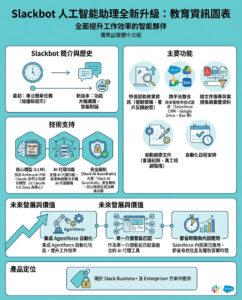
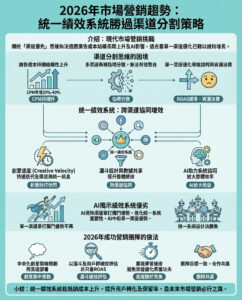
6 個語言模型概念,為初學者解釋
在當今的機器學習領域,了解大型語言模型(LLMs)背後的運作原理至關重要。這些模型影響著從搜索引擎到客戶服務的方方面面,掌握它們的基本知識可以為你打開一扇通往新機會的大門。
因此,我們將以非常易於理解的方式,為你解析一些關於 LLMs 的最重要概念,讓你清楚地了解它們的運作方式及其重要性。
以下是 6 個最重要的 LLM 概念。
1. 語言模型
語言模型是一種算法,根據學習到的模式預測單詞序列。它不僅僅是判斷語法的正確性,而是評估一個序列與人類書寫的自然語言的對齊程度。通過在大量文本上進行訓練,這些模型捕捉了語言的細微差別,生成聽起來像人類的文本。本質上,語言模型只是一種工具,就像任何其他機器學習模型一樣。它旨在組織和利用所學到的龐大信息,在新情境中生成連貫的文本。
2. 斷詞
斷詞是將文本分解為可管理部分的過程,這些部分稱為“標記”。這些標記可以是單詞、子單詞,甚至是單個字符。語言模型基於標記而非整個句子運作,將其作為理解語言的構建塊。有效的斷詞可以提高模型的效率和準確性,特別是在複雜的語言或大型詞彙中。通過將語言轉換為標記,模型可以專注於關鍵信息,使處理和生成文本變得更容易。
3. 單詞嵌入
單詞嵌入將單詞轉換為密集的數字表示,這些表示根據上下文捕捉其含義。通過在向量空間中將具有相似含義的單詞放置得更近,嵌入幫助語言模型理解單詞之間的關係。例如,“國王”和“女王”在這個空間中會靠得很近,因為它們共享上下文相似性。這些嵌入為模型提供了更細緻的方式來解釋語言,使其能夠進行更深層次的理解,並提供更人性化的回應。
4. 注意力機制
注意力機制使模型能夠選擇性地關注文本的特定部分,增強對上下文的理解。由 Transformer 模型引入的注意力,特別是自注意力,允許模型在處理輸入時優先考慮某些單詞或短語。通過動態聚焦,模型能夠捕捉長期依賴性,改善文本生成,這也是為什麼注意力是 GPT 和 BERT 等強大語言模型的核心。
5. Transformer 架構
Transformer 架構通過實現平行處理,徹底改變了語言建模,克服了之前 RNN 和 LSTM 模型依賴於序列數據處理的限制。Transformer 的核心是自注意力機制,這提升了模型處理長序列的能力,學習文本中哪些部分對任務最相關。這種架構成為了最近進步的基礎,如 OpenAI 的 GPT 模型和 Google 的 BERT,為語言模型的性能設定了新標準。
6. 預訓練和微調
語言模型通常首先在大量文本上進行預訓練,以學習基礎語言模式。在預訓練之後,它們會在較小的特定數據集上進行微調,以應對特定任務,如回答問題或分析情感。微調可以被視為教導一位經驗豐富的廚師學習新菜系。這位廚師不是從零開始,而是基於已有的烹飪技能來掌握新菜。類似地,微調利用模型的廣泛語言知識,並對其進行專門化的調整,使其既高效又靈活。
這就是 6 個最重要的 LLM 相關概念,為所有新手解釋清楚。一旦你決定深入學習語言模型,務必查看以下資源:
– 5 個免費課程,幫助你掌握 LLMs
– 7 個 LLM 項目,提升你的機器學習作品集
從這篇文章中,我們可以看到語言模型在當今技術世界中的重要性。隨著人工智能技術的迅速發展,掌握這些概念不僅能幫助開發者提升技能,還能在未來的職場中佔據有利位置。這不僅是學習新技術的過程,更是理解如何利用這些技術創造價值的過程。隨著越來越多的行業開始依賴於語言模型,無論是自動客服還是內容生成,這些知識都將成為未來職業生涯中不可或缺的一部分。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。