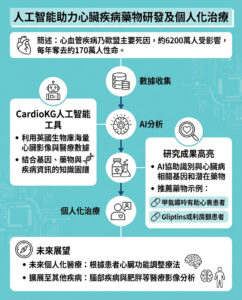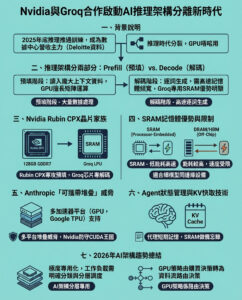
Nvidia斥資200億美元授權Groq 打響AI推理架構四方大戰序幕
Nvidia與Groq簽訂的200億美元戰略授權協議,標誌著未來AI技術堆棧競爭的四大戰線正式拉開。2026年,這場角力將明顯影響企業AI應用的構建方向。
我們每日與技術決策者交流,這些人正是推動AI應用和數據管線發展的主力軍。這次交易清楚地傳遞出一個信號:以往「一刀切」的GPU方案作為AI推理標準的時代,正在走向終結。
我們正邁入一個「分解式推理架構」的時代,晶片將被拆分成兩類,以滿足既需龐大上下文又要瞬時推理的需求。
推理為何將GPU架構一分為二?
——————————————-
要理解為什麼Nvidia CEO黃仁勳會拿出其據稱600億美元現金儲備的三分之一來買授權,就必須看到對其擁有約92%全球GPU市場份額的公司構成的多重生存威脅。
到2025年底,行業出現分水嶺:根據Deloitte數據,AI推理階段首次在數據中心總收入上超越了訓練階段。這場「推理反轉」改變了遊戲規則。雖然準確度仍是基本要求,但現在的較量重點轉向延遲時間和自主智能體的「狀態維持」能力。
這場戰役有四大前線,且都指向同一結論:推理工作負載正以超越GPU通用能力的速度快速分化。
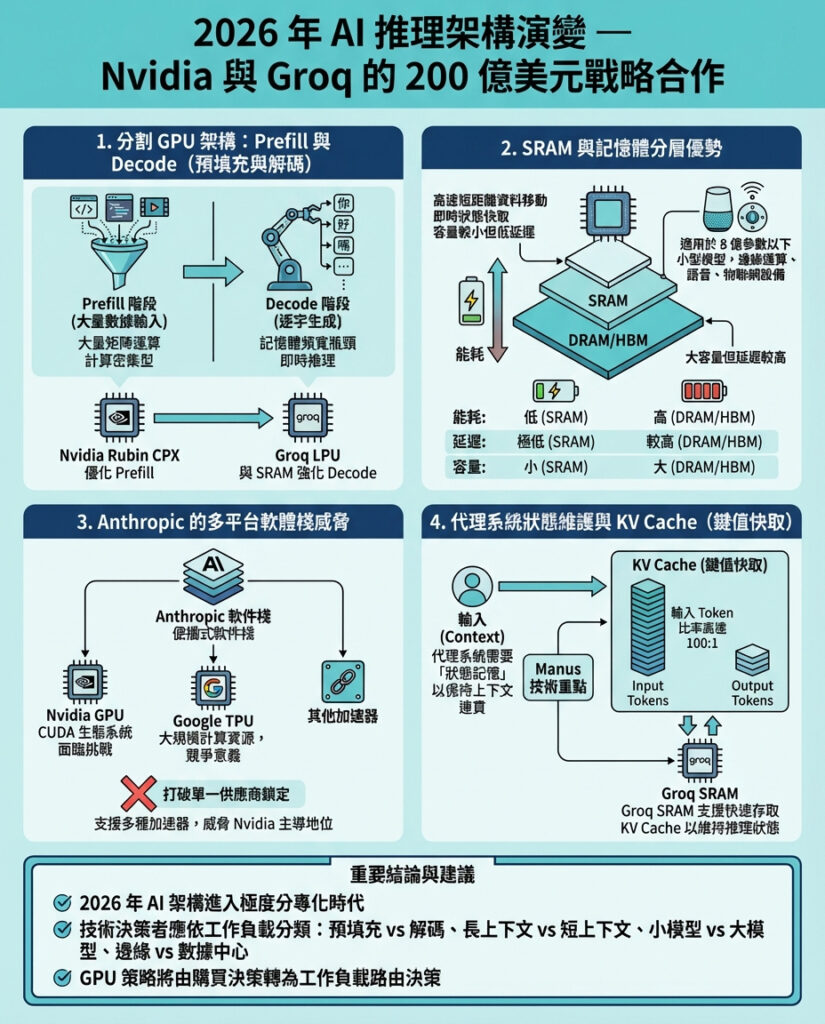
1. GPU被拆分:Prefill與Decode兩階段
Groq投資人Gavin Baker(雖有偏見,但對架構十分了解)總結道:「推理正分化為prefill(預填充)和decode(解碼)兩階段。」
– Prefill階段:類似用戶下達的提示(prompt)階段,模型需吞下龐大數據——無論是十萬行代碼還是一小時視頻——並計算出上下文理解。這階段以大量矩陣乘法為主,Nvidia GPU歷來擅長此道。
– Decode階段:是真正的逐字生成階段,模型一個token一個token地生成輸出,每個token都反饋進系統以預測下一個。此階段受制於記憶體頻寬,若資料從記憶體流向處理器不夠快,模型就會卡頓,無論GPU有多強大。這正是Nvidia的弱點,也是Groq特殊語言處理單元(LPU)和其SRAM記憶體大顯神威的地方。
Nvidia已宣布將推出專為此分工設計的Vera Rubin晶片系列,其中的Rubin CPX專注prefill,優化處理百萬token以上的龐大上下文。為了平衡成本,Rubin CPX放棄了昂貴的高頻寬記憶體(HBM),改用128GB新型GDDR7記憶體。雖然HBM速度極快(但仍不及Groq的SRAM),且用量有限且成本高昂,GDDR7則提供了更經濟的方式來處理巨量數據。
而Groq風格的晶片將成為Nvidia推理路線圖中高速的decode引擎。此舉旨在抵禦Google TPU等替代架構威脅,並保護Nvidia已深植十年的CUDA軟體生態系統。
