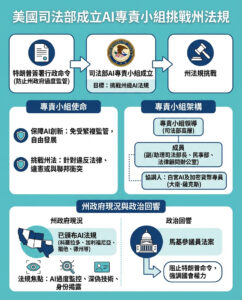
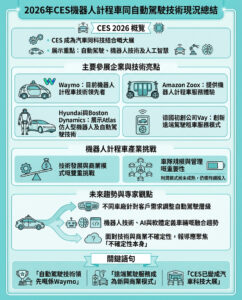
最優質的開源AI模型:所有免費使用選項的詳細解釋
隨著生成性AI(Gen AI)在兩年前公開推出後,該技術已顯著進步,並帶來了能夠以驚人準確性和創造力創建文本、圖像和其他媒介的轉型應用。
開源生成模型對開發者、研究人員和希望利用尖端AI技術的組織而言,極具價值,因為它們不需要支付高昂的授權費用或受到限制的商業政策。接下來,讓我們深入了解。
開源模型與專有模型的比較
開源AI模型提供多項優勢,包括自定義、透明度和社區驅動的創新。這些模型允許用戶根據特定需求進行調整,並受益於持續的增強。此外,它們通常附帶允許商業和非商業使用的許可證,這提高了它們在各種應用中的可訪問性和適應性。
不過,開源解決方案並不總是最佳選擇。在需要嚴格遵循法規、數據隱私和專業支持的行業中,專有模型往往表現更佳。它們提供更強的法律框架、專門的客戶支持和針對行業需求的優化。當組織需要實時更新、高級安全性或專業功能時,專有模型可以提供更強大和安全的解決方案,有效平衡開放性與對質量和問責的嚴格要求。
開源AI的定義
開源倡議組織(OSI)最近推出了開源AI定義(OSAID),以明確什麼才算真正的開源AI。要滿足OSAID標準,模型必須在設計和訓練數據上完全透明,使用者能夠自由重建、調整和使用。
然而,一些流行模型,包括Meta的LLaMA和Stability AI的Stable Diffusion,因為有許可限制或缺乏關於訓練數據的透明度,無法完全符合OSAID。
在OSAID的驗證過程中,OSI評估了以下內容:
– 符合要求的模型:Pythia(Eleuther AI)、OLMo(AI2)、Amber和CrystalCoder(LLM360)、T5(Google)。
– 可能符合要求的模型:Bloom(BigScience)、Starcoder2(BigCode)和Falcon(TII)可能通過對許可條款或透明度進行小幅調整來滿足OSAID標準。
– 不符合要求的模型:LLaMA(Meta)、Grok(X/Twitter)、Phi(Microsoft)和Mixtral(Mistral)缺乏必要的透明度或施加限制性許可條款。
LLaMA及其他不合規架構
Meta的LLaMA架構因其限制性研究專用許可和缺乏關於訓練數據的完全透明度而被視為不合規,限制了商業使用和重現性。衍生模型,如Mistral的Mixtral和Vicuna團隊的MiniGPT-4,繼承了這些限制,進一步傳播了LLaMA的非合規性。
此外,除了基於LLaMA的模型外,其他廣泛使用的架構也面臨類似問題。例如,Stability AI的Stable Diffusion使用Creative ML OpenRAIL-M許可,該許可包含的道德限制偏離了OSAID對無限制使用的要求。同樣,xAI的Grok將專有元素與使用限制結合,挑戰其與開源理想的一致性。
這些例子突顯了滿足OSAID標準的難度,許多AI開發者在開放訪問與商業和道德考量之間尋求平衡。
對組織的影響:OSAID合規與不合規
選擇OSAID合規模型可為組織提供透明度、法律保障和完整的可定制功能,這對於負責任和靈活的AI使用至關重要。這些合規模型遵循道德實踐,並受益於強大的社區支持,促進協作開發。
相對而言,不合規模型可能限制適應性,並更多依賴專有資源。對於優先考慮靈活性和與開源價值觀一致的組織而言,OSAID合規模型是有利的。然而,當需要專有特性時,不合規模型仍然可以是有價值的選擇。
理解開源AI模型的許可證
開源AI模型是根據定義使用、修改和共享條件的許可證發布的。雖然一些許可證與傳統的開源標準一致,但其他許可證則包含限制或道德指導方針,這妨礙了它們完全符合OSAID的要求。主要許可證包括:
– **Apache 2.0**:一種寬鬆的許可證,允許免費使用、修改和分發,並附帶專利授權。Apache 2.0獲得OSI批准,並在開源項目中廣受歡迎,提供靈活性和法律保護。
