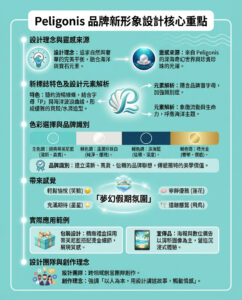
2024 年十大必備 Python 資料科學庫
Python 生態系統的豐富性有一個缺點:讓你難以決定哪個庫最適合你的需求。這篇文章嘗試通過推薦十個(以及一些額外的)資料科學中必不可少的庫來解決這個問題。
定義什麼是必備?
在資料科學中,必備的 Python 庫是那些能夠完成資料科學家工作中所有典型步驟的工具。由於沒有一個庫能涵蓋所有任務,因此大多數情況下,每個不同的資料科學任務都需要使用一個專門的庫。
Python 的生態系統非常豐富,通常意味著每個任務都有許多庫可供使用。
1. 資料收集及網頁抓取:Scrapy
Scrapy 是一個網頁抓取的 Python 庫,對於資料收集和網頁抓取任務至關重要,以其可擴展性和速度而聞名。它允許抓取多個頁面並跟隨鏈接。
為什麼它是最好的:
– 支援異步請求:能夠同時處理多個請求,加快了網頁抓取速度。
– 抓取框架:自動處理鏈接跟隨和分頁,非常適合抓取多個頁面。
– 自定義管道:允許在將抓取的資料保存到數據庫之前進行處理和清理。
值得一提的:
– BeautifulSoup – 適合較小的抓取任務
– Selenium – 通過瀏覽器自動化抓取動態內容
– Requests – 用於 HTTP 請求和與 API 互動
2. 資料操控、預處理及探索性資料分析 (EDA):pandas
Pandas 大概是最著名的 Python 庫。它旨在使資料操控的各個方面變得非常簡單,例如過濾、轉換、合併資料、統計計算和視覺化。
為什麼它是最好的:
– DataFrames:DataFrame 是一種類似表格的資料結構,使得資料操控和分析非常直觀。
– 處理缺失資料:內建許多用於填充和過濾資料的函數。
– I/O 功能:靈活處理不同文件格式的讀寫,例如 CSV、Excel、SQL、JSON 等。
– 描述性統計:快速生成資料的統計摘要,如使用 describe() 函數。
– 資料轉換:允許使用 apply() 和 groupby() 等方法。
– 與視覺化庫的簡單整合:儘管本身具有資料視覺化功能,但可以通過與 Matplotlib 或 seaborn 整合來提高。
值得一提的:
– NumPy – 用於數學運算和數組處理
– Dask – 一個可以將 pandas 或 NumPy 功能擴展到大數據集的並行計算庫
– Vaex – 用於處理超出核心的 DataFrames
– Matplotlib – 用於資料視覺化
– seaborn – 用於統計資料視覺化,基於 Matplotlib
– Sweetviz – 用於自動化 EDA 報告
3. 資料視覺化:Matplotlib
Matplotlib 可能是最通用的靜態資料視覺化 Python 庫。
為什麼它是最好的:
– 可自定義性:視覺化的每個元素——顏色、軸、標籤、刻度——都可以由用戶調整。
– 豐富的圖表選擇:可以選擇多種圖表類型,如折線圖、餅圖、直方圖、箱線圖到熱圖、樹狀圖、莖葉圖和 3D 圖。
– 良好的整合性:與其他庫(如 seaborn 和 pandas)良好整合。
值得一提的:
– seaborn – 使用更少的代碼進行更複雜的視覺化
– Plotly – 用於互動和動態視覺化
– Vega-Altair – 使用聲明性語法進行統計和互動圖表
4. 統計及時間序列分析:Statsmodels
Statsmodels 是經濟計量和統計任務的理想工具,專注於線性模型和時間序列。它提供了其他地方找不到的統計模型和假設檢驗工具。
為什麼它是最好的:
– 全面的統計模型:提供的統計模型範圍廣泛,包括線性回歸、離散、時間序列、生存和多變量模型。
– 假設檢驗:提供各種假設檢驗,如 t 檢驗、卡方檢驗、z 檢驗、ANOVA、F 檢驗、LR 檢驗、Wald 檢驗等。
– 與 pandas 整合:輕鬆與 pandas 整合,使用 DataFrames 作為輸入和輸出。
值得一提的:
– SciPy – 用於基本統計分析和概率分佈操作
– PyMC – 用於貝葉斯統計建模
– Pingouin – 用於快速假設檢驗和基本統計
– Prophet – 用於時間序列預測
– pandas – 用於基本時間序列操控
– Darts – 用於深度學習時間序列預測
5. 機器學習:scikit-learn
Scikit-learn 是一個多功能的 Python 庫,使得實現大多數常用於資料科學的機器學習算法非常簡單。
為什麼它是最好的:
– API:該庫的 API 易於使用,為實施所有算法提供一致的介面。
– 模型評估:內建許多模型評估工具,如交叉驗證、網格搜索和超參數調優。