Baker甚至預測,Nvidia與Groq的合作將導致其他專用AI晶片計劃被取消,僅剩Google TPU、Tesla AI5和AWS Trainium繼續存在。
2. SRAM的獨特優勢
Groq技術核心是SRAM。與PC中常見的DRAM或Nvidia H100 GPU上的HBM不同,SRAM直接刻劃於處理器邏輯中。
微軟風投基金M12管理合夥人Michael Stewart指出,SRAM移動數據的能耗最低,僅約0.1皮焦耳;相比之下,DRAM與處理器間的數據移動能耗高出20至100倍。
在2026年,智能體需實時推理,SRAM成為理想的「工作區」:模型能在此高速操作符號運算和複雜推理,避免外部記憶體來回傳輸的延遲和能耗。
不過SRAM體積大且製造成本高,容量有限。Weka公司AI主管Val Bercovici認為,SRAM優勢明顯的AI工作負載是8億參數及以下的小型模型。這市場不小,尤其是邊緣推理、低延遲、機器人、語音和物聯網裝置等場景,這些應用往往需要在手機等設備本地運行,避免雲端依賴,提升便利性、性能與隱私。
2025年模型蒸餾技術盛行,許多企業將巨型模型縮小為高效小模型。雖然SRAM不適合千億參數的前沿大模型,但卻完美契合這些小型高速模型。
3. Anthropic威脅:便攜式堆棧崛起
這筆交易背後另一不容忽視的推手是Anthropic成功打造了跨加速器可移植的軟體堆棧。
該公司開創了一種工程方法,讓其Claude模型能在多種AI加速器上運行,包括Nvidia GPU和Google的Ironwood TPU。過去,因為在Nvidia外運行高性能模型極為複雜,Nvidia壟斷地位得以維持。
Weka的Bercovici表示:「Anthropic能建立起同時支持TPU和GPU的軟體堆棧,市場沒有充分認識到這一點。」
Anthropic甚至承諾使用Google多達百萬顆TPU,算力超過一千兆瓦。這種多平台策略確保他們不受限於Nvidia定價和供應。
對Nvidia而言,Groq交易同樣是防禦之舉。透過整合Groq超高速推理IP,確保小模型及實時智能體等性能敏感工作負載仍可留在CUDA生態系統中,防止競爭對手跳槽至Google TPU。
4. 智能體「狀態維持」大戰:Manus與KV Cache
Groq協議出爐之際,Meta剛於兩天前收購了智能體先驅Manus,該公司專注於「狀態保持」。
若智能體無法記住十步前的操作,便無法完成市場調研或軟體開發等真實任務。KV Cache(鍵值緩存)是大型語言模型在prefill階段構建的「短期記憶」。
Manus報告稱,生產級智能體的輸入token和輸出token比率可達100:1。換言之,每說一個詞,智能體實際上在思考並記憶100個詞。KV Cache的命中率是生產智能體最重要指標,一旦緩存被「驅逐」,智能體就會失去思路,需耗費大量能量重算提示。
