華為Ascend 910C系統多項指標超越Nvidia H100 中國AI硬件實力大爆發

華為Ascend 910C AI晶片系統橫掃Nvidia H100 中國AI硬件實力大突破
華為早前才宣布大規模出貨Ascend 910C AI晶片,填補Nvidia在中國市場的空缺,短短一星期後,華為又有重大突破。據半導體分析機構SemiAnalysis最新分析,華為以Ascend 910C晶片為核心的CloudMatrix 384系統,已在多個關鍵指標上領先Nvidia最新的GB200 NVL72機架系統(該系統以H100 GPU為主力),令全球AI硬件競賽再度升溫。
Nvidia今年初推出的GB200 NVL72,是72顆Blackwell GPU加上36顆Grace CPU的龐大組合,號稱AI運算速度提升30倍,能源效益提升25倍,特別針對大型語言模型推理等高負載工作。

中國AI系統能力首次全面超車Nvidia
SemiAnalysis在4月16日披露,華為CloudMatrix 384系統不僅速度超越Nvidia GB200 NVL72,更標誌著中美科技戰格局的重大轉變。
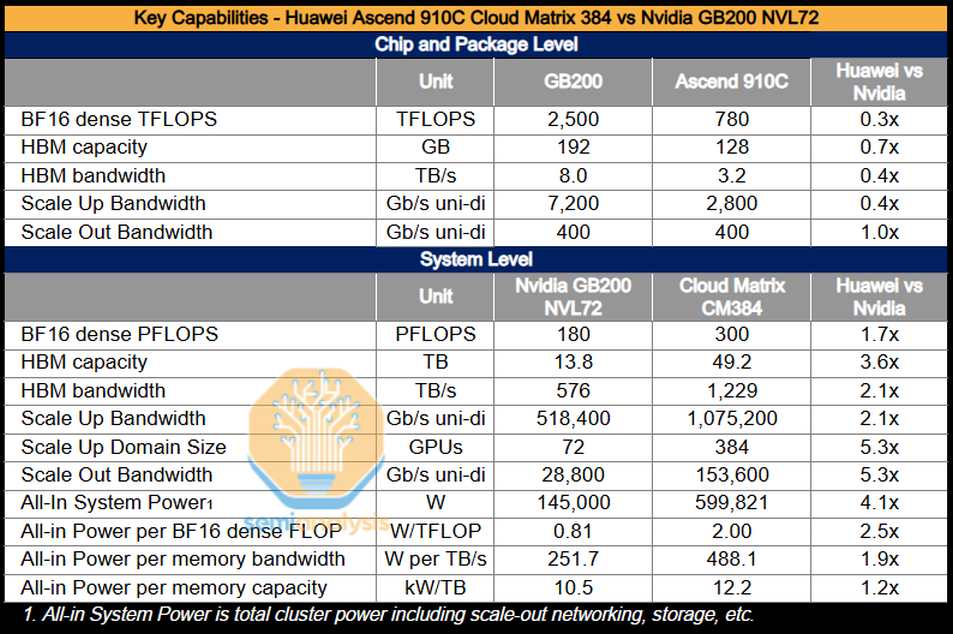
> 「完整CloudMatrix系統現可提供300 PFLOPs的密集BF16運算力,幾乎是GB200 NVL72的兩倍。記憶體總容量高出3.6倍,頻寬高出2.1倍。華為和中國現在擁有可超越Nvidia的AI系統能力。」——SemiAnalysis
值得留意,雖然Ascend晶片可於中芯國際(SMIC)生產,但整體供應鏈仍高度依賴全球,包括來自韓國的HBM記憶體、台積電的晶圓、以及美國、荷蘭、日本的晶片製造設備。SemiAnalysis認為,美國若要遏制中國AI進展,應針對這些供應鏈漏洞加強管控。
華為雖然在晶片製程上落後一代,但在系統層面的設計策略已領先Nvidia及AMD。CloudMatrix 384以全光網絡串聯384顆Ascend 910C,雖然單顆效能僅及Nvidia Blackwell GPU約三分一,但靠規模優勢(多出五倍晶片)成功彌補。
華為下一擊:Ascend 910D即將登場
就在華為CloudMatrix 384表現曝光之際,《華爾街日報》報道華為正準備測試新一代Ascend 910D晶片,劍指Nvidia H100。華為已邀請多間中國科技公司試用,預計5月底有初步樣品,隨即量產,明顯是要打造本土替代方案,填補美國出口管制後的空白。
不過,CNBC在4月28日一度誤將CloudMatrix 384的突破歸功於910D晶片,SemiAnalysis已即時澄清,現時的領先其實來自已量產、並在字節跳動等企業實際運作的910C。
CloudMatrix 384 vs GB200 NVL72 數據對決
CloudMatrix 384並非單靠強勁晶片,而是整套針對兆參數AI模型訓練與推理的系統。當SemiAnalysis將其與Nvidia GB200 NVL72對比,優勢一目了然:
– 運算力:BF16效能達300 petaFLOPs,約為GB200 NVL72的兩倍(後者約150 petaFLOPs)
– 記憶體容量:49.2TB HBM,為GB200的3.6倍(13.8TB HBM3e)
– 記憶體頻寬:1229TB/s,為GB200的2倍多(576TB/s)
