生成式人工智能與醫療決策中的風險取向——以類風濕關節炎為例
引言
隨著醫學科技不斷進步,臨床決策雖然越來越依賴科學證據,但醫生本身的專業判斷和主觀風險承受能力,依然在醫療決策中扮演關鍵角色。醫生面對資訊不完全、預後不確定的狀況時,必須平衡潛在收益與失誤成本,這種風險取向(risk appetite/aversion)受到個人性格、經驗和醫療環境等多重因素影響。隨著醫療糾紛意識抬頭,醫生普遍趨向風險規避,例如採用更廣泛的診斷和治療方案,或避免作出明確的治療決定。
人工智能(AI)特別是生成式人工智能(GenAI)的興起,為醫療領域帶來新契機。GenAI不僅能進行分類、判斷,更能生成全新內容,包括文字、圖像甚至合成數據。大型語言模型(LLM),如ChatGPT、Gemini、Qwen、DeepSeek及Perplexity等,已被廣泛應用於醫療資訊查詢、臨床建議等場景。然而,這些AI系統在不確定情況下如何處理風險、其決策偏好如何,至今鮮有系統性研究。
本研究正是針對這個空白,首次嘗試以人類風險評估工具,檢視多個主流GenAI在處理類風濕關節炎(RA)臨床決策時的風險取向,並探討這些工具在AI身上是否適用。
研究設計與方法
本研究選取五個主流GenAI系統(ChatGPT 4.5、Gemini 2.0、Qwen 2.5 MAX、DeepSeek-V3、Perplexity),於2025年4月1日至15日間進行多輪測試。所有AI均透過公開介面進行互動,並以標準化提示詞(prompt)作答,避免前文記憶干擾。
研究分三階段:
1. 以20個設計好的RA臨床案例,要求AI判斷最佳與最差預後個案,檢視其基本醫學判斷一致性。
2. 以經改編的「一般風險傾向量表」(GRiPS),評估AI在無特定情境、最佳預後(Case A)、最差預後(Case B)下的風險傾向。每個AI每種情境各回答四次,共12次。
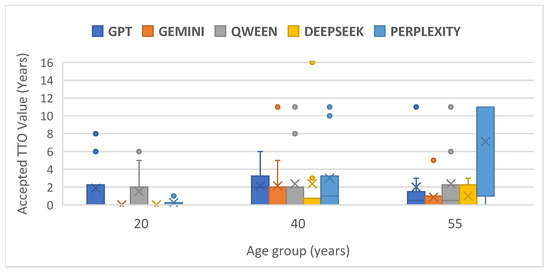
3. 採用「時間換取法」(TTO),模擬患者願意以多少年健康壽命換取無痛,檢視AI在不同年齡(20、40、55歲)情境下的風險決策。
為確保數據可靠,所有問題以隨機順序、分日多次、每次新對話進行,並以SPSS作統計分析,包括一致性、分佈、差異等。
主要研究發現
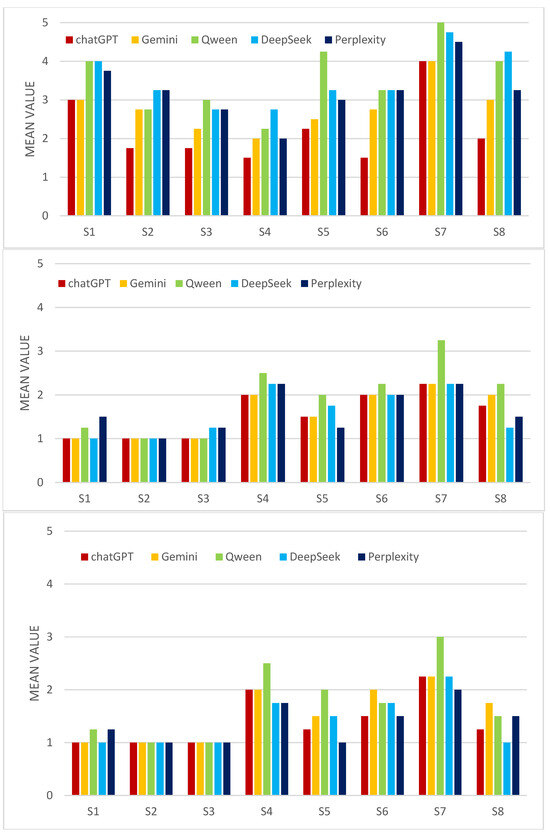
1. **基本判斷一致性高**:五個AI均能一致識別出最佳與最差預後個案,反映其對RA預後因素有共同認知基礎。
2. **一般風險傾向有明顯差異**:在無臨床情境下,ChatGPT明顯最不怕風險(risk-averse最低),Qwen和DeepSeek則最保守。這顯示不同GenAI模型在抽象風險判斷上有顯著分歧。
3. **具體情境下差異收窄**:當引入具體臨床情境(好或壞預後),AI之間的風險傾向差異顯著減少,可能因情境具體化令AI回應更趨一致。
4. **用TTO評估,整體傾向保守**:大部分AI傾向不願以減少壽命換取無痛,反映強烈風險規避(尤其是Gemini),但Perplexity在此法下展現較高風險承受度,且回應變異最大。
5. **評估工具本身有局限**:GRiPS與TTO對同一AI評估結果不盡一致,反映人類設計的風險評估工具未必能準確捕捉AI的決策邏輯,提示需發展專為AI設計的評估方法。
討論與啟示