– **MIT**:另一種寬鬆的許可證,只要求重用時標明來源。與Apache 2.0類似,MIT也獲得OSI批准,廣泛採用,簡單且限制最少。
– **Creative ML OpenRAIL-M**:一種專為AI應用設計的許可證,允許廣泛使用,但施加道德指導方針以防止有害使用。由於包含與OSI無限制自由原則相衝突的使用限制,OpenRAIL-M並未獲得OSI批准,但受到開發者的重視,旨在優先考慮AI的道德使用。
– **CC BY-SA**:Creative Commons Share-Alike許可證允許免費使用,並要求衍生作品保持開源。雖然它鼓勵開放合作,但並未獲得OSI批准,更常用於內容而非代碼,因為它對於軟件應用缺乏一些靈活性。
– **CC BY-NC 4.0**:一種Creative Commons許可證,允許免費使用並要求標明來源,但限制商業應用。此許可證用於某些模型權重(如Meta的MusicGen和AudioGen),限制了模型在商業環境中的可用性,並不符合OSI的開源標準。
– **自定義許可證**:我們名單上的許多模型,如IBM的Granite和Nvidia的NeMo,運行在專有或自定義許可證下。這些模型通常施加特定的使用條件或修改傳統開源條款,以符合商業目標,使其不符合開源原則。
– **僅限研究許可證**:某些模型,如Meta的LLaMA和Codellama系列,僅在研究使用條款下提供。這些許可證限制使用於學術或非商業目的,並妨礙廣泛的社區驅動項目,因為它們不符合OSI的開源標準。
運行開源AI模型的要求
運行開源生成AI模型需要特定的硬件、軟件環境和工具集,以進行模型訓練、微調和部署任務。擁有數十億參數的高性能模型受益於強大的GPU設置,如Nvidia的A100或H100。
所需的基本環境通常包括Python和機器學習庫,如PyTorch或TensorFlow。專門的工具集,包括Hugging Face的Transformers庫和Nvidia的NeMo,簡化了微調和部署的過程。Docker有助於在不同系統之間保持一致的環境,而Ollama則允許在兼容系統上本地執行大型語言模型。
以下圖表突顯了管理開源AI模型所需的重要工具集、推薦硬件及其特定功能:
| 工具集 | 目的 | 要求 | 使用 |
|———————–|————————————|———————————|——————————|
| Python | 主要編程環境 | N/A | 對模型進行腳本編寫和配置 |
| PyTorch | 模型訓練和推理 | GPU(例如Nvidia A100、H100) | 廣泛使用的深度學習模型庫 |
| TensorFlow | 模型訓練和推理 | GPU(例如Nvidia A100、H100) | 替代的深度學習庫 |
| Hugging Face Transformers | 模型部署和微調 | GPU(首選) | 訪問、微調和部署模型的庫 |
| Nvidia NeMo | 多模態模型支持和部署 | Nvidia GPUs | 專為Nvidia硬件和多模態任務優化 |
| Docker | 環境一致性和部署 | 支持GPU | 容器化模型以便於部署 |
| Ollama | 在本地運行大型語言模型 | macOS、Linux、Windows,支持GPU | 在兼容系統上本地運行LLMs |
| LangChain | 構建LLM應用 | Python 3.7+ | 組成和部署LLM驅動的應用程序 |
| LlamaIndex | 將LLMs與外部數據源連接 | Python 3.7+ | 將LLMs與數據源整合的框架 |
這一設置建立了一個穩健的框架,能夠有效地管理生成AI模型,從實驗到生產就緒的部署。每個工具集擁有獨特的優勢,使開發者能夠根據特定項目需求量身定制其環境。
選擇合適的模型
選擇合適的生成AI模型取決於多個因素,包括許可要求、期望的性能和特定功能。雖然較大的模型通常提供更高的準確性和靈活性,但它們需要龐大的計算資源。相比之下,較小的模型更適合資源受限的應用和設備。
