓練的巨型LLMs,如GPT-4o,也表現不佳:其精確度分數僅為59.6%,這是所有模型中最高的分數。
查詢INQUIRE
INQUIRE數據集包括基於與生態學家、生物學家、海洋學家和其他專家的討論而制定的搜索查詢,這些查詢涵蓋了他們會尋找的圖像類型,包括動物獨特的生理條件和行為。一組標註者隨後花了180小時使用這些提示搜索iNaturalist數據集,仔細篩選了約200,000個結果,標註了33,000個符合提示的匹配項。
例如,標註者使用查詢如“使用塑料廢物作為外殼的寄居蟹”和“帶著綠色‘26’標籤的加州禿頭鷹”來識別更大圖像數據集中描繪這些特定稀有事件的子集。
然後,研究人員使用相同的搜索查詢來查看VLMs能多好地檢索iNaturalist圖像。標註者的標籤揭示了模型在理解科學家關鍵詞時的困難,因為它們的結果包括以前被標記為與搜索無關的圖像。例如,VLMs對“帶有火災傷痕的紅杉樹”的結果有時會包含沒有任何標記的樹的圖像。
麻省理工學院CSAIL的助理教授Sara Beery表示:“這是對數據的仔細策劃,專注於捕捉生態學和環境科學研究領域的真實科學查詢示例。”她補充道:“這對擴展我們對VLMs在這些可能影響深遠的科學環境中當前能力的理解至關重要。它還指出了當前研究中的空白,我們現在可以著手解決,特別是在複雜的組合查詢、技術術語以及劃分我們合作者感興趣類別的微妙差異方面。”
Vendrow表示:“我們的發現表明,一些視覺模型已經足夠精確,可以幫助野生動物科學家檢索某些圖像,但對於即使是最大的、表現最好的模型來說,許多任務仍然過於困難。”他強調:“雖然INQUIRE專注於生態學和生物多樣性監測,但其查詢的多樣性意味著,在INQUIRE上表現良好的VLMs可能在其他觀察密集型領域分析大型圖像集合時也會表現優秀。”
好奇的心想要看到
為了進一步推進他們的項目,研究人員正在與iNaturalist合作開發一個查詢系統,以更好地幫助科學家和其他好奇的人找到他們真正想要查看的圖像。他們的工作演示允許用戶按物種篩選搜索,從而更快速地發現相關結果,比如貓的多樣眼睛顏色。Vendrow和共同首席作者Omiros Pantazis(最近在倫敦大學獲得博士學位)還計劃通過增強當前模型來改善重新排名系統,以提供更好的結果。
匹茲堡大學的副教授Justin Kitzes強調了INQUIRE揭示二次數據的能力。他表示:“生物多樣性數據集正迅速變得過於龐大,任何個別科學家都無法審查。”Kitzes補充道:“這篇論文引起了人們對一個困難且未解決問題的關注,即如何有效地在這樣的數據中搜索,提出的問題不僅僅是‘這裡有誰’,而是關於個體特徵、行為和物種互動的問題。能夠高效且準確地揭示這些更複雜的生物多樣性圖像數據現象,對於基礎科學和生態學及保護的實際影響至關重要。”
Vendrow、Pantazis和Beery與iNaturalist的軟件工程師Alexander Shepard、倫敦大學的教授Gabriel Brostow和Kate Jones、愛丁堡大學的副教授及共同首席作者Oisin Mac Aodha,以及馬薩諸塞州大學阿默斯特分校的助理教授Grant Van Horn共同撰寫了這篇論文。他們的工作部分得到了愛丁堡大學生成AI實驗室、美國國家科學基金會/加拿大自然科學與工程研究理事會全球AI與生物多樣性變化中心、英國皇家學會研究獎助金以及由英國世界自然基金會資助的生物群健康項目的支持。
這項研究顯示了人工智能在生態學領域的潛力,以及未來在處理複雜查詢和數據檢索方面可能帶來的改變。隨著技術的不斷進步,這些模型將能夠更好地理解科學語言,從而在生物多樣性監測和環境保護中發揮更大的作用。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。