教你點用LlamaIndex同OpenAI打造自我評估嘅Agentic AI系統
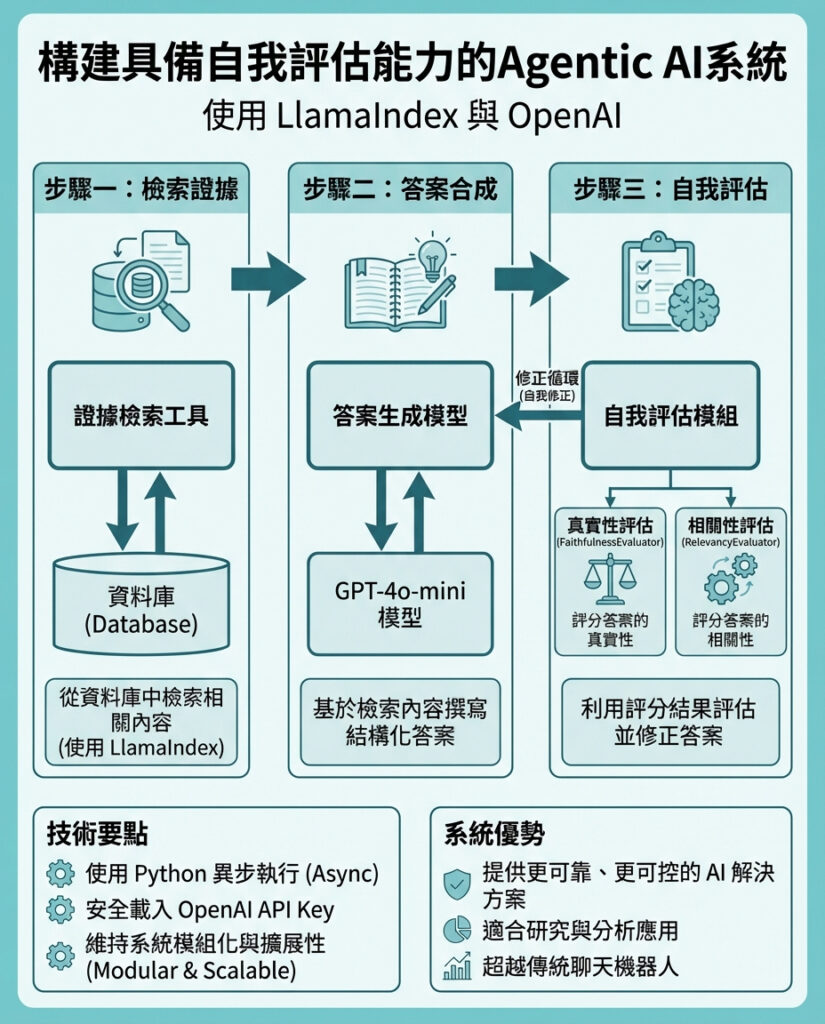
今次教學示範點樣用LlamaIndex同OpenAI模型,建立一個先進嘅agentic AI工作流程。我哋重點設計一個可靠嘅檢索增強生成(RAG)代理,佢唔單止能夠根據證據推理,仲會有意識咁使用工具,並且自我評估輸出嘅質素。透過有系統咁將檢索、答案合成同自我評估結合,展示agentic模式點樣超越簡單嘅聊天機械人,朝向更可信、可控嘅AI系統,適合用於研究同分析場景。
首先,我哋安裝同設定必要嘅環境依賴,同時喺運行時安全地輸入OpenAI API金鑰,避免硬編碼憑證,並且準備好處理異步執行。
接住,設定OpenAI語言模型同嵌入模型,建立一個簡潔嘅知識庫。將原始文字轉換成索引文件,方便代理喺推理時檢索相關證據。
我哋定義兩個核心工具:證據檢索同答案評分。自動化計算答案嘅真實性同相關性分數,令代理可以判斷自己回應嘅質量。
然後,利用ReAct架構創建代理,定義其系統行為,指導佢點先檢索證據,後產生結構化答案,再評估並在分數較低時修正。初始化執行上下文,保持代理狀態,整合工具同推理,形成完整嘅agentic工作流程。
最後,透過異步方式執行整個代理循環,輸入主題,並實時輸出代理嘅推理過程同結果,完成檢索、生成同自我評估。
總結嚟講,我哋示範咗點樣令代理喺回答前,先檢索支持證據,再生成結構化答案,最後自我評估真實性同相關性。設計保持模組化同透明,方便未來加入更多工具、評估器或專業知識來源。呢個方法展示咗點樣用LlamaIndex同OpenAI模型構建更有能力、同時更可靠、自覺推理嘅agentic AI系統。
—
評論與啟示
呢篇教學好清楚展示agentic AI嘅核心價值:唔係簡單嘅對話機械人,而係具備「思考-檢索-評估-修正」能力嘅智能體。呢種設計令AI嘅回答更有根據,減少幻覺(hallucination)現象,提升回應嘅可信度。尤其係結合自我評估機制,係向自我監控AI邁進嘅重要一步。
喺現時AI應用日益廣泛嘅情況下,如何確保AI回應既準確又有理據,係業界同用戶最關注嘅問題。教學中以模組化設計,方便未來擴展,反映出實務中靈活應用嘅思維。無論係科研、法律、醫療等需要嚴謹推理嘅領域,都有巨大潛力。
不過,依家依然要面對嘅挑戰,包括檢索資料嘅完整性、評估標準嘅多元化同自我評估嘅準確性。從長遠睇,agentic AI若能結合更多領域專家知識及即時數據更新,未來可望成為真正可信賴嘅智能助理。
最後,呢種結合檢索同生成嘅agentic AI架構,亦啟發我哋思考人機協作新模式:AI唔係單向答題,而係一個能夠自省、自我修正嘅「合作夥伴」,為用戶提供更高質素嘅智能服務。香港本地同其他華語市場亦可借鑒呢種設計理念,推動人工智能技術更貼近實際應用需求。
以上文章由GPT 所翻譯及撰寫。而圖片則由GEMINI根據內容自動生成。