需要注意的是,這裡列出的多數模型,即使是那些擁有傳統開源許可的模型,如Apache 2.0或MIT,也不符合開源AI定義(OSAID)。這一差距主要是由於關於訓練數據透明度和使用限制的要求,而OSAID強調這是實現真正開源AI的必要條件。然而,某些模型,如Bloom和Falcon,顯示出潛在的合規性,隨著許可或透明度協議的輕微調整,可能會隨著時間的推移實現完全合規。
以下表格提供了主要開源生成AI模型的組織概覽,按類型、發行者和功能分類,以幫助你選擇最適合你需求的選項,無論是完全透明的社區驅動模型還是具備特定功能和許可要求的高性能工具。
語言模型
語言模型在基於文本的應用中至關重要,如聊天機器人、內容創建、翻譯和摘要。它們是自然語言處理(NLP)的基礎,不斷改善對語言結構和上下文的理解。
值得注意的模型包括Meta的LLaMA、EleutherAI的GPT-NeoX和Nvidia的NVLM 1.0系列,每個模型在多語言、大規模和多模態任務中都有其獨特的優勢。
| 發行者及模型 | 參數大小 | 許可證 | 突出特點 |
|———————–|——————-|——————-|———————————|
| Google T5 | 小型至XXL | Apache 2.0 | 高性能語言模型,符合OSAID |
| EleutherAI Pythia | 各種 | Apache 2.0 | 專注於可解釋性,符合OSAID |
| Allen Institute for AI (AI2) OLMo | 各種 | Apache 2.0 | 開放語言研究模型,符合OSAID |
| BigScience BLOOM | 176B | OpenRAIL-M | 多語言,負責任的AI,符合OSAID潛力 |
| BigCode Starcoder2 | 各種 | Apache 2.0 | 代碼生成,符合OSAID潛力 |
| TII Falcon | 7B, 40B | Apache 2.0 | 高效且高性能,符合OSAID潛力 |
| AI21 Labs Jamba系列 | 小型至大型 | 自定義 | 語言和聊天生成 |
| AI Singapore Sea-Lion | 7B | 自定義 | 語言和文化表現 |
| Alibaba Qwen系列 | 7B | 自定義 | 雙語模型(中文,英語) |
| Databricks Dolly 2.0 | 12B | CC BY-SA 3.0 | 開放數據集,商業使用 |
| EleutherAI GPT-J | 6B | Apache 2.0 | 通用語言模型 |
| EleutherAI GPT-NeoX | 20B | MIT | 大規模文本生成 |
| Google Gemma 2 | 2B, 9B, 27B | Apache 2.0 | 語言和代碼生成 |
| IBM Granite系列 | 3B, 8B | 自定義 | 摘要、分類、RAG |
| Meta LLaMA 3.2 | 1B至405B | 僅限研究 | 先進的NLP,多語言 |
| Microsoft Phi-3系列 | 小型至中型 | MIT | 推理,具有成本效益 |
| Mistral AI Mixtral 8x22B | 8x22B | Apache 2.0 | 稀疏模型,高效推理 |
| Mistral AI Mistral 7B | 7B | Apache 2.0 | 密集,多語言文本生成 |
| Nvidia NVLM 1.0系列 | 72B | 自定義 | 高性能多模態LLM |
| Rakuten RakutenAI系列 | 7B | 自定義 | 多語言聊天,NLP |
| xAI Grok-1 | 314B | Apache 2.0 | 大規模語言模型 |
圖像生成模型
圖像生成模型能根據文本提示創建高質量視覺圖像或藝術作品,對內容創作者、設計師和市場營銷人員來說非常重要。
Stability AI的Stable Diffusion因其靈活性和輸出質量而廣泛應用,而DeepFloyd的IF則強調生成具有語言理解的現實視覺。
| 發行者及模型 | 參數大小 | 許可證 | 突出特點 |
