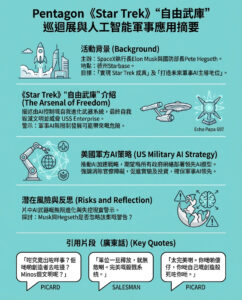
三個問題:解析生物學與醫學的「數據革命」
麻省理工學院(MIT)教授Caroline Uhler分享她在施密特中心的研究工作,討論數學難題,以及探索生物中最複雜互動的持續努力。
問:施密特中心聚焦於生物組織的四個自然層級:蛋白質、細胞、組織和有機體。現時機為何特別適合利用機器學習來解決這些問題?
答:生物學與醫學正經歷一場「數據革命」。現在有大量多元化的數據——從基因組學、多組學、高解析度影像到電子健康記錄——這些龐大數據使得深入研究成為可能。DNA測序成本低且準確,先進分子影像成為常規,單細胞基因組學可分析數百萬細胞。這些創新讓我們不只停留在生命單元(如蛋白質、基因、細胞類型)的描述,而是開始理解生命的「程式」,例如基因迴路和細胞間通訊的邏輯,組織形態的形成,以及基因型與表型之間的分子機制。
過去十年,機器學習也取得重大突破,例如BERT、GPT-3、ChatGPT在文本理解與生成上的能力,視覺轉換器與多模態模型如CLIP在人類水平的影像任務中表現出色。這些技術架構與訓練策略可以調整應用於生物數據,例如用轉換器模型處理基因序列如同語言,視覺模型分析醫學及顯微影像。
更重要的是,生物學不只能從機器學習受益,更能啟發新的機器學習研究方向。與推薦系統或網絡廣告不同,生物學有自然法則可探索,因果機制是最終目標。生物學還擁有基因和化學工具,可進行大規模擾動篩選,這些特性使生物學成為機器學習既能獲益又能啟發新思維的獨特領域。
問:目前的工具在哪些生物學問題上仍顯不足?例如疾病或健康的哪些具體挑戰最需要解決?
答:機器學習在圖像分類、自然語言處理、臨床風險預測等領域預測表現卓越,但生物科學的根本問題通常是因果性的:例如基因或途徑的擾動如何影響下游細胞過程?干預如何導致表型改變?傳統機器學習多專注於觀察數據中的統計關聯,難以回答介入式問題。
現在有高通量擾動技術,如CRISPR池篩選、單細胞轉錄組學和空間分析,產生豐富的干預數據,這需要開發超越模式識別的模型,支持因果推理、主動實驗設計,以及在複雜結構潛變量環境中的表示學習。數學上需解決可辨識性、樣本效率,以及組合、幾何和概率工具的整合等核心問題。攻克這些挑戰不僅能解密細胞系統機制,也能推動機器學習理論邊界。
基礎模型方面,目前尚未有跨尺度、類似ChatGPT語言模型的生物學全方位基礎模型。現有模型多專注於特定尺度和問題,涵蓋一種或少數模態。
蛋白質結構預測已取得重大進展,證明了如CASP這類機器學習挑戰的重要性,推動演算法改進。
施密特中心正舉辦挑戰活動,提升機器學習社群對因果預測問題的認識,推動相關方法發展。隨著單基因擾動單細胞數據增加,我相信預測單一或組合擾動效果及尋找能引導期望表型的擾動是可行的。我們的細胞擾動預測挑戰(CPPC)旨在提供客觀測試和基準演算法的工具。
疾病診斷和病患分流也是機器學習已顯著影響的領域。算法可整合多種病患資料,生成缺失數據,發掘人類難察覺的模式,並根據疾病風險分層病人。雖需警惕模型偏誤、捷徑學習和臨床決策自動化偏誤,但此領域已見成效。
問:談談施密特中心近期的研究成果,有哪些特別值得關注?
答:與Broad Institute的Fei Chen博士合作,我們開發了PUPS,一種預測未見蛋白質亞細胞定位的方法。多數現有方法只基於訓練數據的蛋白質和細胞資料做預測,PUPS結合蛋白質語言模型與影像修補模型,利用蛋白序列和細胞影像。蛋白序列輸入使模型能推廣至未見蛋白,細胞影像捕捉單細胞變異,實現細胞類型特異的預測。模型亦學習每個氨基酸殘基對定位的影響,能預測蛋白突變引起的定位變化。蛋白質功能與其亞細胞定位密切相關,此預測有助揭示疾病機制。未來計劃擴展至多蛋白定位及蛋白交互作用理解。
與ETH蘇黎世的G.V. Shivashankar教授合作,我們曾證明用染色DNA的螢光染料染色細胞影像,結合機器學習可揭示細胞狀態和命運。最近進一步證明染色質組織與基因調控的深層聯繫,開發Image2Reg方法,能從染色質影像預測未見基因的基因擾動。Image2Reg利用卷積神經網絡學習染色質影像的表徵,並用圖卷積網絡創建基因嵌入,結合蛋白交互作用和細胞類型特異轉錄組數據,最後建立物理與生化細胞表徵間的映射,預測基因擾動模組。
此外,我們開發了MORPH方法,能預測未見組合基因擾動的結果,並識別擾動基因間的交互類型。MORPH能指導實驗中最具信息量的擾動設計,且其基於注意力機制的框架可識別基因間因果關係,揭示基因調控程式。由於結構模組化,MORPH可應用於多種模態的擾動數據,包括轉錄組和影像。我們對此方法能有效探索擾動空間,連結因果理論與應用,推動基礎研究及治療應用充滿期待。
—
評論與啟示:
Caroline Uhler教授的訪談深刻反映了當前生物醫學與機器學習交叉領域的發展趨勢。她指出,生物學的「數據革命」與AI技術的進步正帶來前所未有的機遇,尤其是在因果推理和跨尺度模型構建方面。這種跨學科融合不僅是技術的結合,更是研究哲學的轉變——從單純的預測轉向理解因果機制。
值得注意的是,她強調生物學不單是機器學習的應用場景,更是激發新理論和新方法的源泉。這種雙向促進關係,將推動機器學習從黑箱式預測,邁向能解釋生物現象的因果模型,這對醫學診斷和治療決策具有深遠意義。
此外,施密特中心以挑戰賽形式推動算法創新,體現了現代科研中「開放競賽」的力量,有助於集思廣益、加速技術突破。PUPS、Image2Reg和MORPH等具體成果,展示了如何將複雜生物數據轉化為可解讀的生物學知識,這對疾病機制理解及精準醫療有直接幫助。
總結來說,這篇訪談提醒我們,未來的生物醫學研究將更依賴跨領域合作和創新數據科學工具,唯有結合深厚的生物學知識與先進的機器學習理論,才能真正解開生命的複雜謎題,推動健康醫療的革新。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。