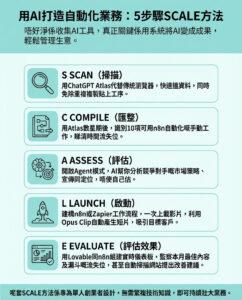
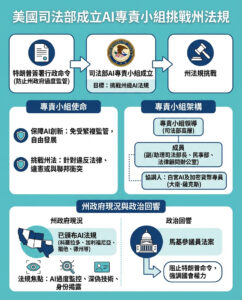
強化學習的崛起:人工智能的靜悄悄革命
隨著人工智能的持續發展,一場靜悄悄的革命正在重塑這個領域,這並不是那些吸引眼球的新聞所報導的。儘管聊天機器人和圖像生成器引人注目,但強化學習——這一在過去二十年中在學術界逐漸成熟的方法,正驅動著下一代人工智能的突破。想像一下,一個孩子學習騎自行車:沒有手冊,只有反覆的嘗試、錯誤和保持平衡的快樂。這就是強化學習,它是一種算法,通過探索、調整和從反饋中學習,就像在尋找復活蛋的遊戲中得到“熱”或“冷”的提示。這種方法不僅改變了機器學習的方式,還重新定義了智能的含義。
傳統機器學習的舊守衛
要理解強化學習的崛起,首先要看看傳統機器學習的兩大支柱:
1. **監督學習**:在這裡,算法會接收標記的示例,例如數以千計的貓和狗的照片,然後根據這些數據學習進行預測或生成。這一方法在從X光分析到文本生成等各個領域都得到了應用,像我們現在熟悉的ChatGPT,它利用大量文本數據預測句子中的下一個單詞。然而,這一方法成本高昂,需要大量標記數據和計算資源。
2. **非監督學習**:這涉及在沒有指導的情況下尋找模式。它可能會根據旋律將歌曲進行聚類,或根據主題對公共諮詢的回應進行分組,而不帶任何偏見或外部觀點。雖然它更高效且需要更少的數據,但它在揭示數據中的隱藏模式時缺乏上下文判斷的能力。這兩種方法在各自的領域中表現出色,且常常結合使用,但在數據稀缺或目標模糊的情況下卻會遇到困難。這正是強化學習可以發揮作用的地方。
什麼是強化學習?
強化學習通過實踐來學習,僅根據來自環境的獎勵或懲罰進行指導。它不僅僅是遵循腳本,而是探索如何解決問題。2015年,《自然》雜誌發表了一篇論文,展示了谷歌研究人員如何讓一個經過強化學習訓練的“代理”僅通過螢幕像素和計分板來掌握Atari遊戲。通過無數次的嘗試,它學會了在《太空入侵者》、《Q*bert》、《瘋狂攀登者》等遊戲中獲勝,並用驚人的操作令玩家感到震驚。一年後,同樣在《自然》上發表的研究中,谷歌運用類似技術擊敗了世界圍棋冠軍,這一里程碑曾被認為需要數十年才能實現。強化學習在缺乏明確指導的情況下蓬勃發展。它不需要大量的標記數據,而只需一個目標和衡量成功的方法。
強化學習的變革性影響
強化學習的優勢在於其效率和創造力:
– **精簡而有效**:與需要大量計算資源的監督學習不同,強化學習可以以更少的資源運行。它從經驗中學習,而不是依賴於大量的範例。
– **超越框架思維**:強化學習代理可以自由探索,經常會發現人類忽略的解決方案。在Atari遊戲中,AI的非常規策略暗示了其在物流或藥物發現等領域的潛力。
– **靈活性**:在一個上下文中學到的技能可以適應到另一個上下文中。一個導航迷宮的機器人或玩遊戲的AI可以在最小的再訓練下快速轉變。
更深的意義
強化學習的故事不僅僅是技術上的,還是哲學上的。它的嘗試與錯誤模擬了人類的學習,提出了重大問題。如果機器能夠複製這一過程,那麼什麼才是智能的定義?如果它們能夠識別我們無法察覺的模式,那麼我們又能從中學到什麼?
AI界的權威人物安德魯·吳在與托比·沃爾什的對話中提到,反思他2002年的博士論文,吳表示:“我的博士論文是關於強化學習的……我和我的團隊在研究一個機器人。”他早期的預測如今得到了回報。
強化學習的潛力巨大:想像一下更高效的能源網絡、量身定制的教育或更智能的機器人。然而,它的自主性也要求我們謹慎思考用於訓練模型的激勵措施。比如,一個旨在緩解交通的代理可能會將汽車重新導向安靜的街道,從而以擾亂為代價來交換效率。透明性和倫理將是關鍵。不過,若能妥善運用,強化學習可能開創一個機器不僅僅是模仿我們,而是照亮新道路的時代。
強化學習不是人工智能故事中的一個註腳,而是一個轉折點。尋找更智能、更精簡的智能系統的競賽已經展開,而強化學習正引領著這一潮流。
—
在這篇文章中,強化學習的潛力和未來方向被清楚地描繪出來。隨著技術的進步,強化學習將可能在許多行業中發揮重要作用,尤其是在需要靈活性和創新的領域。值得注意的是,隨著這種技術的普及,我們也必須面對倫理和透明度的挑戰,這將成為未來發展的關鍵因素。如何平衡技術的進步與社會責任,將是我們需要持續探討的問題。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。