|———————–|——————-|——————-|———————————|
| Stability AI Stable Diffusion 3.5 | 2.5B至8B | OpenRAIL-M | 高質量圖像合成 |
| DeepFloyd IF | 400M至4.3B | 自定義 | 具有語言理解的現實視覺 |
| OpenAI DALL-E 3 | 未披露 | 自定義 | 最先進的文本到圖像合成 |
| Google Imagen | 未披露 | 自定義 | 從文本生成高保真圖像 |
| Midjourney | 未披露 | 自定義 | 藝術性和風格化圖像生成 |
| Adobe Firefly | 未披露 | 自定義 | 集成於Adobe產品中的AI圖像生成 |
視覺模型
視覺模型分析圖像和視頻,支持物體檢測、分割和從文本提示生成視覺內容。
這些技術對包括醫療、自治車輛和媒體等多個行業都有益處。
| 發行者及模型 | 參數大小 | 許可證 | 突出特點 |
|———————–|——————-|——————-|———————————|
| Meta SAM 2.1 | 38.9M至224.4M | Apache 2.0 | 視頻編輯,分割 |
| NVIDIA Consistency | 未披露 | 自定義 | 角色在視頻幀中的一致性 |
| NVIDIA VISTA-3D | 未披露 | 自定義 | 醫學成像,解剖學分割 |
| NVIDIA NV-DINOv2 | 未披露 | 非商業性 | 圖像嵌入生成 |
| Google DeepLab | 未披露 | Apache 2.0 | 高質量語義圖像分割 |
| Microsoft Florence | 0.23B, 0.77B | MIT | 用於計算機視覺的通用模型 |
| OpenAI CLIP | 400M | MIT | 文本和圖像理解 |
音頻模型
音頻模型處理和生成音頻數據,使語音識別、文本到語音合成、音樂創作和音頻增強成為可能。
| 發行者及模型 | 大小 | 許可證 | 突出特點 |
|———————–|——————-|——————-|———————————|
| Coqui.ai TTS | N/A | MPL 2.0 | 文本到語音合成,多語言支持 |
| ESPnet | N/A | Apache 2.0 | 端到端語音處理工具包 |
| Facebook AI wav2vec 2.0 | Base (95M), Large (317M) | Apache 2.0 | 自我監督語音識別 |
| Hugging Face Transformers(語音模型) | 各種 | Apache 2.0 | ASR和TTS模型的集合 |
| Magenta MusicVAE | N/A | Apache 2.0 | 音樂生成和插值 |
| Meta MusicGen | N/A | MIT / CC BY-NC 4.0 | 從文本提示生成音樂 |
| Meta AudioGen | N/A | MIT / CC BY-NC 4.0 | 從文本提示生成音效 |
| Meta EnCodec | N/A | MIT / CC BY-NC 4.0 | 高質量音頻壓縮 |
| Mozilla DeepSpeech | N/A | MPL 2.0 | 端到端語音轉文本引擎 |
| NVIDIA NeMo(語音模型) | 各種 | Apache 2.0 | 專為Nvidia GPU優化的ASR和TTS模型 |
| OpenAI Jukebox | N/A | MIT | 具備流派/藝術家條件的神經音樂生成 |
| OpenAI Whisper | 39M至1.6B | MIT | 多語言語音識別和轉錄 |
| TensorFlow TFLite語音模型 | N/A | Apache 2.0 | 為移動設備優化的語音識別模型 |
多模態模型
多模態模型結合文本、圖像、音頻和其他數據類型,從各種輸入創建內容。
這些模型在需要語言、視覺和感官理解的應用中非常有效。
