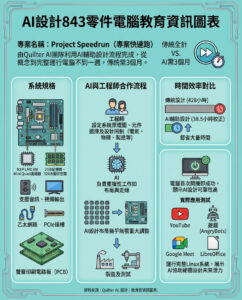
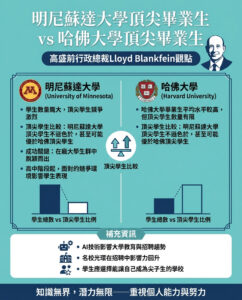
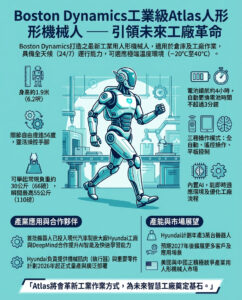
蘋果詳細介紹使用用戶數據的設備內部蘋果智能訓練系統
上個月,蘋果推遲了其更個性化和強大的Siri功能的推出。隨著蘋果致力於未來蘋果智能更新的改進,《彭博社》報導了蘋果在培訓其人工智能模型方面所做的轉變。
報導強調了蘋果機器學習研究網站上的一篇博客文章,解釋了蘋果如何普遍使用合成數據來訓練其AI模型。然而,這種策略也有其局限性,包括合成數據難以理解總結或長句子及整封電子郵件等功能的趨勢。
為了解決這一局限,蘋果強調了一項即將開始使用的新技術,該技術將合成數據與一小部分最近的用戶電子郵件進行比較,但不會侵犯用戶隱私:
「為了改進我們的模型,我們需要生成一組涵蓋消息中最常見主題的電子郵件。為了策劃一組具有代表性的合成電子郵件,我們首先創建一組多主題的合成消息。例如,我們可能會創建一條合成消息:“你明天11:30想去打網球嗎?”」
這一過程不會獲取任何個別用戶的電子郵件信息。然後,我們為每條合成消息生成一個表示,稱為嵌入,該嵌入捕獲消息的一些關鍵維度,如語言、主題和長度。這些嵌入將被發送到少數選擇參與設備分析的用戶設備上。
參與的設備將選擇一小部分最近的用戶電子郵件並計算其嵌入。每個設備然後決定哪個合成嵌入最接近這些樣本。利用差異隱私技術,蘋果可以學習到所有設備中最常選擇的合成嵌入,而不會得知任何特定設備上選擇了哪個合成嵌入。
這些最常選擇的合成嵌入可以用來生成訓練或測試數據,或者我們可以進行額外的策劃步驟來進一步完善數據集。例如,如果有關打網球的消息是最頂尖的嵌入之一,我們可以生成一條將“網球”替換為“足球”或其他運動的相似消息,並將其添加到下一輪策劃的數據集中(見圖1)。這一過程使我們能夠改進合成電子郵件的主題和語言,幫助我們訓練模型以創建更好的文本輸出,例如電子郵件摘要,同時保護用戶隱私。
蘋果解釋說,這些技術使其能夠「理解整體趨勢,而不會獲取任何個體的信息」。根據《彭博社》的報導,蘋果將在未來的iOS 18.5和macOS 15.5測試版中推出這一新系統。
這項技術的推出不僅顯示了蘋果在人工智能領域的堅持和創新,還顯示出其對用戶隱私的重視。在當前數據隱私問題愈發突出的環境中,蘋果能夠在不妥協用戶隱私的前提下,提升其AI的性能,這是一個值得讚揚的做法。未來,這種結合合成數據與用戶數據的方式,或許將成為其他科技公司在AI訓練過程中的一個參考標準。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。