– 算法選擇:提供了廣泛的監督和非監督學習算法,可能比你需要的還多。
值得一提的:
– XGBoost – 用於梯度提升和結構化資料
– LightGBM – 用於快速處理具有分類特徵的大數據集
– CatBoost – 用於分類特徵和梯度提升
6. 深度學習:TensorFlow
TensorFlow 是構建和部署深度神經網絡的首選庫。
為什麼它是最好的:
– 端到端工作流程:涵蓋從構建模型到部署的整個過程。
– 硬件加速:對圖形處理單元(GPUs)和張量處理單元(TPUs)的優化,加速了常見的深度學習任務,如大規模矩陣和張量運算。
– 預訓練模型:提供大量預構建模型,可用於遷移學習。
值得一提的:
– PyTorch – 用於複雜的神經網絡,如 CNNs 和 RNNs
– Theano/PyTensor – 用於研究
7. 自然語言處理:spaCy
spaCy 是一個以速度著稱的複雜 NLP 任務庫。
為什麼它是最好的:
– 高效快速:專為大規模 NLP 任務設計,其性能遠超大多數其他庫。
– 預訓練模型:提供多種語言的預訓練模型,使模型部署更容易和快速。
– 自定義:可以自定義處理管道。
值得一提的:
– NLTK – 用於教育和研究
– Transformers (Hugging Face) – 用於使用預訓練模型,如 BERT 和 GPT
– TextBlob – 用於基本 NLP 任務
8. 模型部署:Flask
Flask 以其靈活性、速度和易學性而聞名於模型部署任務。
為什麼它是最好的:
– 輕量框架:只需最少的設置步驟和很少的依賴,使得模型部署快速。
– 模塊化:你可以選擇需要的工具來完成任務,如路由、身份驗證和靜態文件服務。
– 可擴展性:通過添加 Redis、Docker 和 Kubernetes 等服務,輕鬆擴展。
值得一提的:
– FastAPI – 用於異步編程
– MS Power Automate (ex-MSflow) – 用於整個機器學習生命周期
– Streamlit – 用於網頁應用
9. 大數據及分佈式計算:PySpark
PySpark 是 Apache Spark 的 Python API。其輕鬆處理大數據的能力使其成為實時處理大型數據集的理想選擇。
為什麼它是最好的:
– 分佈式資料處理:內存計算和 Hadoop 分佈式文件系統(HDFS)允許快速處理海量數據集。
– 與 SQL 和 MLlib 兼容:這使得可以對大規模資料使用 SQL 查詢,並使 MLlib(Spark 的機器學習庫)中的模型更具可擴展性。
– 可擴展性:自動跨集群擴展,適合處理大型數據集。
值得一提的:
– Dask – 用於 pandas 類操作的並行和分佈式計算
– Ray – 用於機器學習、強化學習和分佈式訓練的 Python 應用程序擴展
– Hadoop (via Pydoop) – 用於分佈式文件系統和 MapReduce 任務
10. 自動化及工作流程編排:Apache Airflow
Apache Airflow 是管理工作流程和安排資料管道任務的絕佳工具。
為什麼它是最好的:
– DAGs:有向無環圖(DAG)允許創建任務之間的複雜依賴關係和序列。
– 任務調度:基於時間間隔或依賴關係的自動任務調度。
– 監控及視覺化:該庫具有網頁介面,用於監控工作流程和視覺化 DAG。
值得一提的:
– Prefect – 用於簡單和中等複雜的任務
– Luigi – 用於批處理任務
– Dagster – 用於管理資料資產
結論
這十大 Python 庫能夠涵蓋資料科學工作流程中基本上無法避免的所有任務。在大多數情況下,您不需要其他庫來完成端到端的資料科學項目。
當然,這並不意味著你不能學習其他庫來替代或補充我上面討論的十個庫。然而,這些庫通常是其領域中最受歡迎的。
雖然我通常反對使用受歡迎程度作為質量的證據,但這些 Python 庫的受歡迎是有原因的。特別是如果你是資料科學和 Python 的新手。從這些庫開始,深入了解它們,隨著時間的推移,你將能夠判斷其他庫是否更適合你和你的工作。
編者評論
這篇文章提供了一個全面的指南,介紹了在資料科學領域中不可或缺的 Python 庫。每個庫的選擇都基於其在特定任務中的優勢和靈活性,這對於初學者和有經驗的資料科學家都非常有幫助。文章中提到的庫不僅提供了基本功能,還支持擴展和自定義,這對於應對不斷變化的技術需求至關重要。
在香港這樣一個快速發展的科技中心,資料科學的應用越來越廣泛,這些庫的掌握將有助於提高從業者的競爭力。隨著資料規模和複雜性的增加,這些工具也將不斷演變,以滿足新興需求。因此,對於資料科學家來說,不斷學習和適應新技術是保持行業領先地位的關鍵。
以上文章由特價GPT API KEY所翻譯