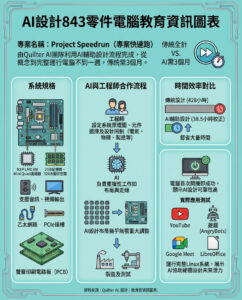
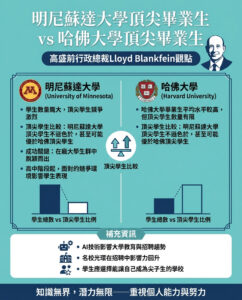
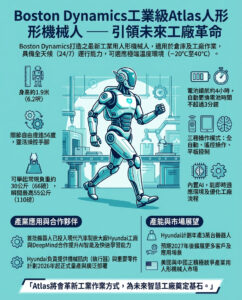
大型語言模型能否幫助設計我們的下一代藥物和材料?
一種新方法讓用戶可以用簡單的語言請求具備特定特性的分子,並獲得詳細的合成說明。
發表日期:2025年4月9日
發現具備創建新藥物和材料所需屬性的分子過程繁瑣且成本高昂,通常需要消耗大量計算資源和數月的人力來篩選潛在候選分子。
大型語言模型(LLMs)如ChatGPT有潛力簡化這一過程,但讓LLM理解和推理分子中原子和鍵結的方式,與理解形成句子的單詞一樣,卻一直是科學上的一個難題。
麻省理工學院(MIT)及MIT-IBM沃森人工智能實驗室的研究人員創造了一種有前景的方法,將LLM與被稱為圖形基模型的其他機器學習模型相結合,這些模型專門設計用於生成和預測分子結構。
他們的方法利用基礎LLM來解釋自然語言查詢,指定所需的分子屬性。該系統能自動在基礎LLM和圖形基人工智能模塊之間切換,以設計分子、解釋理由並生成逐步的合成計劃。它將文本、圖形和合成步驟生成交織在一起,將單詞、圖形和反應結合成一個共同的詞彙,供LLM使用。
與現有的基於LLM的方法相比,這種多模態技術生成的分子更符合用戶規範,且更有可能擁有有效的合成計劃,成功率從5%提高至35%。
此外,它的表現超過了十倍於其大小的LLM,這些模型僅用基於文本的表示來設計分子和合成路徑,這表明多模態是新系統成功的關鍵。
“希望這能成為一個端到端的解決方案,從頭到尾自動化設計和製造分子的整個過程。如果LLM能在幾秒鐘內給出答案,將對製藥公司節省大量時間,”MIT研究生、該技術論文的共同作者Michael Sun如是說。
Sun的共同作者包括首席作者、聖母大學的研究生Gang Liu;MIT電機工程與計算機科學教授、計算設計與製造小組的負責人Wojciech Matusik;聖母大學副教授Meng Jiang;以及MIT-IBM沃森AI實驗室的資深研究科學家及經理Jie Chen。該研究將在國際學習表徵會議上展示。
雙贏的最佳方案
大型語言模型並不是為了理解化學的細微差別而建立的,這也是它們在逆分子設計中掙扎的原因之一,該過程旨在識別具有特定功能或屬性的分子結構。
LLMs將文本轉換為稱為標記的表示,並用來逐步預測句子中的下一個單詞。但分子是“圖形結構”,由原子和鍵結組成,沒有特定的順序,使其難以作為順序文本來編碼。
另一方面,強大的圖形基人工智能模型將原子和分子鍵結表示為圖中的相互連接的節點和邊緣。雖然這些模型在逆分子設計中非常受歡迎,但它們需要複雜的輸入,無法理解自然語言,且產生的結果可能難以解釋。
MIT的研究人員將LLM與圖形基人工智能模型結合成一個統一的框架,實現了兩者的最佳結合。
Llamole,即大型語言模型分子發現工具,使用基礎LLM作為門控器來理解用戶的查詢——即用簡單的語言請求具備特定屬性的分子。
例如,假設用戶尋求一種能穿透血腦屏障並抑制HIV的分子,其分子量為209,並具備某些鍵結特徵。
當LLM根據查詢預測文本時,它在圖模塊之間切換。
一個模塊使用圖擴散模型生成根據輸入要求的分子結構。第二個模塊使用圖神經網絡將生成的分子結構編碼回標記,以供LLM使用。最後一個圖模塊是圖反應預測器,接受中間分子結構作為輸入,預測反應步驟,尋找從基本構建塊製造分子的確切步驟。
研究人員創造了一種類型的觸發標記,告訴LLM何時激活每個模塊。當LLM預測“設計”觸發標記時,它切換到草擬分子結構的模塊;當它預測“逆合成”觸發標記時,它切換到預測下一個反應步驟的逆合成規劃模塊。
“這樣的美妙之處在於,LLM在激活特定模塊之前生成的所有內容都會被輸入到該模塊中。模塊學會以與之前一致的方式運作,”Sun說。
同樣,每個模塊的輸出會被編碼並反饋到LLM的生成過程中,使其理解每個模塊的作用,並根據這些數據繼續預測標記。
更好、更簡單的分子結構
最終,Llamole輸出分子結構的圖像、分子的文本描述以及提供詳細合成計劃的逐步說明,涵蓋如何製造它,甚至包括個別化學反應。
在涉及設計符合用戶規範的分子的實驗中,Llamole的表現超過了10個標準LLM、4個微調的LLM,以及一種最先進的領域特定方法。同時,它將逆合成規劃的成功率從5%提升至35%,生成的分子品質更高,這意味著它們具有更簡單的結構和更低成本的構建塊。
“單靠LLM很難弄清楚如何合成分子,因為這需要大量的多步規劃。我們的方法可以生成更好的分子結構,這些結構也更易於合成,”Liu表示。
為了訓練和評估Llamole,研究人員從零開始建立了兩個數據集,因為現有的分子結構數據集未包含足夠的細節。他們用AI生成的自然語言描述和自定義描述模板擴充了數十萬個專利分子。
他們建立的數據集用於微調LLM,包括與10個分子屬性相關的模板,因此Llamole的一個限制是它僅訓練設計考慮這10個數值屬性的分子。
在未來的工作中,研究人員希望擴展Llamole,使其能夠包含任何分子屬性。此外,他們計劃改進圖模塊,以提高Llamole的逆合成成功率。
從長遠來看,他們希望利用這種方法超越分子,創造能夠處理其他類型圖形數據的多模態LLM,例如電網中互連的傳感器或金融市場中的交易。
“Llamole展示了使用大型語言模型作為與複雜數據交互的界面的可行性,我們預計它們將成為與其他人工智能算法互動解決任何圖形問題的基礎,”Chen說。
這項研究部分由MIT-IBM沃森人工智能實驗室、國家科學基金會及海軍研究辦公室資助。
在這篇文章中,我們看到大型語言模型與圖形基人工智能的結合,為分子設計開啟了全新的可能性。這不僅僅是科學上的突破,更是對製藥行業的潛在影響,能夠顯著提高設計新藥的效率和成功率。這項技術的發展可能會重新定義藥物開發的過程,將來我們或許能見證更快速、更低成本的藥物研發,這對於全球健康事業而言,無疑是一個好消息。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。