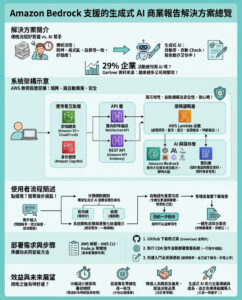
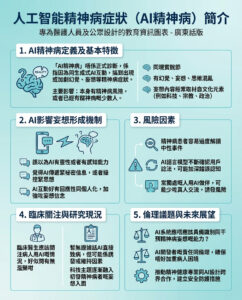
Auto-RAG:一個以LLM決策能力為核心的自主迭代檢索模型
檢索增強生成(Retrieval Augmented Generation, RAG)是一種高效的解決方案,適用於知識密集型任務,能夠提高輸出的質量並使其更具確定性,並且減少幻覺現象。然而,RAG的輸出仍然可能雜亂,並且在面對複雜查詢時可能無法作出適當的回應。為了解決這一局限性,研究人員引入了迭代檢索更新,這種方法更新了重新檢索的結果,以滿足動態的信息需求。主要是為了解決知識稀疏性和在複雜查詢解決過程中的需求,重點在於兩個W——何時(When)和什麼(What)需要檢索。儘管有潛力,但現有的大多數方法仍然過於依賴以人為導向的規則和提示,這種依賴需要大量的人力,限制了大型語言模型(LLMs)的決策能力,實際上是對它們進行“餵養”,而非賦予自主性。
為了克服這些挑戰,中國科學院的研究團隊提出了Auto-RAG,一個自主的迭代檢索增強系統,重點在於LLM的決策能力。該系統包括LLM與檢索器之間的多輪對話。與傳統結果相比,Auto-RAG利用LLM的推理能力進行計劃、知識提取、查詢重寫,並不斷查詢檢索器,直到向用戶提供所需的解決方案。Auto-RAG引入了一個自動合成基於推理的指令的框架,使LLMs能夠在迭代RAG過程中獨立做出決策。這些指令允許在迭代RAG過程中以最小成本自動化LLM的決策。
作者將這一迭代過程概念化為LLM與檢索器之間的多輪互動,直到檢索器對信息的充分性有信心。每次迭代後,模型進行推理並調整檢索方法,以尋找適當的信息。該流程的核心部分無疑是推理部分。作者添加了三個不同的推理點,構成了一個檢索的思考鏈(Chain of Thought)。
檢索規劃:這是第一步,專注於與查詢相關的初步數據檢索。這一階段還包括評估模型是否需要更多的檢索,或者獲得的信息是否已經足夠。
信息提取:第二步使信息更具查詢特異性。在此步驟中,LLM從檢索的文檔中提取相關信息,以便最終答案的整理。這包括對關鍵信息的總結方法,以減少不準確性。
答案推理:該流程的最後一步包括LLM根據提取的信息形成最終決策。
此外,AutoRAG具有高度的動態性,因為它會根據查詢的複雜性自動調整迭代次數,省卻了計算的麻煩。這一框架的另一個優勢在於其用戶友好,並以自然語言編寫,提供了高程度的可解釋性。現在我們已經討論了Auto-RAG的功能及其對改善模型性能的重要性,接下來讓我們看看這一流程在實際測試中的表現。
研究團隊在監督環境下對LLMs進行微調,以實現自主檢索。他們為此從兩個數據集(Natural Questions和2WikiMultihopQA)中合成了10,000個基於推理的指令。該流程中使用的模型包括Llama-3-8B-Instruct(用於推理合成)和Qwen1.5-32B-Chat(用於重寫查詢)。數據在Llama模型上進行微調,以提高其無人干預的檢索效率。
為了測試所提方法的有效性,作者在六個代表性基準上對Auto-RAG框架進行了基準測試,這些基準涉及開放域和多跳回答數據集。多跳問答有多個子部分和多個查詢,使得應用標準RAG方法效率低下。結果驗證了Auto-RAG的主張,在數據受限的訓練中取得了良好的結果。選擇了一種無需管道的零-shot提示方法作為RAG的基準。作者還將Auto-RAG與一些多鏈接和基於思考鏈的方法進行比較,結果顯示Auto-RAG超越了其他模型。
結論:Auto-RAG在六個基準上通過自動化多步檢索過程任務並增強傳統RAG設置中的推理能力而達到了卓越的表現。它不僅提供了更好的結果,還在檢索過程中自我調整查詢,直到獲得所需的信息。
這項研究展示了如何通過技術的創新來提升大型語言模型的自主性和效率,這對未來的AI應用具有深遠的影響。Auto-RAG不僅是對現有技術的改進,更是推動了AI在知識檢索領域的發展。隨著這類技術的成熟,我們有理由相信,未來的AI系統將能更好地滿足用戶的需求,並提供更準確的答案。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。