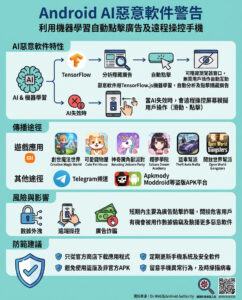
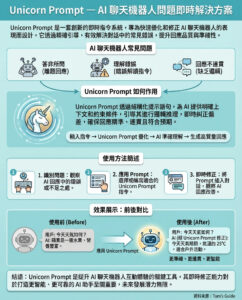
識別不斷演變的AI模型安全威脅
隨著人工智能(AI)迅速發展,成為科技和商業創新的基石,它已經深入各個行業,徹底改變了我們與世界的互動方式。AI工具現在能夠簡化決策過程、優化運營並提供個性化的體驗。
然而,這種快速擴展帶來了一個複雜且日益增長的威脅格局——這種威脅結合了傳統的網絡安全風險和特定於AI的獨特脆弱性。這些新興風險可能包括數據操縱、對抗性攻擊和機器學習模型的利用,每一種都可能對隱私、安全和信任造成嚴重影響。
隨著AI不斷深入到醫療、金融和國家安全等關鍵基礎設施,組織必須採取主動的、分層的防禦策略。通過保持警惕並不斷識別和解決這些脆弱性,企業不僅能夠保護他們的AI系統,還能維護其更廣泛數字環境的完整性和韌性。
面對AI模型和用戶的新威脅
隨著AI的使用擴大,所面臨的威脅也變得更加複雜。一些最迫切的威脅涉及數字內容的信任、在模型中故意或無意中嵌入的後門、攻擊者利用的傳統安全漏洞以及巧妙繞過現有保護措施的新技術。此外,深度偽造和合成媒體的興起進一步複雜了這一格局,對驗證AI生成內容的真實性和完整性造成了挑戰。
數字內容的信任:隨著AI生成的內容逐漸無法與真實圖像區分開來,公司正在建立保護措施以防止錯誤信息的傳播。如果在這些保護措施中發現漏洞會怎樣?例如,水印操縱使對手能夠篡改AI模型生成圖像的真實性。這一技術可以添加或移除標記內容為AI生成的隱形水印,從而破壞內容的信任並助長錯誤信息,這可能導致嚴重的社會後果。
模型中的後門:由於AI模型的開源性質,例如通過Hugging Face等網站,包含後門的經常重用模型可能導致嚴重的供應鏈影響。我們的Synaptic Adversarial Intelligence (SAI)團隊開發了一種名為“ShadowLogic”的尖端方法,允許對手在神經網絡模型中植入無代碼的隱藏後門。通過操縱模型的計算圖,攻擊者可以在不被檢測的情況下破壞其完整性,即使在模型經過微調後後門仍然存在。
高影響技術中AI的整合:像谷歌的Gemini這樣的AI模型已被證明容易受到間接提示注入攻擊。在某些情況下,攻擊者可以操縱這些模型產生誤導性或有害的回應,甚至使其調用API,這突顯了持續需要警惕防禦機制。
在對手之前識別脆弱性
為了應對這些威脅,研究人員必須保持領先一步,預測壞人可能採用的技術,通常是在這些對手甚至尚未認識到潛在影響的機會之前。通過將主動研究與旨在揭露AI框架中隱藏脆弱性的創新自動化工具結合,研究人員可以發現並披露新的常見脆弱性和暴露(CVE)。這種負責任的脆弱性披露方法不僅增強了個別AI系統,還通過提高認識和建立基準保護來強化整個行業,以應對已知和新興的威脅。
識別脆弱性僅僅是第一步。將學術研究轉化為能夠在現實生產環境中有效運作的可實施解決方案同樣至關重要。這一從理論到應用的橋梁在HiddenLayer的SAI團隊適應學術見解以應對實際安全風險的項目中得到了體現,強調了使研究具備可操作性的重要性,並確保防禦措施強大、可擴展且能夠適應不斷演變的威脅。通過將基礎研究轉化為運行防禦,行業不僅保護AI系統,還建立韌性和信心,為用戶和組織抵禦快速變化的威脅格局。這種主動的、分層的方式對於實現能夠抵擋當前和未來對抗性技術的安全、可靠的AI應用至關重要。
向更安全的AI系統創新
AI系統的安全性不再可以被忽視;它必須融入AI創新的基礎。隨著AI技術的進步,攻擊者的方法和動機也在不斷演變。威脅行為者越來越專注於利用特定於AI模型的弱點,從操縱模型輸出的對抗性攻擊到降低模型準確性的數據中毒技術。為了應對這些風險,行業正在向將安全性直接嵌入AI的開發和部署階段轉變,使其成為AI生命周期的重要組成部分。這種主動的方法正在促進更安全的AI環境,並在問題出現之前減輕風險,降低意外中斷的可能性。
研究人員和行業領導者都在加快努力,以識別和抵制不斷演變的脆弱性。隨著AI研究從理論探索向實際應用遷移,新攻擊方法迅速從學術討論轉向現實實施。採用“安全設計”原則對於建立以安全為首的思維模式至關重要,這雖然不是萬無一失,但卻提升了AI系統及其依賴的行業的基準保護。隨著AI在醫療、金融等領域的革命性發展,嵌入強大的安全措施對於支持可持續增長和培養對這些變革性技術的信任至關重要。將安全視為負擔而非催化劑的態度將確保AI系統具有韌性、可靠性,並能夠抵禦動態且複雜的威脅,為未來的創新和安全進展鋪平道路。
這篇文章展示了當前AI模型面臨的安全挑戰,並強調了企業在應對這些威脅時所需的主動防禦策略。隨著技術的快速發展,對於如何在保持創新同時確保安全,這是我們不能忽視的重要話題。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。