Groq的SRAM可作為這類智能體的高速「工作區」——主要針對小型模型,結合Nvidia的Dynamo框架與KVBM,Nvidia正打造一套「推理作業系統」,能將狀態分層存放於SRAM、DRAM、HBM及其他閃存中。
Supermicro技術推廣高級總監Thomas Jorgensen指出,對大型企業GPU集群而言,算力不再是瓶頸,瓶頸在於如何將數據送入GPU。GPU間帶寬增長速度遠超其他部分,提升數據流通效率成為關鍵。
這正是Nvidia推崇分解推理的原因。企業可利用專門的存儲層以記憶體級性能供數據,而內建Groq技術的晶片則負責高速token生成。
2026年的結論
————————
我們正步入極度專業化時代。過去數十年,主流廠商靠一種通用架構制霸市場,但往往忽視了邊緣需求。微軟M12的Michael Stewart以Intel忽視低功耗市場為例,Nvidia正傳遞出不會重蹈覆轍的訊息:「就連叢林之王也會收購人才和技術,這表明市場對更多選擇的渴求。」
給技術領袖的建議是:別再把堆棧設計成「一機櫃、一加速器、一方案」。2026年,成功者將明確標記工作負載類型,並根據特性分流至合適層級:
– prefill重 vs. decode重
– 長上下文 vs. 短上下文
– 互動式 vs. 批量處理
– 小模型 vs. 大模型
– 邊緣限制 vs. 數據中心假設
你的架構將隨這些標籤演化。2026年,「GPU策略」不再是一個採購決策,而是路由決策。勝利者不會問「我買了哪顆晶片」,而是問「每個token在哪裡運算,為什麼在那裡」。
—
評論與啟示
這篇報道細膩剖析了AI推理架構即將迎來的革命性變革,特別是Nvidia與Groq合作背後的戰略意義。過去,GPU憑藉其通用性與強大計算力成為AI推理的主力,但隨著模型規模與應用場景多樣化,單一架構無法兼顧龐大上下文處理和低延遲逐字生成的需求,分解式架構勢在必行。
Groq的SRAM優勢與Nvidia對記憶體層級的精細調控,展現了硬體設計正從「純算力競賽」轉向「算力與記憶體協同優化」的新階段。此外,Anthropic多平台軟體策略挑戰了Nvidia的生態壟斷,促使後者不得不尋求多元合作和技術補強。
這種多晶片、多記憶體層級和多軟體堆棧並存的複雜生態,對企業架構師提出了更高要求:必須精確識別不同工作負載特性,靈活調度資源,而非簡單依賴「最強GPU」。這反映出AI基礎設施正從「一體化」走向「模組化」和「專用化」,是技術成熟和市場細分的必然結果。
對香港及全球企業而言,這意味著未來AI部署將更複雜但也更具彈性。技術決策者應關注硬體記憶體架構的演變,並積極評估如何設計混合加速器方案,以適應多樣化應用需求。這也提醒我們,AI硬體不再是單純硬體問題,而是跨層軟硬整合、系統協同的綜合挑戰。
總結來說,Nvidia與Groq的合作不僅是商業策略,更是AI技術路線的一次重要轉折,預示著未來AI基礎設施將更加分散、專業與高效,值得業界持續關注與深入研究。
以上文章由GPT 所翻譯及撰寫。而圖片則由GEMINI根據內容自動生成。