人工智能評分論文出現種族偏見 亦難分辨優劣寫作
Smith:研究發現ChatGPT複製人類偏見,無法識別傑出作品,反而加劇原本想解決的不平等問題
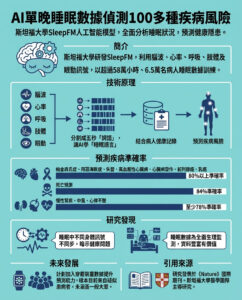
每日人工智能(AI)技術越來越深入美國校園,協助教師為學生度身訂造學習方案、輔導學生及設計課堂教案。不過,AI在批改學生寫作方面表現如何,仍有爭議。由The Learning Agency最新研究顯示,雖然ChatGPT能模仿人類對論文的評分,但卻難以分辨優秀與差勁的寫作,這對學生影響甚大。
研究團隊利用「自動學生評估獎(Automated Student Assessment Prize, ASAP)2.0」基準數據,評估ChatGPT的論文評分能力。該數據庫包含約24,000篇由美國中學及高中生寫的論證性文章,每篇文章均有人類評分,並附帶作者的種族、英語學習者身份、性別及經濟背景等人口統計資料。這令研究人員能夠檢視AI不僅與人類評分的差異,更能分析其在不同學生群體間的表現。
研究結果顯示,ChatGPT對不同人口群體給予的平均分數有所不同,但大部分差異非常細微,影響不大。惟有一個例外是黑人學生的分數明顯低於亞裔學生,這個差距足以引起關注。
然而,這種差異在人類評分中同樣存在。換言之,ChatGPT並沒有引入新的偏見,而是複製了人類評分數據中原有的偏見。雖然這似乎代表AI模型反映了現有標準,但同時也揭示了一個嚴重風險:當訓練數據本身反映了人口群體間的不平等,這些不平等便會被模型「內化」。結果,歷來被忽視的學生依然被忽視。
這問題不容小覷。如果AI模型加強了現有評分差異,學生可能因歷史上被偏低評價,而非真實寫作品質差劣而被扣分。長遠來看,這會打擊學生的學業自信心,影響他們選修高階課程甚至大學錄取,令教育不平等問題雪上加霜,非但未能縮窄差距。
研究還發現,ChatGPT難以分辨優秀和差劣的寫作。與人類評分者多給予A及F分數不同,ChatGPT大多給出中等的C分,導致優秀寫作者未必獲得應有讚賞,而較弱寫作亦可能未被察覺。對於來自邊緣化背景、往往更需努力爭取注意的學生來說,這可能是重大的損失。
當然,人類評分亦有缺陷,教師可能有無意識的偏見或標準不一。但若AI既複製這些偏見,又無法識別傑出作品,問題不會得到解決,反而令眾多教育倡導者及教師致力消除的不平等被加劇。
因此,學校及教育工作者需審慎考慮何時及如何使用AI評分。AI或可用於提供文法或段落結構的反饋,但最終評分應由教師負責。同時,教育科技開發者有責任嚴格檢視其工具,不僅要衡量準確度,更要問清楚:準確度是對誰而言?在甚麼情況下?誰受惠?誰被忽視?
帶有人口統計資料及人類分數的基準數據集,如ASAP 2.0,對評估AI系統公平性至關重要。但這還不夠。開發者需要更多高質素數據集,研究者需要經費支持創建這些數據,業界亦需明確指引,從一開始就將公平性置於核心,而非事後補救。
AI正逐步改變學生的教學與評價方式。若要未來公平,開發者必須打造能考慮偏見的AI工具,教育者亦需在清晰界限下使用這些工具。此類工具應助力每位學生發光發熱,而非將他們的潛力壓縮至平均水平。教育AI的承諾不僅是提升效率,更是促進公平,這一點無人可以忽視。
—
評論與啟示
這項研究揭示了AI在教育評分應用上的核心矛盾:AI的判斷能力在一定程度上依賴於人類的歷史數據,而這些數據本身就帶有社會偏見和不平等。簡單來說,AI不會自動「超越」人類的偏見,反而可能將其固化,甚至放大。這對香港及全球教育界都是一個警號,提醒我們不能盲目追求科技便利,而忽略了公平正義的底線。
此外,ChatGPT難以區分優秀與低劣作品,反映出AI在「質量判斷」上的局限。這意味著依賴AI評分可能會抹煞學生的個別優勢,特別是那些需要更多關注和肯定的弱勢群體學生。教育不應只是一個數字遊戲,而是要培養多元才能和獨特聲音,AI工具的設計和應用必須尊重這一點。
香港教育界在引入AI輔助教學和評分時,應該借鑑這些發現,設計出適合本地情況的監管和使用框架。例如,AI評分應該作為輔助工具而非決定性標準,並且定期檢視其在不同學生群體中的表現差異。政府、學校與科技開發者應攜手合作,確保技術發展不僅提升效率,更促進教育公平,避免重蹈覆轍。
總括而言,AI技術在教育的潛力巨大,但其發展不能脫離人文關懷與公平準則。未來教育AI的成功,關鍵在於如何平衡科技進步與社會正義,讓每位學生都能在公平的環境下發揮潛能,這是我們不能忽視的挑戰。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。