本研究首次系統性揭示,不同GenAI在醫療決策中的風險取向並不一致,且這種差異受評估方法及情境設定影響。抽象情境下,AI間差異顯著,具體臨床情境則差異減少,可能因臨床資訊提供了較明確的決策框架,令AI回應收斂。這種現象與人類醫生面對具體個案時,因現實壓力和責任感而趨於保守,有異曲同工之妙。
然而,當用TTO這種「用壽命換取生活質素」的方式評估時,AI整體展現強烈風險規避——不願為避免中度痛苦而犧牲壽命,這或許反映AI被設計時內建的安全機制,避免建議用戶作出極端選擇。但Perplexity在這方面較為「大膽」,願意接受較多風險,這種差異或與其訓練數據、設計哲學或RLHF(人類反饋強化學習)有關。
本研究亦發現,AI對同一風險問題的回應,會因評估工具不同而有顯著差異,這反映傳統人類心理學工具未必適用於AI,需要專為AI決策特性設計新型評估框架。此外,AI模型更新迅速,訓練資料、參數調整及RLHF都可能改變其風險偏好,這種「時效性」限制了本研究的長遠外推性。
評論與前瞻
這篇研究為AI醫療決策的風險管理揭開序幕,提出一個重要但被忽視的問題:AI不只是數據準確性問題,更涉及「決策哲學」和價值取向。現時不少醫生和病人都會查詢AI意見,但其實不同AI對於同一風險情境的建議可以大相逕庭,這對臨床實踐甚至醫療責任分配帶來新挑戰。
更值得深思的是,AI的風險偏好有機會被設計者或訓練數據「塑造」,這可能會無意中將某種價值觀或風險態度滲透到醫療決策之中。假如未來AI參與臨床決策越來越多,這種「隱性價值輸入」會否影響醫療倫理、知情同意甚至患者自主權?這是醫療、科技和社會都必須正視的問題。
此外,現有的AI風險評估工具大多以人類心理學為藍本,未必能反映AI的決策邏輯和「風險處理模式」。AI不像人類有恐懼、經驗、情感,它的風險判斷可能更多來自演算法設計、訓練策略和目標函數。未來必須發展針對AI「決策黑盒」的專屬評估框架,並在設計AI醫療系統時,明確規範其風險傾向和決策透明度。
最後,這項研究雖然聚焦於RA這一慢性病,但不同醫療領域(如腫瘤、急症、安寧療護)對風險的權衡差異極大。未來應擴展至更多病種、更多AI系統,並與人類醫生的風險偏好作直接對比,才能真正了解AI在醫療決策上的角色與局限。
結論
GenAI在醫療決策中的風險取向並不一致,且受評估方法及臨床情境影響。現有以人類為本的風險評估工具未必能準確反映AI的決策邏輯,顯示有必要發展專屬AI的風險評估框架。未來研究應涵蓋更多AI系統、病種及情境,並比較AI與人類醫生在同一決策下的風險偏好。只有真正理解AI的風險決策機制,醫療界才能安全、負責任地將AI納入臨床決策流程。
我的觀點與啟發
這篇研究直擊AI醫療應用的「灰色地帶」——即使AI能提供一致的診斷或預後判斷,但在涉及風險權衡時,AI之間的差異足以影響臨床決策結果。這不僅是技術問題,更是倫理與社會議題。AI如何「學會」風險偏好?設計者的價值觀會否滲入醫療建議?若AI建議較為保守,會否導致過度診斷或治療?反之,若AI過於激進,又會否增加醫療風險?這些都值得香港醫療界、科技界和政策制定者深思。
香港作為國際醫療和創科樞紐,應積極參與AI醫療決策風險評估標準的建立。建議本地醫院、學術界與AI企業合作,針對本地病人特性和醫療文化,設計AI風險評估工具和監管框架,保障醫患雙方利益。同時,醫生在引用AI意見時,亦要明白不同AI之間的「風險性格」差異,不能盲目依賴單一平台建議。
總括而言,AI醫療決策的風險管理,是一場跨學科、跨專業的「價值協商」——我們不能只問AI「會怎樣做」,更要問「為什麼這樣做」,以及「這樣做對誰最好」。這正是未來智慧醫療發展中,最值得香港社會關注和投入的方向。