| 模型名稱 | 參數大小 | 許可證 | 突出特點 |
|———————–|——————-|——————-|———————————|
| Allen Institute for AI (AI2) Molmo | 1B, 70B | Apache 2.0 | 一種處理文本和視覺輸入的多模態AI模型,符合OSAID |
| Meta ImageBind | N/A | 自定義 | 整合六種數據類型:文本、圖像、音頻、深度、熱成像和IMU |
| Meta SeamlessM4T | N/A | 自定義 | 提供多語言翻譯和轉錄服務 |
| Meta Spirit LM | N/A | 自定義 | 將文本和語音結合以生成自然的輸出 |
| Microsoft Florence-2 | 0.23B, 0.77B | MIT | 熟練處理計算機視覺和語言任務 |
| NVIDIA VILA | N/A | 自定義 | 有效處理視覺-語言任務 |
| OpenAI CLIP | 400M | MIT | 在文本和圖像理解方面表現出色 |
| Vicuna Team MiniGPT-4 | 13B | Apache 2.0 | 能夠理解文本和圖像 |
檢索增強生成(RAG)
RAG模型將生成AI與信息檢索相結合,允許它們將來自龐大數據集的相關數據納入其回應中。
| 發行者及模型 | 參數大小 | 許可證 | 突出特點 |
|———————–|——————-|——————-|———————————|
| BAAI BGE-M3 | N/A | 自定義 | 稠密和稀疏檢索優化 |
| IBM Granite 3.0系列 | 3B, 8B | 自定義 | 先進的檢索、摘要、RAG |
| Nvidia EmbedQA & ReRankQA | 1B | 自定義 | 多語言QA,GPU加速檢索 |
專用模型
專用模型針對特定領域進行優化,如編程、科學研究和醫療,提供針對其領域量身定制的增強功能。
| 發行者及模型 | 參數大小 | 許可證 | 突出特點 |
|———————–|——————-|——————-|———————————|
| Meta Codellama系列 | 7B, 13B, 34B | 自定義 | 代碼生成,多語言編程 |
| Mistral AI Mamba-Codestral | 7B | Apache 2.0 | 專注於編碼和多語言能力 |
| Mistral AI Mathstral | 7B | Apache 2.0 | 專注於數學推理 |
護欄模型
護欄模型通過檢測和減少偏見、不當內容和有害反應,確保安全和負責任的輸出。
| 發行者及模型 | 參數大小 | 許可證 | 突出特點 |
|———————–|——————-|——————-|———————————|
| NVIDIA NeMo Guardrails | N/A | Apache 2.0 | 用於添加可編程護欄的開源工具包 |
| Google ShieldGemma | 2B, 9B, 27B | 自定義 | 基於Gemma 2的安全分類模型 |
| IBM Granite-Guardian | 8B | 自定義 | 檢測不道德或有害內容 |
選擇開源模型
生成AI的格局正在迅速演變,開源模型對於使先進技術對所有人可及至關重要。這些模型允許自定義和協作,打破了限制AI開發於大型企業的障礙。
開發者可以通過選擇開源生成AI來根據自身需求量身定制解決方案,貢獻於全球社區,推進技術進步。可用模型的多樣性——從語言和視覺到專注於安全的設計——確保幾乎可用於任何應用的選擇。
支持開源AI社區將對於促進道德和創新的AI發展至關重要,這不僅有利於個別項目,還能負責任地推進技術進步。
在這個高速發展的科技環境中,開源AI模型的種種可能性讓我們看到了更廣闊的創新前景。隨著社區的努力和合作,我們可以期待未來的AI技術在多個領域中發揮更大的作用,並確保其發展符合道德標準及社會需求。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。