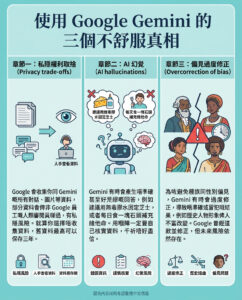
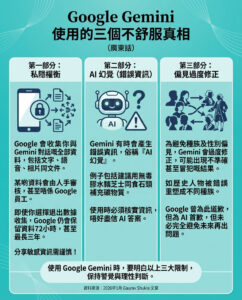
人工智能模型能否像人類一樣推理?
我們正期待OpenAI的o3模型於本月推出。它在一些非常困難的基準測試上表現出色,例如SWE-bench Verified、Frontier Math和ARC AGI基準(之前在這個博客中有討論過)。
然而,與此同時,某些前沿人工智能模型的行為卻令人擔憂。
它們在各種數學考試中的表現優異,但在進行簡單的算術運算時卻會犯錯,例如錯誤地將幾位數的數字相乘。o1預覽模型在艱難的Putnam數學考試中的表現非常好,但在問題陳述中進行簡單的常數和變量重命名後,表現卻驟然下降。
同樣地,當o1應用於以標準化語言表達的規劃基準時,表現良好,但當應用於不同領域的數學等價規劃問題時,準確性卻大幅下降。此外,某個AI模型應用於簡單的ROT13密碼時,根據密碼鍵的值可能會有截然不同的表現,這表明這些模型並不真正理解算法。
究竟發生了什麼事?
多年來,一些人對各種深度學習算法聲稱其達到了“人類水平的表現”。一旦有一方開始這樣聲稱,其他人就難以抗拒跟進。
混淆之處在於,從某個角度來看,“人類水平”的聲明是正確的,但“人類水平”的定義卻是複雜的。
在這裡,“人類水平”被理解為在某個基準集上取得高分,表面上超過了同一基準上某些人類的表現。然而,單一的AI模型在行為上可能會有很大的能力差異——在某些方面相對於人類是“聰明”的,而在其他方面則顯得“愚笨”。
對於人類來說,考試是一種衡量各種技能和能力的代理工具。即使對於人類來說,這也不總是準確的代理。某個人可能在學術考試中表現優異,而在工作中表現卻很糟糕,反之亦然。
而且,AI模型的能力比例仍然非常不同,這些差異我們尚未完全理解。因此,在軟件工程基準上超過人類的表現並不意味著該AI具備成為一名合格軟件工程師所需的所有編碼技能、決策能力、軟件架構設計等能力。
最近的文章顯示,對於當前設計的AI基準的限制的認知正在增長,這並不令人意外。
前進的方向
或許我們應該考慮在聲稱AI模型具有人類水平推理能力之前,制定以下要求:
1. 它應該能夠以任何細節水平“解釋其工作”,讓另一個人類(就像人類一樣)能理解。
2. 它應該能夠在不“幻想”或“編造”答案的情況下給出答案(是的,人類也可以幻想,但大多數職業不會對在工作中幻想的員工感到滿意)。
3. 它應該能夠可靠且一致地(100%時間)做我們通常期望人類或計算機準確完成的事情(例如,準確加減兩個數字,以填寫稅表或進行工程計算以建造飛機)。
4. 它在評估其給出答案的確定性時應該坦誠且誠實(不應該有氣燄)。
5. 它應該能夠像人類一樣輕鬆解決給定問題的微小擾動。
6. 有人曾經說過,它應該能夠在沒有特定訓練的情況下,做出一個5歲小孩能夠在沒有特定訓練的情況下做到的事。
7. Emmett Shear提出的觀點也很有意思:“AGI(人工通用智能)是能夠在沒有特別訓練的情況下,對敵意選擇的新基準進行概括的能力。”
AI模型是非常出色和驚人的工具——但最好是在充分了解其局限性的情況下使用。
你有遇到過AI模型性能問題嗎?如果有,請在評論中分享。
—
這篇文章深刻地揭示了當前人工智能技術的局限性,尤其是在推理和理解方面的不足。儘管這些模型在許多基準測試中表現優異,但它們在實際應用中卻可能出現錯誤,這讓人對其“人類水平”的表現提出質疑。未來,若希望人工智能能夠在更廣泛的範疇內實現可靠的推理能力,我們必須重新審視和設計其評估標準,以確保這些技術不僅僅是在數字上超越人類,而是真正理解和應用知識。這不僅是技術發展的需求,也是社會對人工智能未來的期待。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。