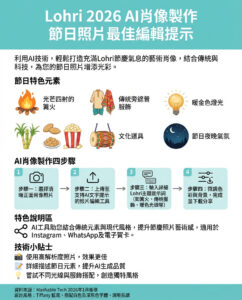
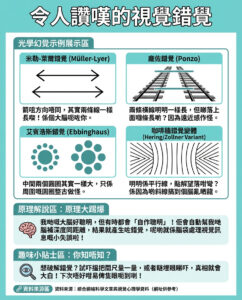
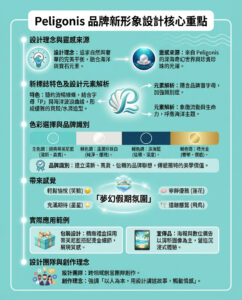
如何識別AI生成的文本:七種方法告訴你內容是否由機器人創作
隨著AI生成內容在我們日常生活中變得越來越普遍,你可能會想:「我怎樣知道AI文本?」與圖像或視頻不同,合成文本幾乎無法用肉眼辨別。隨著AI技術的演進,這些模型變得愈來愈難以檢測。好消息是,像圖像和視頻這樣的內容用肉眼並不難辨識。
檢測AI生成文本的方法
如果你是一位教師或是經驗豐富的網絡使用者,識別AI生成文本的秘訣是什麼?其實比你想像中簡單:使用你的眼睛。事實上,有方法可以訓練人眼識別AI語句。專家如麻省理工科技評論的Melissa Heikkilä指出,這些機器的「魔力」在於「正確性的幻影」。
每個人的寫作風格都不相同,但有一些共同的模式。如果你曾在企業工作,你會知道大家在給老闆寫備忘錄時會使用相同的通用短語。因此,AI文本檢測器經常將內容標記為「可能是AI生成」——因為區分平淡的人類寫作風格與通用的AI生成聲音幾乎是不可能的。
以下是一些識別潛在AI生成文本的技巧:
– 注意頻繁使用「the」、「it」和「its」等詞語。
– 缺乏拼寫錯誤——AI文本通常過於完美。
– 結論性陳述能簡潔地總結段落。
– 過於冗長或填充的寫作風格。
– 虛假或捏造的信息和來源。
– 語氣比作者通常的提交更為高級。
– 重複的短語或異常流暢的語法。
市場上也有AI文本檢測器可供使用,但根據我的經驗,它們往往不如你自己的眼睛可靠。
AI文本檢測器:為什麼它們不可靠
雖然一些解決方案正在出現,但並不全是壞消息。像ChatGPT和競爭者Gemini及Claude的推出,促進了一個專注於AI文本檢測的產業的成長。像ZeroGPT這樣的平台是響應OpenAI的語言模型而出現的,而Grammarly和Copyleaks等工具——最初設計用於檢測抄襲——也轉向處理AI生成內容。
根據不同的觀點,AI文本檢測目前被認為是識別AI生成內容或其數字蛇油的最佳方法。然而,後者可能更接近事實。沒有任何AI檢測器是100%準確的(甚至許多聲稱的99%也不然)。即使在理想條件下,這些工具的可靠性往往也是好壞參半。
哥倫比亞大學軟件系統實驗室的教授兼共同主任Junfeng Yang表示:「問題在於這些模型變得越來越流利,因此舊的檢測器開始失效。」他解釋,隨著AI生成的文本變得越來越複雜,它「開始使用與人類寫作非常相似的詞彙和句子結構,使其更難以識別,即使是使用先進的檢測器。」
測試AI文本檢測器的準確性
儘管像GPTZero或Hive Moderation這樣的工具做出了一些大膽的承諾,但讓AI檢測器將人類創作的內容標記為機器生成的其實相當簡單。這些系統通常分析解釋或總結想法的文本行,這使它們容易出現誤報。例如,我測試了一個我匆忙從記憶中寫出的《權力的遊戲》基本摘要,幾乎在每一個工具中都被標記為「可能是AI生成的」。
我然後將這個《權力的遊戲》摘要輸入ChatGPT,要求它進行改寫——讓它變得更長且不那麼直接。
以下是我寫的內容:
《權力的遊戲》的情節圍繞幾個家族在虛構的維斯特洛大陸上展開。首先是統治北方的史塔克家族,其次是統治西部的蘭尼斯特家族。西部的長女瑟曦是維斯特洛的女王,與羅伯特·巴拉席恩結婚。羅伯特來自風暴之地,奪取了塔格利安家族的王位——這是一群在1000多年前征服這片土地的龍騎士,但隨著內部鬥爭,他們逐漸失去了對維斯特洛的控制。該系列由喬治·R·R·馬丁創作,目前已在五本書中記錄——《權力的遊戲》、《列王的紛爭》、《劍風傳奇》、《烏鴉的盛宴》和《與龍共舞》。該系列還計劃再出版兩本書,預計《冬之風》將於2025年發行。
以下是ChatGPT的「改進」版本:
《權力的遊戲》將觀眾帶入維斯特洛這個殘酷、血腥的棋盤,權力是獎品,道德則是可談判的。領頭的是統治冰冷北方的史塔克家族,他們的剛毅榮譽在這個背叛成為貨幣的土地上顯得如同古董。與此形成鮮明對比的是來自奢華西部的蘭尼斯特家族,這個家族是人人愛恨交織的對象——瑟曦·蘭尼斯特坐在維斯特洛的王座上。她與來自風暴之地的酗酒王羅伯特·巴拉席恩的婚姻是一場地獄般的政治聯姻,雙方皆以謊言和相互厭惡為紐帶。然而,王座本身擁有血腥的歷史。羅伯特是在推翻塔格利安家族的叛亂後奪取王位的,這個長期統治的龍騎士王朝曾經不可阻擋,但最終因偏執和內戰而崩潰。他們的火焰巨獸曾經燒盡天空,但家族內部的鬥爭使他們的帝國轟然倒塌,僅留下昔日榮耀的低語。與此同時,喬治·R·R·馬丁的浩瀚史詩在五本書中繼續展開,這些書籍充滿了戰場上的屠殺、政治陰謀和心碎的背叛。雖然粉絲們貪婪地吞噬每一頁,但他們依然焦急地等待著那場似乎已經等待了無數歲月的《冬之風》,現在又有了2025年即將到來的微弱承諾。但在維斯特洛,諾言——就像聯盟一樣——注定要被打破。
