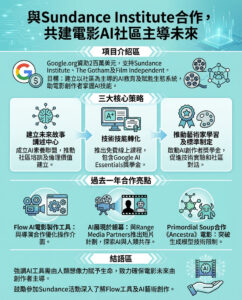
小型語言模型的興起:大型語言模型的替代品?
小型語言模型(SLMs)被預測將在2025年成為智能服務的下一代引擎,並以更低的成本提供類似的功能。根據分析師的觀察,2024年是大型語言模型(LLMs)的時代,而2025年將是我們重新思考規模的時刻。儘管SLMs在規模和複雜性上無法與一些擁有數萬億參數的LLMs相提並論,但SLMs的成本更低、效率更高、訓練速度更快,且部署更為簡便。SLMs的參數範圍從幾百萬到幾十億不等,這些模型本質上與其他生成AI神經網絡模型相同,只是相對較小。
SLMs的設計目的是供企業用於不需要大量數據的小型專門任務,例如針對特定產品的客戶支持聊天機器人或分析市場趨勢的模型。在某些情況下,內部數據是敏感的,需要保留在公司內部,例如金融或醫療行業。Couchbase的AI和邊緣計算副總裁Mohan Varthakavi指出:“它們適合資源受限的環境,並且適合用於無法容納大型模型的設備上,對於實現移動和邊緣設備的AI至關重要。”
自2022年11月OpenAI推出ChatGPT以來,企業和消費者對LLMs的承諾感到著迷。科技公司隨之開發出更大更好的模型,企業則利用這些工具改善客戶服務、更好地管理工作流程和增強人類專業知識。根據國際數據公司(IDC)的數據,全球企業對生成AI解決方案的支出預計將從2023年的160億美元增長到2027年的1500億美元。
儘管LLMs的魅力不會輕易褪色,但分析師們也開始認識到其缺點,並對其他選擇持開放態度。最近幾個月,微軟、Meta、谷歌和法國初創公司Mistral都推出了僅有幾十億參數的SLMs。我們還看到AI PC的推出,這些計算機內置神經處理單元,適合運行自家的小型語言模型。
SLMs的優勢
隨著思維的變化,LLMs可能是處理複雜或開放式任務的最佳選擇,但它們的成本也相對較高,且有時甚至是不可承受的,並且難以監控和維護。此外,訓練這些模型需要大量的計算能力,並伴隨相應的碳足跡。開發擁有1750億參數的GPT-3的過程中,估計產生了552噸二氧化碳,相當於一百多輛汽車的年排放量。
芝加哥大學布斯商學院的會計助理教授Bradford Levy指出,“Meta的最大模型Llama 3.1有4050億參數,訓練這個模型花費了超過50天,使用了16000個圖形處理單元(GPUs),這是巨大的計算量。”如果GPU出現故障,可能會延遲或完全停止整個訓練過程。這在使用八個或24個GPU訓練模型時則不會成為考慮的問題。
數據安全問題也是一個重要考量。許多企業擔心隱私問題,對使用供應商的雲數據中心感到不安,但又沒有足夠的資源在現場部署LLM。SLM則可以輕鬆地在內部托管,減輕他們的顧慮。
此外,LLMs經常出現的錯誤輸出(即“幻覺”)問題也是一大挑戰。IBM研究歐洲UK及愛爾蘭部門的總監Juan Bernabe Moreno表示:“一些研究指出,模型越大,管理幻覺的難度越大。但如果模型較小,則更易於控制,更透明,也更容易信任。”
局限性與取捨
從性能的角度來看,SLMs可能會在結果的完整性和相關性方面無法與較大的模型競爭。Moreno指出:“如果你將一個小型語言模型與一個非常大型的語言模型進行比較,性能可能仍然會偏向較大的模型。”
不過,“小”是相對的。當前版本的SLMs的參數數量往往與較舊的LLMs相似。而最近的研究表明,最佳的SLMs在專門任務上實際上可以超越較大的模型。
例如,在法律領域,一個只有2億參數的小型SLM在識別用戶協議中的不公平條款方面超越了擁有1.8萬億參數的GPT-4。UiPath的AI策略負責人Ed Challis指出:“SLMs在處理行業特定術語和查詢方面表現更佳,且由於其專門的訓練,錯誤率較低。”
許多分析師認為,性能問題需要與其他同樣重要的因素權衡。“在很多情況下,也許LLM的性能提高了1%或2%,但客戶真的在意這一點嗎?”Levy辯稱,“如果托管成本高出10倍,而客戶滿意度並沒有太大差異,那麼為什麼還要選擇這條路呢?”
一般來說,某一模型的適用性將取決於所選用例。如果你希望讓你的模型接觸大量數據,從而形成一個通用的AI,可能最好還是選擇LLM。反之,如果你希望滿足特定的業務需求,SLM則可能足夠。Finastra的首席AI官Adam Lieberman警告道:“如果你的數據集不夠健全或全面,則模型的性能可能會受到影響,可能會導致一些不準確的輸出或偏見結果。”
未來的發展
總的來說,SLMs並不是萬能的解決方案,也不會很快取代企業的LLMs。根據Gartner的預測,SLMs的增長速度快於市場的其他部分,未來幾年其部署預計將翻倍或三倍增長。然而,它們仍然將是少數,大多數企業僅將這些工具作為更廣泛組合的一部分來部署。
Couchbase的Varthakavi認為,許多企業將會採取混合方法。“我們可能會看到許多用例,其中LLMs和SLMs相輔相成——LLMs提供一般基礎數據,而SLMs提供特定領域的數據。”
而Gartner的Valdes則對它們的協同工作持悲觀態度。他認為,企業將採用許多來源不同的系統,這將導致他所稱的“生成AI的擴張”。他表示:“結果並不美觀,但這將是未來幾年的現實。當前的重要任務是確保組織能從這個無序且不穩定的生態系統中獲得價值和利益。”
Valdes認為,整合將在未來某個時刻出現。在此期間,企業應該採取非常謹慎的生成AI策略。如果過去幾年以實驗為特徵,嘗試不同的可能性並觀察結果,那麼2025年可能是確立策略的一年。IBM的Moreno認為,SLMs應該是這一策略的重要組成部分。
他解釋道:“它們提供了以一種能區分你的業務的方式整合你自己的數據的可能性。否則,企業僅使用通用模型,因為其他公司也可以這樣做。我們希望使AI創作者能夠使用生成AI來獲得競爭優勢。”
總之,選擇任何模型時,理解業務需求至關重要。在生成AI中,規模並非一切,但有意識地使用可能更為重要。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。