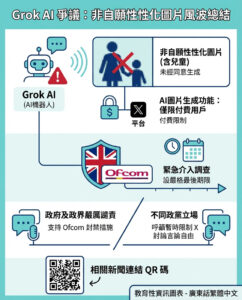
MedHELM:一個全面的醫療基準,用於評估語言模型在真實臨床任務中的表現
大型語言模型(LLMs)在醫學領域被廣泛使用,協助診斷決策、病人分類、臨床報告和醫學研究工作流。儘管它們在控制的醫療測試中表現出色,例如美國醫學執照考試(USMLE),但其在現實世界中的實用性仍未經充分測試。現有的評估大多依賴合成基準,無法真實反映臨床實踐的複雜性。去年的一項研究顯示,僅有5%的LLM分析依賴實際病人資訊,這揭示了真實世界可用性測試與實際醫療決策功能之間的巨大差距,並對其在現實臨床環境中的安全性和有效性提出了質疑。
目前最先進的評估方法主要使用合成數據集、結構化知識考試和正式醫學考試來評分語言模型。雖然這些考試測試了理論知識,但並未反映出真實病人情境中的複雜互動。大多數測試只產生單一指標的結果,未能關注事實的準確性、臨床適用性和反應偏差的可能性等關鍵細節。此外,廣泛使用的公共數據集同質化,影響了在不同醫療專業和病人群體中的泛化能力。另一個重大缺陷是,大多數針對這些基準進行訓練的模型表現出過擬合測試範式,因此在動態醫療環境中失去了大部分性能。缺乏全面系統框架來包容真實病人互動,進一步削弱了在實際醫療使用中採用它們的信心。
研究人員開發了MedHELM,一個全面的評估框架,旨在針對真實醫療任務進行LLM測試,並採用多指標評估和專家修訂的基準來填補這些空白。它基於斯坦福大學的語言模型全面評估(HELM),並在五個主要領域進行系統評估:
1. 臨床決策支持
2. 臨床筆記生成
3. 病人溝通與教育
4. 醫學研究協助
5. 行政和工作流程
總共涵蓋了22個子類別和121個具體的醫療任務,確保了關鍵醫療應用的廣泛覆蓋。與早期標準相比,MedHELM使用實際的臨床數據,通過結構化和開放式任務評估模型,並應用多方面的評分範式。這種全面的覆蓋使其不僅能測量知識的回憶,還能評估臨床適用性、推理精確性和日常實用性。
基準過程由一個廣泛的數據集基礎設施支持,共包含31個數據集。這些數據集包括11個新開發的醫療數據集,以及20個從現有臨床記錄中獲得的數據集,涵蓋不同醫療領域,確保評估準確地反映真實世界的醫療挑戰,而非人為設計的測試場景。
數據集轉換為標準化參考的過程是系統的,涉及:
– 上下文定義:模型必須分析的特定數據段(例如,臨床筆記)。
– 提示策略:指導模型行為的預定指令(例如,“確定病人的HAS-BLED分數”)。
– 參考回應:經臨床驗證的輸出以進行對比(例如,分類標籤、數值或基於文本的診斷)。
– 評分指標:結合精確匹配、分類準確性、BLEU、ROUGE和BERTScore進行文本相似性評估。
這種方法的一個例子是MedCalc-Bench,測試模型在臨床上重要的數值計算上執行的能力。每個數據輸入包含病人的臨床歷史、一個診斷問題和經專家驗證的解決方案,從而能夠對醫療推理和精確性進行嚴格測試。
對六個不同規模的LLM進行的評估揭示了根據任務複雜性而不同的特點和缺點。大型模型如GPT-4o和Gemini 1.5 Pro在醫療推理和計算任務中表現良好,並在臨床風險評估和偏見識別等任務中顯示出更高的準確性。中型模型如Llama-3.3-70B-instruct在預測醫療任務如住院再入院風險預測中表現競爭力。小型模型如Phi-3.5-mini-instruct和Qwen-2.5-7B-instruct在領域密集型知識測試中表現不佳,特別是在心理健康諮詢和高級醫學診斷方面。
除了準確性外,對結構化問題的回答遵從性也有所不同。一些模型不會回答醫療敏感問題或不會以所需格式回答,這影響了它們的整體表現。測試還發現目前的自動化評分標準存在不足,因為傳統的NLP評分機制往往忽視了真實臨床準確性。在大多數基準中,當使用BERTScore-F1作為指標時,模型之間的性能差異仍然微不足道,這表明目前的自動評估程序可能未能充分捕捉臨床可用性。結果強調了需要更嚴格的評估程序,融入基於事實的評分和明確的臨床醫生反饋,以確保評估的可靠性。
隨著臨床指導的多指標評估框架的出現,MedHELM提供了一種全面且可靠的方法來評估醫療領域的語言模型。其方法論保證LLMs將在實際臨床任務、組織推理測試和多樣化數據集上進行評估,而非人造測試或簡化基準。其主要貢獻包括:
– 一個結構化的121個現實世界醫療任務的分類,提升AI在臨床環境中的評估範疇。
– 使用真實病人數據來加強模型評估,超越理論知識測試。
– 對六個最先進的LLMs進行嚴格評估,識別優勢和需要改進的地方。
– 呼籲改進評估方法,強調基於事實的評分、可控性調整和直接的臨床驗證。
後續的研究工作將集中於通過引入更多專門數據集、簡化評估流程和實施來自醫療專業人士的直接反饋來改進MedHELM。這一框架克服了人工智能評估中的重大限制,為大型語言模型在當代醫療系統中的安全、有效和臨床相關的整合奠定了堅實的基礎。
這項研究的出現,無疑是對當前醫療AI應用的一次重要推進,展示了如何在真實世界中更有效地利用語言模型來解決醫療問題。隨著醫療需求的日益增加,這樣的評估框架不僅能促進技術進步,還能提高醫療服務的質量與安全性,值得業界持續關注與投入。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。