這些提升對AI訓練及推理至關重要,意味著科學研究、自動駕駛、生成式AI等領域將有更快迭代。值得一提,CloudMatrix 384能超越GB200 NVL72,自然也能壓倒H100系統(如Nvidia DGX H100,僅8顆H100,16 petaFLOPs)。
但華為也有明顯短板:CloudMatrix 384耗電量是GB200 NVL72的3.9倍,效能每瓦更差2.3倍。換言之,華為靠「蠻力」勝出,Nvidia則在能效上佔優,對大型數據中心來說仍極具吸引力。
晶片型號混亂釐清
由於華為突破消息來得突然,外界一度混淆型號。CNBC曾錯將領先歸功於Ascend 910D,但事實上910D仍在測試,真正帶來突破的是910C。單顆晶片比較,Nvidia H100依然強於910C(H100 FP8效能4 petaFLOPs,頻寬3.35TB/s;910C FP16效能2.4 petaFLOPs,約為H100的六成)。華為的優勢來自系統規模與高速光網絡連接,單靠910C本身並無優勢。
制裁下的突圍
華為的成功不只是技術突破,更是制裁下的生存與創新。自2019年被美國列入黑名單後,華為無法直接取得台積電先進製程和高端記憶體,但透過第三方(如Sophgo)間接用上台積電7nm製程,並以中間商取得三星HBM2E記憶體(雖然落後Nvidia兩代)。與此同時,美國對Nvidia出口中國的限制愈收愈緊,連降級版H20都被禁,Nvidia估計因此損失55億美元。
華為則乘勢而上,計劃2025年出貨約100萬顆910C晶片,滿足中國爆炸性AI需求。消息一出,Nvidia股價即跌2%,投資者對這場科技戰極為敏感。
華為仍面對三大難關
即使華為在效能上大幅領先,未來仍有三大挑戰:
– 電力消耗極高,數據中心運營成本大增
– 晶片製程仍用7nm,記憶體落後兩代,技術差距明顯
– 軟件生態遠遜Nvidia CUDA,AI開發者習慣難以轉移
Ascend 910D會否扭轉單顆效能劣勢,仍待觀察。但現階段,華為靠910C與CloudMatrix 384的系統設計,已成Nvidia最強勁對手。
這場戰爭已不只是拼晶片,而是比誰能建構更大規模、更高效能、更能適應地緣政治壓力的AI系統。
編輯評論:中美AI硬件戰進入新階段 「蠻力」vs「效率」的選擇題
華為CloudMatrix 384的橫空出世,標誌著中國AI硬件已不再只是追趕,而是開始在某些系統層面主動出擊。華為用「堆積木」式的系統工程,硬生生靠規模壓倒了Nvidia的單晶片性能優勢,這種策略對於被科技封鎖的中國來說,是極具啟發性的突圍之道。
但這種「蠻力」模式是否可持續?高達3.9倍的能耗,對中國本已緊張的能源結構來說,會否成為發展AI產業的最大瓶頸?而華為的軟件生態、開發者社群能否追上CUDA,這些都將直接影響中國AI產業的全球競爭力。
更深層的問題是,這場中美AI硬件戰,已經從「技術領先」變成「供應鏈博弈」——誰能在全球供應鏈碎片化的情況下,保持產品迭代和規模優勢,誰就能在新一輪AI革命中站穩腳步。華為的做法,或許為其他被制裁國家提供了一條「系統整合」的生存路徑,但這條路能走多遠,還要看中國能否在基礎科研、軟件生態、能源結構等多方面同步突破。
對香港及亞洲科技圈來說,這是一個值得深思的信號:未來的AI硬件霸權,或許不再是單一公司、單一國家的專利,而是全球供應鏈、系統工程與政策博弈的綜合體。你又如何看待這場「蠻力」與「效率」之爭?