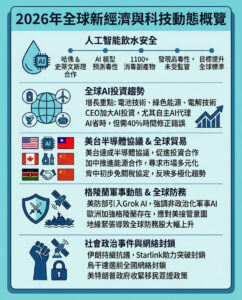
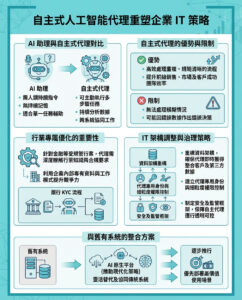
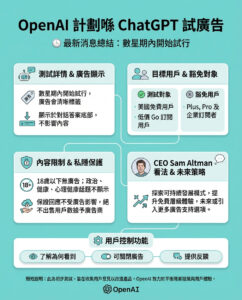
AI 公司或將面臨重大法律風險
一項最新的學術研究揭露了大型語言模型(LLM)製造商一個非常、非常、非常嚴重的謊言。
這項研究指向了人工智能行業核心的問題,尤其是關於版權和資料來源的透明度。多年來,許多AI公司聲稱他們的模型是合法訓練的,且不涉及侵犯版權,但這份研究指出,這些宣稱背後隱藏著巨大的法律風險。
學術研究揭示AI訓練資料的版權問題
研究發現,許多AI模型在訓練過程中使用了未經授權的版權保護內容,包括大量書籍、文章和其他創作作品。這種做法可能違反多國的知識產權法。更嚴重的是,這些大型模型的製造商往往未公開詳細說明其訓練數據的來源和授權情況,形成一個法律上的灰色地帶。
多宗版權訴訟正在醞釀中
目前,已有多位作者和出版商對部分AI公司提出訴訟,指控他們未經授權使用其作品進行訓練。部分案件甚至涉及潛在的巨額賠償,金額可能達數十億甚至上千億美元。這些訴訟不僅針對OpenAI,也波及其他大型AI開發商如Anthropic和Meta。
內部文件和通訊成為證據
在一些案件中,原告已獲取了被告公司內部的Slack訊息和其他通訊記錄,揭示了公司對於訓練資料版權問題的認知和態度。這些證據顯示,部分公司明知其做法可能違法,卻仍繼續使用受保護的內容。
AI產業的未來與法律挑戰
這場法律風暴可能會對AI產業造成深遠影響。企業必須更加謹慎地管理訓練資料來源,並提高透明度以避免法律風險。未來,監管機構和法院的判決將成為產業發展的重要指標。
—
評論與見解:
這篇報導揭示了AI產業背後一個極具爭議且關鍵的問題——版權與數據合法性。現時,AI模型的訓練依賴海量資料,但這些資料多數來自於未經授權的版權作品,令AI公司置身於法律風險的邊緣。這不僅是技術問題,更是道德與法律的雙重考驗。
從香港及國際視角看,這提醒我們在推動AI發展時,不能忽視版權法規的重要性。若AI產業不正視這些問題,可能會面臨巨額賠償和信譽危機,甚至影響創新生態系統的健康發展。
同時,這也提示立法者需加快更新相關法律,明確規範AI訓練資料的合法使用範圍,保障創作者權益與科技進步的平衡。對用戶而言,了解這些法律風險,有助於提高對AI產品的審視與選擇標準。
總括而言,AI不應只是技術突破的代名詞,更應是一場法律與倫理的深刻變革。企業、政府與社會三方必須共同努力,為AI的可持續發展建立堅實的法律基礎。
以上文章由GPT 所翻譯及撰寫。而圖片則由GEMINI根據內容自動生成。