我的測試結果各不相同。我最初測試的工具之一是Scribbr,它將我的原始摘要標記為「100%可能是AI生成的」。但是當我將其替換為AI增強版本時,Scribbr卻驚人地將可能性降至僅48%。
我在Winston AI測試的結果也是如此,原始文本被標記為39%可能是由GPT-4生成的。諷刺的是,當實際的GPT-4摘要出現時,它只給了1%的可能性。
Hive Moderation在分析我的作品時完全失準,未能標記我提交的任何摘要。根據該系統,兩者都被自信地標記為人類創作的內容。
如果我僅僅要求ChatGPT隨意生成一段關於任何主題的段落並將其複製粘貼到各種文本檢測器中,它幾乎總是會立即被標記為AI生成的。但這實際上強調了問題:如果沒有具體的指令,ChatGPT的默認寫作風格往往平淡、公式化且直白客觀。
這種可預測的乏味語調是觸發這些誤報的原因——而不是這些網站聲稱擁有的高級內部技術來區分AI內容與人類內容。即使像Originality這樣的工具正確標記了兩個AI寫作的實例,稍微改動句子就能完全改變結果。只需稍微重新措辭,以前被標記為「100%信心」的AI生成內容,瞬間就可以被標記為「可能原創」。
總而言之,這裡是我測試過的免費AI文本檢測工具的列表。為了增加變化,我還使用了一些我在研究生時期寫的學術論文的文學評論,看看它們是否會因為使用華麗的寫作來增加字數而標記我。這些工具包括:
– GPTZero
– ZeroGPT
– Hive Moderation
– Scribbr
– CopyLeaks
– Originality.ai
– Grammarly
– GPT-2 Output Detector
– Writefull X
– Winston AI
如果你的寫作聽起來像是平淡的八年級書面報告,AI檢測器可能會迅速將你標記為需要進行圖靈測試的機器人。這一測試顯示,只需避免某些結構模式就能輕鬆欺騙AI檢測器。這對於這些工具背後的公司來說是一個重大頭痛,尤其是許多公司提供訂閱服務,並打算將其API出售給學校和企業作為B2B解決方案。
雖然這些工具在檢測抄襲方面相當有效,但顯然它們識別AI生成文本的能力仍需認真改進。這種不一致性難以忽視——將相同文本提交給多個檢測器,你會得到截然不同的結果。某一工具標記為AI生成的內容,可能會被另一工具無視。鑑於這種可靠性缺失,目前很難自信地推薦這些工具。
為什麼檢測AI生成文本如此困難?
人類語言極其多變和複雜——這是AI生成文本難以檢測的主要原因之一。
IEEE會員、德保羅大學AI項目主席Bamshad Mobasher指出,「文本是這些模型的訓練基礎。因此,它們更容易模仿人類的對話。」
「檢測工具尋找模式——重複的短語、過於規律的語法結構等等。」Mobasher表示,「有時,人類更容易識別,比如文本「過於完美」,但確定它是AI生成的則具有挑戰性。」
與可以產生多餘手指或扭曲面孔特徵的圖像生成器不同,Mobasher解釋,LLM依靠統計概率生成文本——使其輸出感覺更為流暢。因此,識別AI生成文本中的錯誤——如微妙的措辭或細微的語法不規則——對檢測器和人類讀者來說都更加困難。
這也使得AI生成文本變得更加危險。Mobasher警告說,「這使得在大規模上生成和傳播虛假信息變得更加容易。」隨著LLM生成流暢、精緻的文本,能夠模仿權威聲音,普通人辨別事實與虛構的難度大增。
Yang表示:「使用AI,發起這些攻擊變得更加容易。你可以使電子郵件非常流利,傳達你想要的信息,甚至包含有關目標在公司角色或任務的個性化信息。」
除了潛在的濫用,AI生成文本還使互聯網的質量下降。OpenAI和Anthropic等公司的LLM從公開數據中抓取以訓練它們的模型。然後,這些AI生成的文章被發佈到網上,然後又被重新抓取,形成無休止的循環。
這種內容的循環使用降低了網絡上信息的整體質量,創造出一個越來越通用、重複的材料的反饋循環,讓人難以找到真實、優質的內容。
我們對AI的迅速發展及其對互聯網內容的有害影響無能為力,但至少你可以利用你的媒體素養知識來幫助你辨別什麼是人類創作的,什麼是機器生成的。
Yang建議:「如果你看到一篇文章或報告,不要盲目相信——尋找佐證的來源,尤其是當某些內容看起來不太對勁的時候。」
這篇文章不僅揭示了AI生成文本的複雜性,也提醒我們在這個數字時代中保持批判性思維的重要性。隨著AI技術的進步,未來我們將面對越來越多的挑戰,如何在這場信息戰中保持清醒和理智,將成為每個網絡使用者必須面對的現實。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。